- 长臂猿-企业应用及系统软件平台
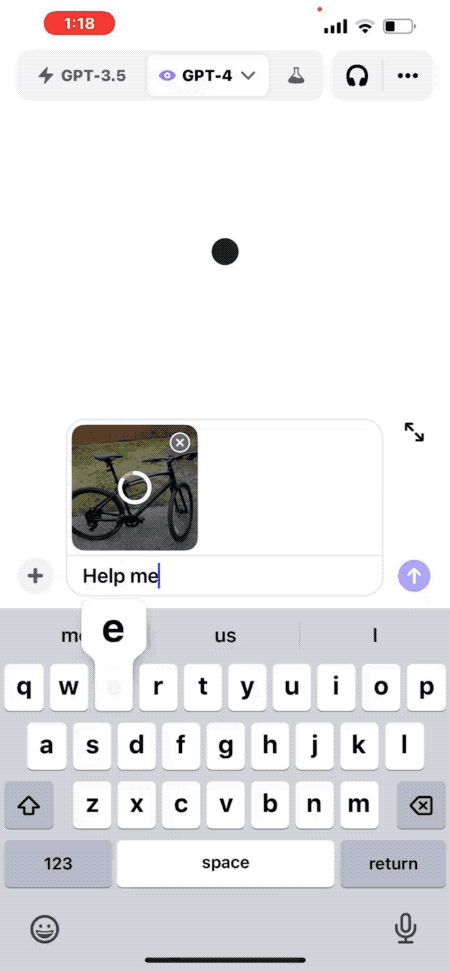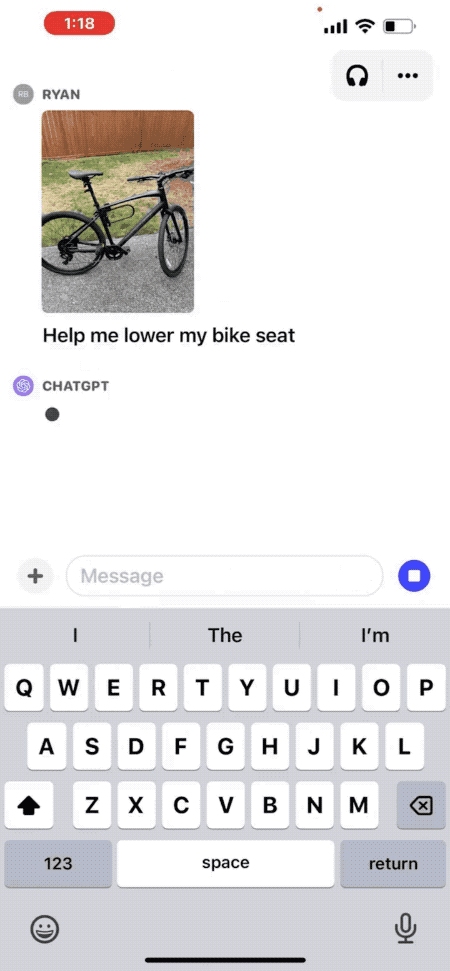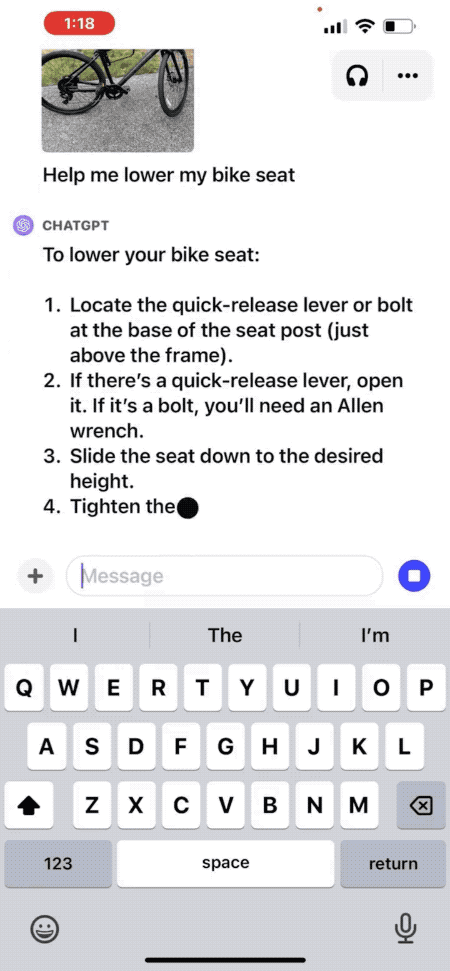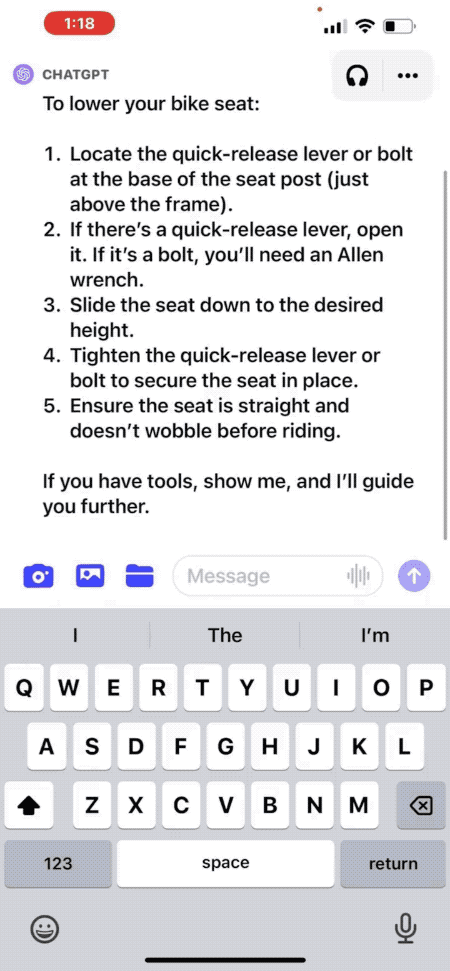
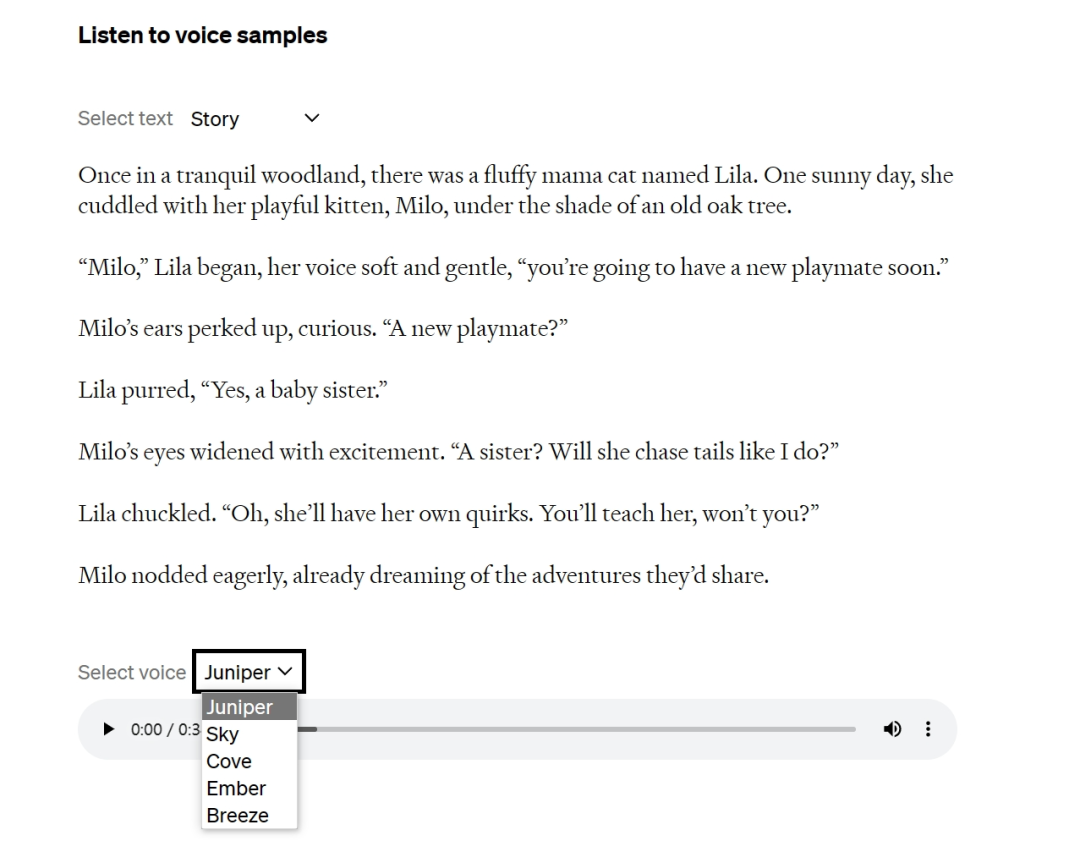
文章来源:https://openai.com/blog/chatgpt-can-now-see-hear-and-speak 就在昨晚,OpenAI CEO Sam Altman 在推特上发布了一条重要消息,ChatGPT 要推出新功能啦。ChatGPT 现在可以看、听和说了! 这次 ChatGPT 推出新的语音和图像功能提供了一种新的、更直观的界面类型,允许用户跟它进行语音对话,向 ChatGPT 展示说话内容。 多场景使用 ChatGPT 语音和图像让用户在生活中也可以轻松使用 ChatGPT。比如,旅行时,可以拍摄地标,并就其有趣的内容与 ChatGPT 进行实时对话。在家时,可以通过拍摄冰箱里的食物,来确定晚餐吃什么(或者获取食谱)。晚饭后,通过拍照,圈出问题,来帮助孩子解决数学问题。 比如拍一张照片,询问如何调整自行车座椅高度。 官方还给出另一个实用场景思路:打开冰箱拍一张照片,询问AI晚餐可以吃什么,并生成完整菜谱。 更新将在接下来的两周内向ChatGPT Plus订阅用户和企业版用户推出,iOS和安卓都支持。 与此同时,多模态版GPT-4V模型更多细节也一并放出。其中最令人惊讶的是,多模态版早在2022年3月就训练完了…… 看到这里,有网友灵魂发问:有多少创业公司在刚刚5分钟之内死掉了? 看听说皆备,全新交互方式 更新后的ChatGPT移动APP里,可以直接拍照上传,并针对照片中的内容提出问题。 比如“如何调整自行车座椅高度”,ChatGPT会给出详细步骤。 如果你完全不熟悉自行车结构也没关系,还可以圈出照片的一部分问ChatGPT“说的是这个吗?”。 就像在现实世界中用手给别人指一个东西一样。 不知道用什么工具,甚至可以把工具箱打开拍给ChatGPT,它不光能指出需要的工具在左边,连标签上的文字也能看懂。 提前得到使用资格的用户也分享了一些测试结果。 可以分析自动化工作流程图。 但是没有认出一张剧照具体出自哪部电影。 语音部分的演示还是上周DALL·E 3演示的联动彩蛋。 让ChatGPT把5岁小朋友幻想中的“超级向日葵刺猬”讲成一个完整的睡前故事。 ChatGPT这次讲的故事文字摘录如下: 要开始使用语音助手,可以前往移动应用上的“设置”→“新功能”,然后选择加入语音对话。然后,点击位于主屏幕右上角的耳机按钮,从五种不同的声音中选择你喜欢的声音。 新的语音功能由新的文本转语音模型提供支持,能够仅从文本和几秒钟的示例语音中生成类似人类的音频。每个声音都是 ChatGPT 与专业配音演员合作创作而成的。他们使用了开源语音识别系统 Whisper 将用户的口语转录为文本。 你现在可以向 ChatGPT 显示一个或多个图像,用来排查烤箱无法启动的原因、探索冰箱中的食材准备菜谱或分析与工作相关数据的复杂图表。要聚焦图像的特定部分,可以使用移动应用程序中的绘图工具。 (视频来源:openai.com) 开始使用前,请点击照片按钮以捕获或选择图像。如果你使用的是 iOS 或 Android,请先轻点加号按钮。你还可以讨论多个图像或使用绘图工具来指导你的助手。量子位 | 公众号 QbitAI






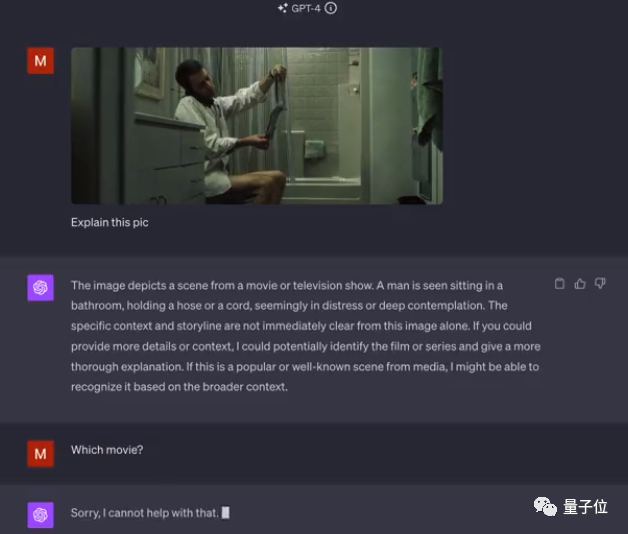 △认出的朋友欢迎在评论区回复
△认出的朋友欢迎在评论区回复 △DALL·E3演示
△DALL·E3演示
与 ChatGPT 进行有趣对话
用图像功能,解决实际问题
多模态GPT-4V能力大揭秘



买《ChatGPT实战课程》,送ChatGPT独享账号一个! 并且课程包含超多ChatGPT前沿玩法,帮助大家熟练掌握ChatGPT!
猜你喜欢的文章 ▶ 已经挂了26家公司了。 ▶ Windows「画图」史诗级改进,或成为轻量版PS ▶ OpenAI一夜颠覆AI绘画!DALL·E 3+ChatGPT强强联合,画面直接细节爆炸 来都来了,点个在看再走吧~~~


