- 长臂猿-企业应用及系统软件平台
机器之心编辑部




 图三:SIM 中 GSU 和 ESU 的不一致
图三:SIM 中 GSU 和 ESU 的不一致
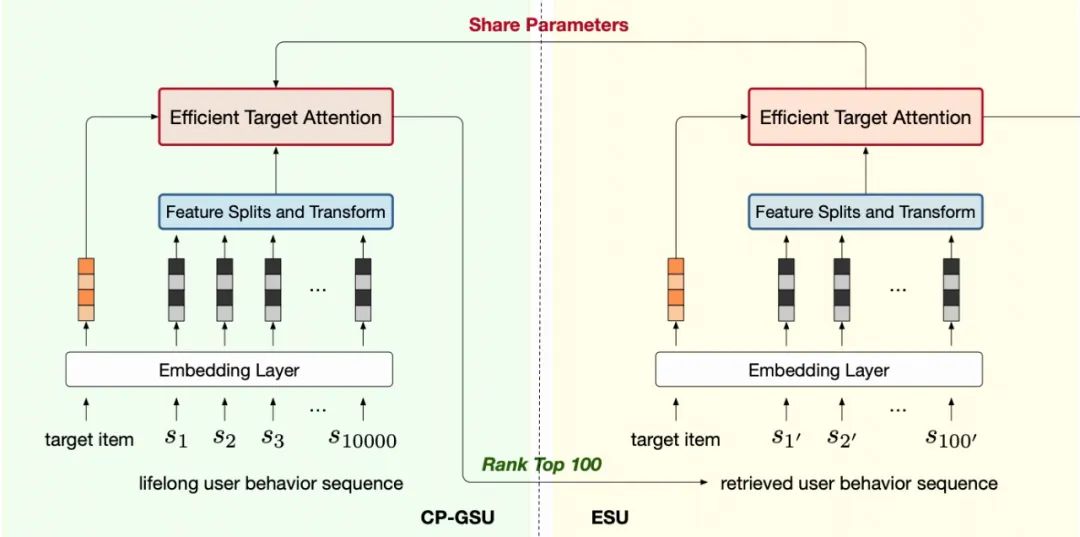 图四:TWIN,两阶段一致的网络结构
图四:TWIN,两阶段一致的网络结构

 表示序列长度,
表示序列长度, 表示 embedding 维度)
表示 embedding 维度) (inherent features),即该视频的与 user 行为无关的自有属性,例如视频的作者、时长、分类、video id 等。
(inherent features),即该视频的与 user 行为无关的自有属性,例如视频的作者、时长、分类、video id 等。 (user-item cross features),即特定 user 与 item 交互而产生的属性,例如用户的观看时长,用户的点赞反馈,观看时间戳等。
(user-item cross features),即特定 user 与 item 交互而产生的属性,例如用户的观看时长,用户的点赞反馈,观看时间戳等。 ,是跨用户行为系列共享的。即同一个 video id 对应下,即使在不同的用户序列里,
,是跨用户行为系列共享的。即同一个 video id 对应下,即使在不同的用户序列里, 相应行也是完全相等的。所以,加上必要的预计算 - 缓存策略,固有特征的线性映射
相应行也是完全相等的。所以,加上必要的预计算 - 缓存策略,固有特征的线性映射 可以转换为高效的,查表 - 整合步骤。
可以转换为高效的,查表 - 整合步骤。 ,因为跨用户行为序列不共享,且每个用户与每个视频最多只交互一次,以上策略行不通,所以我们采用维度压缩的方式减少计算量。
,因为跨用户行为序列不共享,且每个用户与每个视频最多只交互一次,以上策略行不通,所以我们采用维度压缩的方式减少计算量。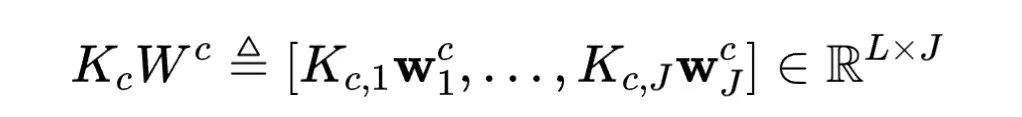
 个交叉特征的每一个,我们都把 embedding 通过线性变换压缩到维度为 1. 如图五所示。
个交叉特征的每一个,我们都把 embedding 通过线性变换压缩到维度为 1. 如图五所示。 图五:特征拆分与线性映射
图五:特征拆分与线性映射

 涉及到 1 万到 10 万个行为序列的线性变换,虽然计算量大,但是却可以通过预计算 - 查表的方式加速。
涉及到 1 万到 10 万个行为序列的线性变换,虽然计算量大,但是却可以通过预计算 - 查表的方式加速。 经过维度压缩后,计算量较小,可以实时计算。由于 query 中没有交叉属性,所以此项以 bias 项形式添加进来,
经过维度压缩后,计算量较小,可以实时计算。由于 query 中没有交叉属性,所以此项以 bias 项形式添加进来, 是一个可学习的权重,表示各个 bias 项的相对重要性。
是一个可学习的权重,表示各个 bias 项的相对重要性。 是 query 的线性变换,即 target video 的 embedding,计算量极小,与序列长度无关。
是 query 的线性变换,即 target video 的 embedding,计算量极小,与序列长度无关。
 项只剩下 100 维度,所以我们采用实时计算的方式获取
项只剩下 100 维度,所以我们采用实时计算的方式获取 。并计算 V 的加权均值:
。并计算 V 的加权均值:
 仍然只有 100 个行为,可以实时地计算。
仍然只有 100 个行为,可以实时地计算。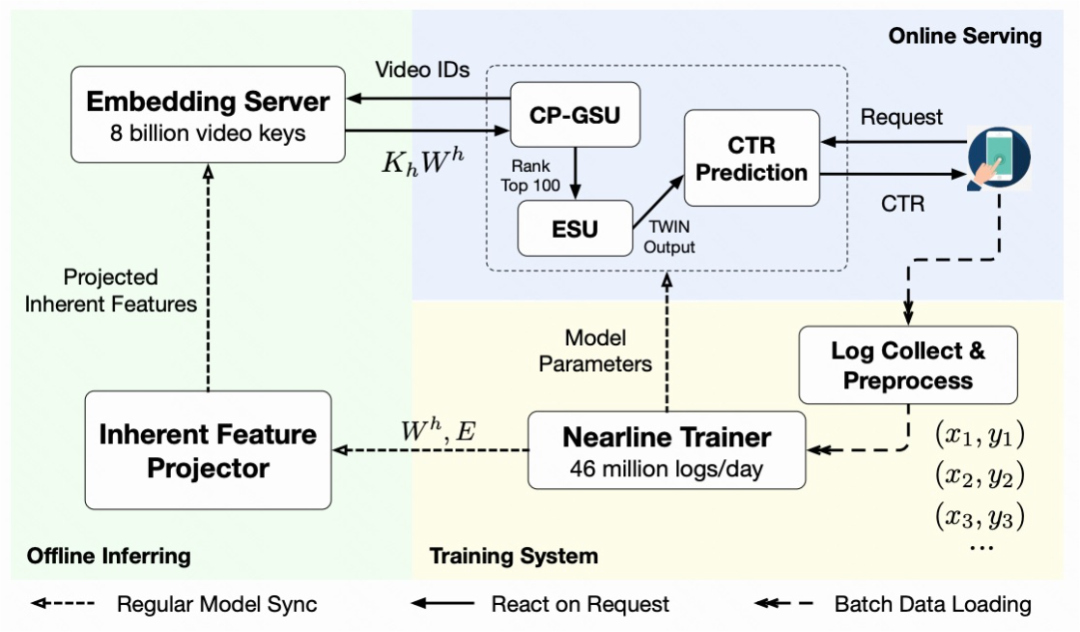 图六:系统设计图
图六:系统设计图
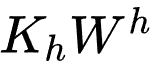 ,并存储成字典格式,供在线 GSU 服务时查询。经过一定的长尾过滤,我们成功的把 video id 限制在 8billion 级别,并覆盖 97% 的线上请求。如此线性映射计算模块,可以用最新的 embedding 和线性映射权重矩阵,在 15 分钟内对字典全面滚动更新一次。
,并存储成字典格式,供在线 GSU 服务时查询。经过一定的长尾过滤,我们成功的把 video id 限制在 8billion 级别,并覆盖 97% 的线上请求。如此线性映射计算模块,可以用最新的 embedding 和线性映射权重矩阵,在 15 分钟内对字典全面滚动更新一次。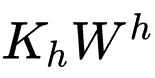 )中 99.3% 的计算量。现在该服务在峰时能每秒处理 3 千万视频的请求量。
)中 99.3% 的计算量。现在该服务在峰时能每秒处理 3 千万视频的请求量。 图七:与 SOTA 对比
图七:与 SOTA 对比
 图八:两阶段一致性
图八:两阶段一致性


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com