- 长臂猿-企业应用及系统软件平台

最近大模型非常火爆,基于大模型的应用也层出不穷,比较火的比如 AutoGPT,当然也有很多垂直领域的应用。那么如何基于大模型的能力快速的建设一个垂直领域的 AI 应用呢,这就涉及到了 AI 工程化建设。在整个 AI 工程化建设的过程中,有很多核心的模块,主要包括:DataOps,MLOps,DevOps 等。这里主要从 Devops 角度针对应用架构展开叙述,个人所见,仅供抛砖引玉。
我们的终极目标就是把 AI 应用建设成虚拟人,使其可以具备人类的各项高阶能力从而可以在一些特定的领域取代人类,从事人类的工作,比如客服、助手等。
人有哪些高阶能力呢?概括一下,大致可分为四大类:可推理、可交互、具有记忆、多模态。
可推理:即拥有大脑并能进行推理思考,而 LLM 则是 AI 应用领域的大脑。
可交互:即互动交流和调度执行。人类之间通过交流讨论出某件事情的计划,并最终由人去调度执行这些计划对应的 Action。同样,AI 也应该具备这种互动交流及调度执行的能力。
可记忆:即数据感知。人类大脑里有个关键的组织:海马体,海马体可以把一些知识长期存储下来,从而使人具有长期记忆的能力。
多模态:多维度信息理解。这应该是人类最为高阶的能力,人类具备视觉、听觉、触觉、味觉和嗅觉能力,同时人类基于这些能力创造了文本、图像、音频、视频等多媒体沟通介质,并通过这些介质进行交互。同样,AI 也应该具备这种多媒体介质交互理解的能力。
上面我们聊到了 AI 应用应该具备的能力,很显然,如果 AI 应用要具备这些能力,仅仅靠一个 LLM 是完全不够的。LLM 具备比较强大的推理能力,但要具备其他高阶能力,我们还需要给 LLM 这个大脑接入其他的器官和躯干。接下来,我们分析下还需要具备哪些模块。
LLM 具备一定的文本交互的能力,但不具备调度执行的能力,因此我们需要一个代理角色能够代理 LLM 进行调度和执行。这里被调度的 Tool 包含 LLM 本身、第三方工具、内外部 API、私有知识库语料库(后面会重点讲语料库的价值)等。听起来有点抽象,我举个例子来说明下:
案例:
我要让 AI 应用给一段代码生成流程图。
执行步骤:
输入预处理:通过代理角色调度 LLM,让 LLM 制定一份执行计划(LLM Plan)。我们需要关注如何让 LLM 制定一份以被代理角色所理解执行的计划。用过 GPT 的同学应该都知道,可以通过输入一个提示模版给 GPT 并让 GPT 按照这个模版的格式进行输出。那么我们需要提前定义好计划模版,即 Prompt Template,并通过代理角色把 Question 嵌入到 Prompt Template 输入给 LLM,LLM 根据 Prompt Template 的格式输出 Thought,并将 Thought 文本结构化。
子任务调度:代理角色解析结构化的 Thought 文本输出,获取对应的 Action 和 Action Input,然后根据对应的 Action 和 Action Input 去调度对应的 Tool,获取调度 Tool 返回的 Observation。我们把 Thought、Action、Action Input、Observation 视为一个调度轮次数据集。
输出后处理:代理角色继续调度 LLM 并把上一个调度轮次的数据集嵌入到 Prompt Template 输入给 LLM,LLM 返回下一步的计划,重复 2,直至 LLM 或者 Tool 返回终止信号。
注:输出后处理可能是个递归调用的过程。
执行计划:
Question: 请帮我生成{xxxx}代码的流程图。
Thought: 首先我需要通过内部知识库了解下这段代码的业务场景,然后通过 LLM 解读这段代码并生成 Mermaid 脚本,最后调度 Mermaid Tool 生成流程图。
Action: Search Corpus
Action Input: "{xxxx}这段代码的业务场景是什么?"
Thought: 我现在知道了这段代码的业务场景,接下来我来调度 LLM 解读这段代码的逻辑并生成 Mermaid 脚本
Action: LLM
Action Input: 结合上述业务场景,解读一下这段代码的逻辑并生成 Mermaid 脚本。
Thought: 我现在知道了这段代码逻辑对应的 Mermaid 脚本,接下来我来调度 Mermaid 生成流程图
Action: Mermaid
Action Input: 结合上述代码逻辑对应的 Mermaid 脚本,生成流程图。
Final Answer: 流程图 url 为 xxxx。
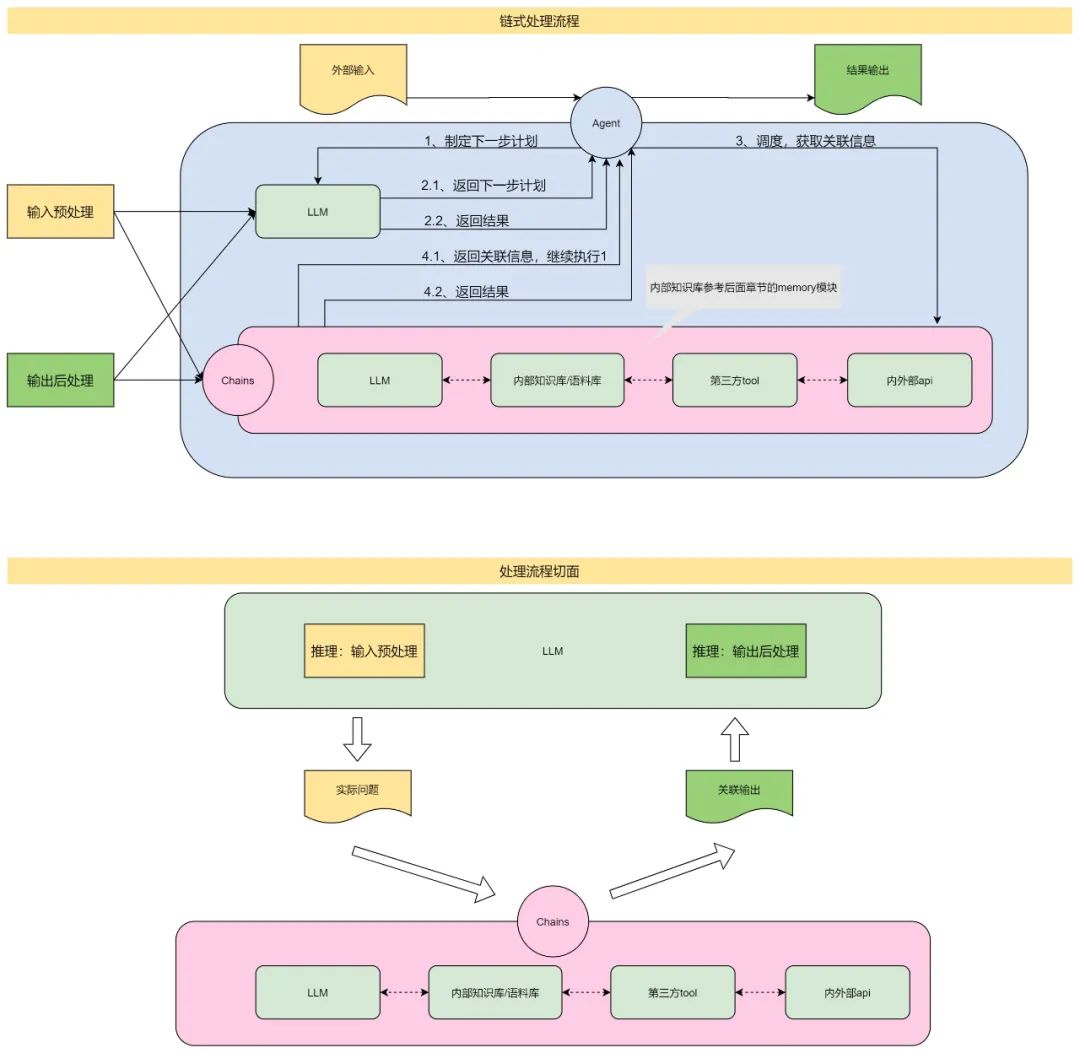
在上述详细思路里有提到了几个关键词:代理角色、Prompt Template、Tool、LLM。Tool 还可以被进一步往顶层抽象,从整体执行计划来看,代理角色把每个 Tool 串联成一个链,最终形成一个可执行的 Pipeline,因此 Tool 可以被抽象成 Chain。除此之外,在执行计划里 LLM 被多次调用,我们可以深入挖掘一下 LLM 是否也可以继续向顶层抽象,考虑到 LLM 众多,比如 OpenAI、ChatGLM、自建大模型等等,那么就可以在 LLM 上做一个适配层(类似于 DDD 里的防腐层),这个适配层的使命是兼容所有的大模型并让上层应用无感知的去调用任何一类大模型,可以给他起了一个简单的名字:LLMS。
综上所述,我们可以概括性的认为:要实现 AI 应用的交互能力,我们的应用架构里至少要包含:代理模块、Prompt Template 模块、Chain 模块、LLMS 模块。
上文有讲到,LLM 具备一定的交互能力,但不具备调度和执行的能力,而引入 Agent 的目的是调度,引入 Tool 的目的是执行,两者结合起来就给 LLM 接上了调度执行的能力。
LLM 的推理能力很强大,但其知识更新的成本比较高。对 LLM 进行知识更新的方式有两种,一种是训练,包括重新训练和继续训练,另一种是微调。这两种方式的成本较高、周期较长,同时微调的结果也未必符合预期。业内目前也有一些比较 hack 的方式去弥补这方面的缺陷,比如通过 Prompt 把最新的知识告诉 LLM,但 LLM 所接受 Prompt 的 token 数是有限制的,因此这种方式也存在很大的上限瓶颈。
而知识库更新成本低、周期短,可以通过在知识库里获取与问题关联的关键语料信息,然后再把这些关键语料信息交给 LLM,再利用 LLM 强大的推理能力进行推理,最终获取符合预期的结果。因此引入知识库来弥补 LLM 知识更新的缺陷是一个不错的折中方案。
这个问题我也不止一次的想过,结合我过去的实践主要分了几种,可能不全,仅供参考:
输入补全。用户的输入可能不全,需要联想补齐;
输入纠错。用户的输入可能存在错误的字符或者语法,需要理解语义,并进行词法和语法纠正;
输入转化和组装。用户的输入可能不是文字,可能是一系列动作、事件,需要进行转化和组装;
输入提炼。用户的输入可能比较泛,需要加以提炼,概括出重要关键的信息。这样一方面可避免产生干扰,另一方面也可规避 token 数限制。
输入拆解。用户的输入不会存在一些详细的调度执行计划,需要理解输入语义,进行任务拆解,从而方便后续的调度执行。
这个问题我同样也不止一次的想过,结合我过去的实践主要分了几种,可能不全,仅供参考:
输出纠错。输出不稳定是 LLM 常见的问题,需要纠错
输出转化。LLM 是文生文模型,但 AI 智能体还需要能够产生图片、音频、视频、行为动作等。因此需要对输出进行转化,能够突破文生文的限制。
LLM 在训练好之后,如果不对其进行微调,其掌握的知识是固定不变的,可以认为:LLM 本身不具备记忆能力。因此,我们还需要一个具有记忆能力的模块去支撑 LLM。
前一阵子比较火的 AI 应用很多都是基于 OpenAI+Pinecone 架构,OpenAI 是 LLM,即具备推理功能的“大脑”,Pinecone 是向量数据库,即具备存储记忆功能的“海马体”,从而给 LLM 增强感知数据的能力。那么为什么要引入向量存储呢?在“可记忆”这个维度下主要有两个原因:
择优选择 prompt:如果有大量的信息或者语料需要给 LLM,把大量文本全部作为 prompt 显然很不经济,而且过多不相干的信息还可能误导模型输出(笔者之前就遇到过类似情况,大量参考信息喧宾夺主,导致结果不准确)。因此,就需要提前把语料库向量化,再查询跟问题向量最相似的语料,最终一同送入 LLM。
记忆存储:从高效经济的角度来看,并不是所有的交互都需要经过 LLM,如果在之前有类似的交互,则可以把交互的数据集存储在向量库,当下次进行类似交互的时候,可以直接从向量库进行获取,即在一定程度上对过往经验知识进行复用。举个通俗的例子,就好比一个人要去计算 1024*1024 的结果,一种方式是可以通过大脑走一遍计算过程来计算出结果,另一种方式则是直接从海马体获取过去记忆的结果,很显然,从海马体直接获取更加高效和经济。
那么记忆模块为什么要用向量数据库而不是传统的数据库呢?传统的数据库基本都是基于索引进行查找,其查找结果主要有两类:匹配和不匹配,概括说就是结果是精确的。而向量数据库则是根据维度特征进行模糊匹配,找到的结果只能说相似度很高,但不是精确的,同时与传统数据库相比,向量数据库具有以下优势:
高维度数据:AI 应用通常涉及到大量的高维度向量表示,如图像、文本和音频数据,AI 应用通过高维度向量来表达这些媒介的特征。而传统数据库往往基于文本存储,而文本数据维度较高,存储起来较为稀疏,特征表达不明确且学习起来也比较低效,举个通俗的例子:如果我们把每个单词看作向量,King-Queen 等于 Man-Woman(代表性别的差异),但显然,这个等式是不成立的。
相似性搜索:AI 中经常需要进行相似性搜索,即根据向量之间的相似度找到最相似的项。向量数据库使用向量索引技术,能够快速进行相似性搜索,从而提高搜索效率和准确性。
快速计算:即算力优势。向量数据库可以借助 GPU Many Core 并行计算的特性进行向量化计算和并行处理,可以高效地执行大规模的向量操作,如向量加法、乘法和归一化等。
可扩展性:AI 应用通常需要处理海量的向量数据,传统数据库在处理大规模数据时面临着性能瓶颈。而向量数据库提供了良好的扩展性,可以轻松处理大规模数据集。
我们需要增加一个通过向量数据库实现的 Memory 模块来满足 AI 应用的记忆功能,这个实现过程就是向量索引创建(官方词汇:Embedding,即在高维度下给文本、图片等上层媒介找到合适的位置进行嵌入)、存储、匹配的过程,我们把这个过程抽象成一个顶层的模块:Indexes 模块。下面是一个比较经典的 LLM+ 向量数据库组建 AI 应用的架构图:
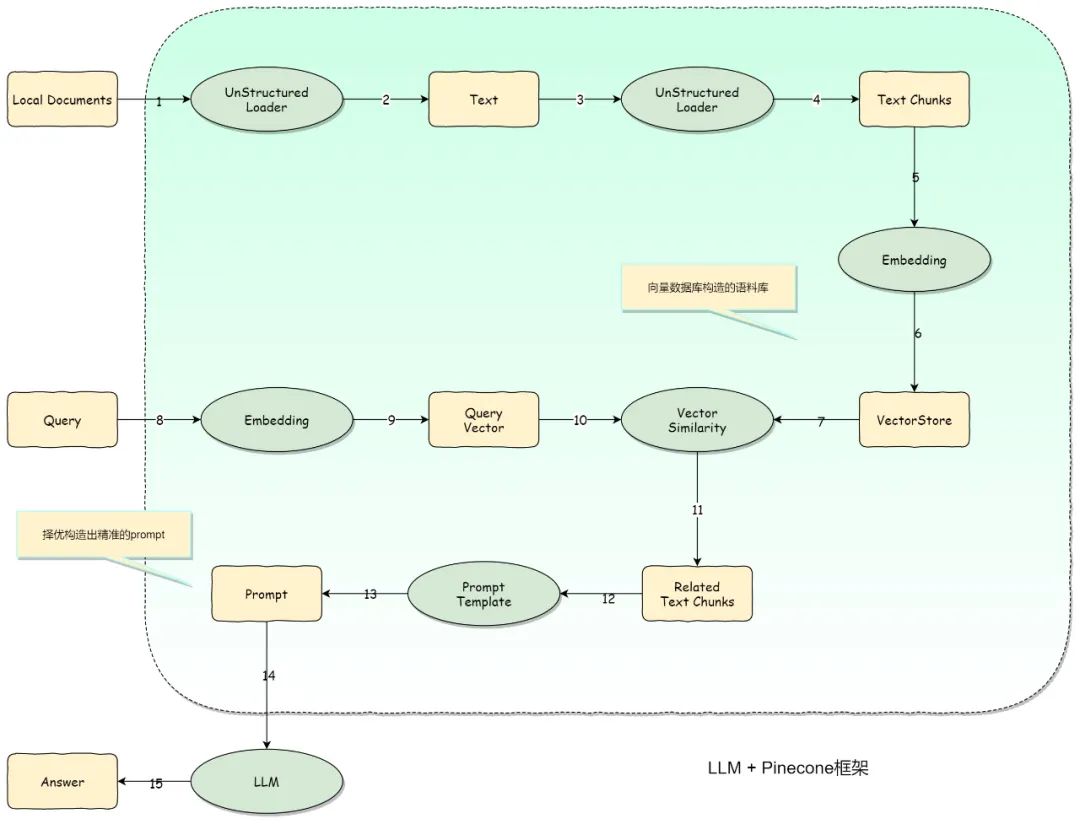
综上所述,我们可以概括性的认为:要实现 AI 应用的记忆能力,我们的应用架构里至少要包含:Memory 模块和 Indexes 模块。
移动互联网时代,Json 大行其道,但 Json 始终无法表达多媒体介质,不过这个问题在 AI 时代已经有了答案:向量作为大模型理解世界的全新数据形式,将带动整个数据传输、存储的变革,即向量数据库。在上面一节,我也讲到了向量数据库的优势,可见,向量数据库将是 AI 应用里必不可少的一个重要基础组件。
除了满足可推理、可交互、可记忆、多模态这四项核心能力以外,AI 应用还需要关注几项通用核心指标:安全性指标和稳定性指标。
内容安全是一块非常重要的部分,后续会单独写一篇思考。
监控模块
主要包括通用指标监控和业务指标监控
任务调度模块
LLM 调度比较耗时,通过任务调度模块来异步化调用 LLM
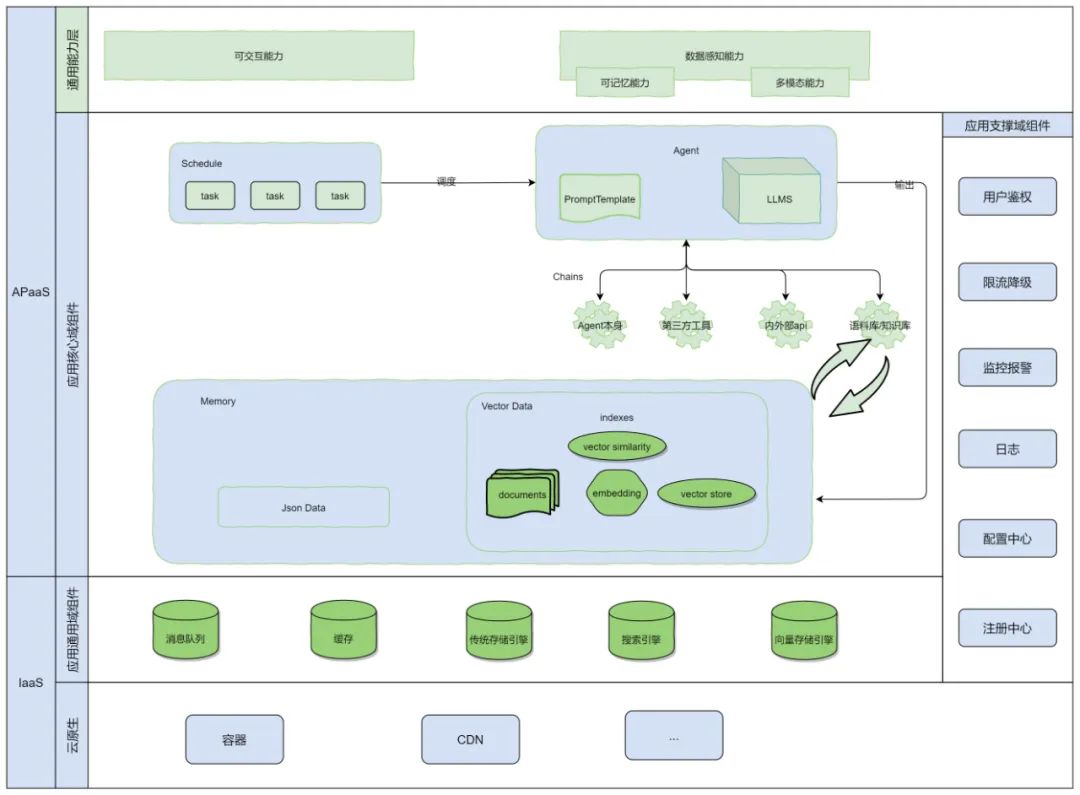
上面主要从组件视角进行了一轮剖切,从组件视角切面来看,AI 应用主要分为应用核心域组件、应用通用域组件和应用支撑域组件。其中应用核心域需要包含以下模块:代理模块、Prompt Template 模块、Chain 模块、LLMS 模块、Memory 模块、indexes 模块及调度模块。整体如下图所示:
花名:一粟(王贝)
职业:群核科技 / 技术专家
近十年互联网行业技术经验,专注于社交、电商、BIM 工具平台产品建设经验,早期就职于电商公司,经历了从零到十的电商平台建设及落地;后就职于群核科技,经历了硬装、水暖电深化设计的关键时期。有从云平台底层到业务最上层的全链路专家经验,擅长业务架构最佳实践、AI 工程化实践、研发管理、业务重保、疑难问题攻坚等。
《行知数字中国数字化转型案例集锦【第二期】》重磅发布,覆盖多个行业,对话一线专家,挖掘企业数字化的实践故事,揭秘数字化时代背景下如何重塑企业组织、技术与人才。扫描下方二维码,关注「InfoQ 数字化经纬」公众号,回复「行知数字中国」即可解锁全部内容。
