「任何认为自动回归式 LLM 已经接近人类水平的 AI,或者仅仅需要扩大规模就能达到人类水平的人,都必须读一读这个。AR-LLM 的推理和规划能力非常有限,要解决这个问题,并不是把它们变大、用更多数据进行训练就能解决的。」
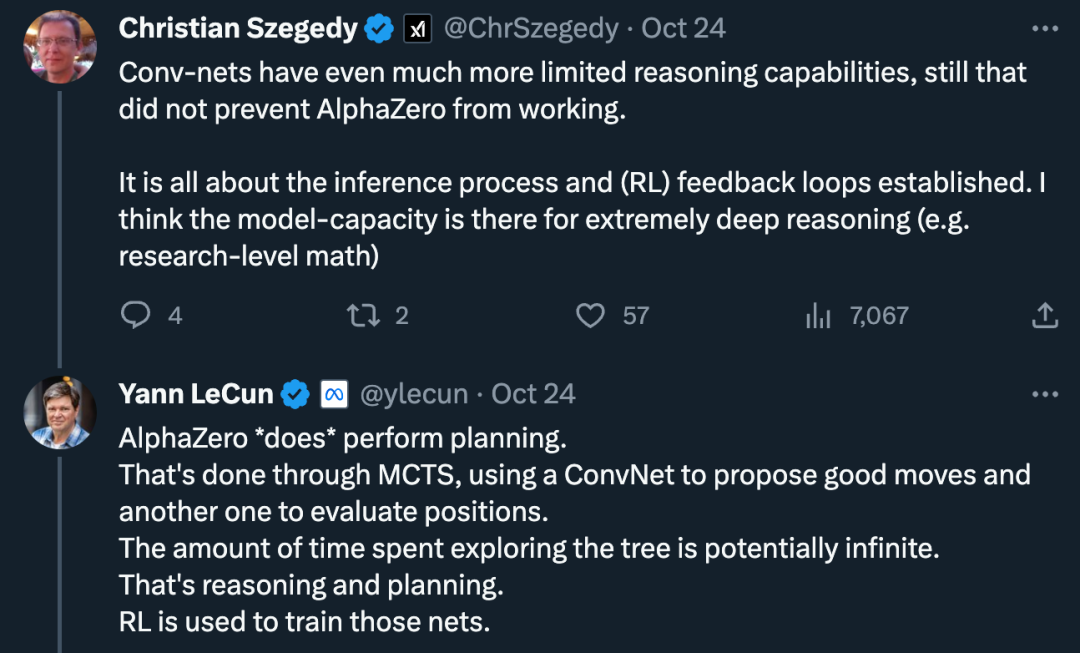
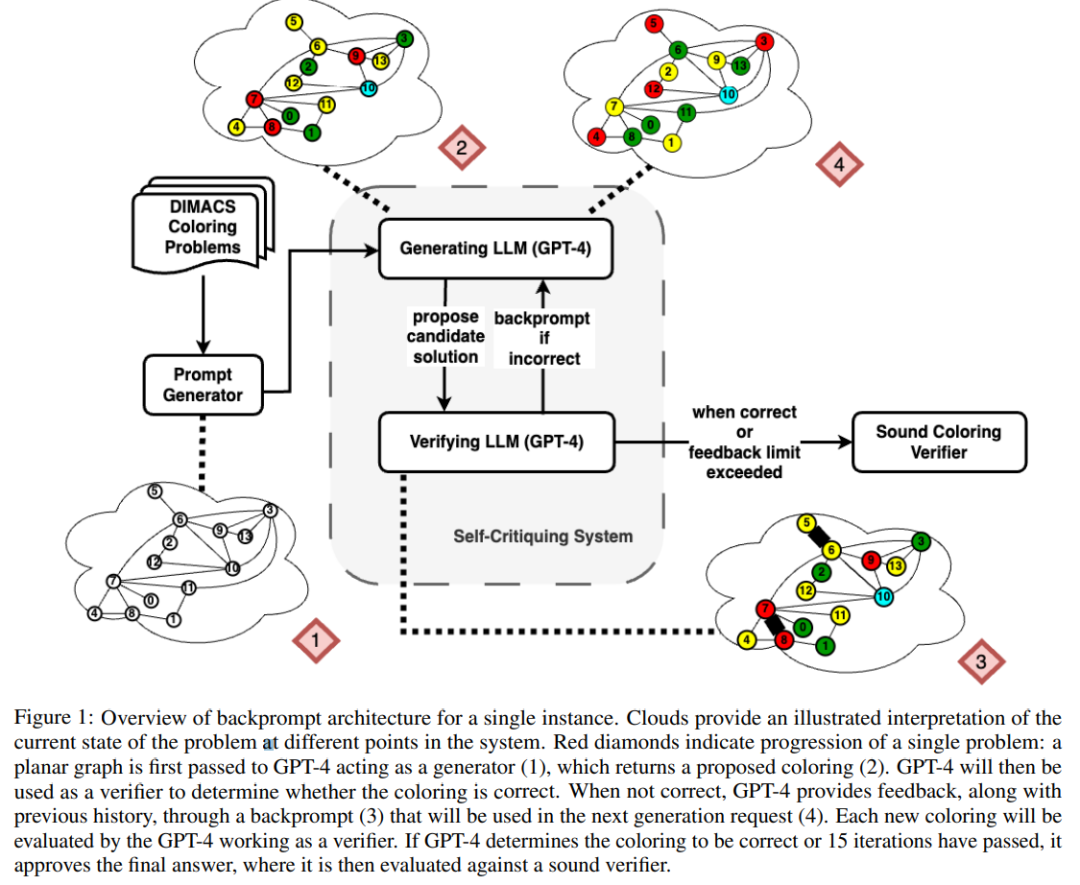
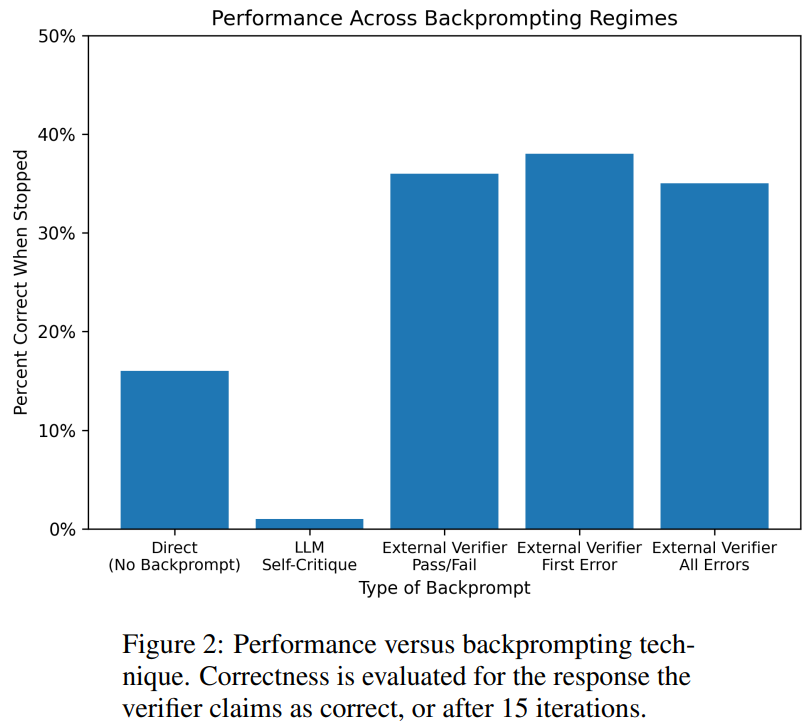
一直以来,图灵奖得主 Yann LeCun 就是 LLM 的「质疑者」,而自回归模型是 GPT 系列 LLM 模型所依赖的学习范式。他不止一次公开表达过对自回归和 LLM 的批评,并产出了不少金句,比如:「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」「自回归生成模型弱爆了!(Auto-Regressive Generative Models suck!)」让 LeCun 近日再次发出疾呼的,是两篇新发布的论文:「LLM 真的能像文献中所说的那样自我批判(并迭代改进)其解决方案吗?我们小组的两篇新论文在推理 (https://arxiv.org/abs/2310.12397) 和规划 (https://arxiv.org/abs/2310.08118) 任务中对这些说法进行了调查(并提出了质疑)。」看起来,这两篇关于调查 GPT-4 的验证和自我批判能力的论文的主题引起了很多人的共鸣。论文作者表示,他们同样认为 LLM 是了不起的「创意生成器」(无论是语言形式还是代码形式),只是它们无法保证自己的规划 / 推理能力。因此,它们最好在 LLM-Modulo 环境中使用(环路中要么有一个可靠的推理者,要么有一个人类专家)。自我批判需要验证,而验证是推理的一种形式(因此对所有关于 LLM 自我批判能力的说法都感到惊讶)。同时,质疑的声音也是存在的:「卷积网络的推理能力更加有限,但这并没有阻止 AlphaZero 的工作出现。这都是关于推理过程和建立的 (RL) 反馈循环。我认为模型能力可以进行极其深入的推理(例如研究级数学)。」对此,LeCun 的想法是:「AlphaZero「确实」执行规划。这是通过蒙特卡洛树搜索完成的,使用卷积网络提出好的动作,并使用另一个卷积网络来评估位置。探索这棵树所花费的时间可能是无限的,这就是推理和规划。」在未来的一段时间内,自回归 LLM 是否具备推理和规划能力的话题或许都不会有定论。论文 1:GPT-4 Doesn’t Know It’s Wrong: An Analysis of Iterative Prompting for Reasoning Problems第一篇论文引发了研究者对最先进的 LLM 具有自我批判能力的质疑,包括 GPT-4 在内。论文地址:https://arxiv.org/pdf/2310.12397.pdf人们对大型语言模型(LLM)的推理能力一直存在相当大的分歧,最初,研究者乐观的认为 LLM 的推理能力随着模型规模的扩大会自动出现,然而,随着更多失败案例的出现,人们的期望不再那么强烈。之后,研究者普遍认为 LLM 具有自我批判( self-critique )的能力,并以迭代的方式改进 LLM 的解决方案,这一观点被广泛传播。来自亚利桑那州立大学的研究者在新的研究中检验了 LLM 的推理能力。具体而言,他们重点研究了迭代提示(iterative prompting)在图着色问题(是最著名的 NP - 完全问题之一)中的有效性。该研究表明(i)LLM 不擅长解决图着色实例(ii)LLM 不擅长验证解决方案,因此在迭代模式下无效。从而,本文的结果引发了人们对最先进的 LLM 自我批判能力的质疑。论文给出了一些实验结果,例如,在直接模式下,LLM 在解决图着色实例方面非常糟糕,此外,研究还发现 LLM 并不擅长验证解决方案。然而更糟糕的是,系统无法识别正确的颜色,最终得到错误的颜色。如下图是对图着色问题的评估,在该设置下,GPT-4 可以以独立和自我批判的模式猜测颜色。在自我批判回路之外还有一个外部声音验证器。结果表明 GPT4 在猜测颜色方面的准确率低于 20%,更令人惊讶的是,自我批判模式(下图第二栏)的准确率最低。本文还研究了相关问题:如果外部声音验证器对 GPT-4 猜测的颜色提供可证明正确的批判,GPT-4 是否会改进其解决方案。在这种情况下,反向提示确实可以提高性能。即使 GPT-4 偶然猜出了一个有效的颜色,它的自我批判可能会让它产生幻觉,认为不存在违规行为。- 自我批判实际上会损害 LLM 的性能,因为 GPT-4 在验证方面很糟糕;
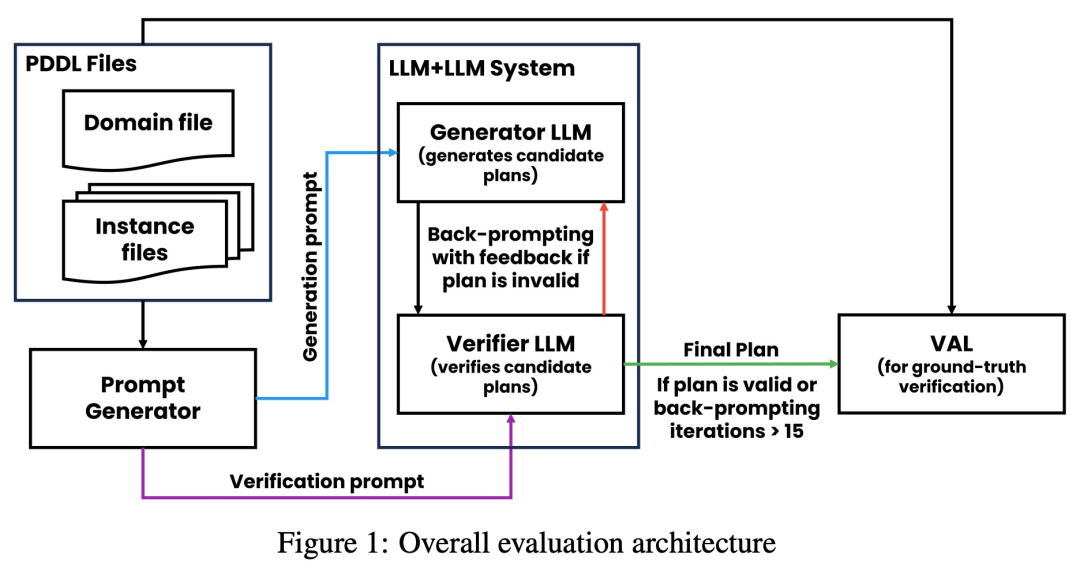
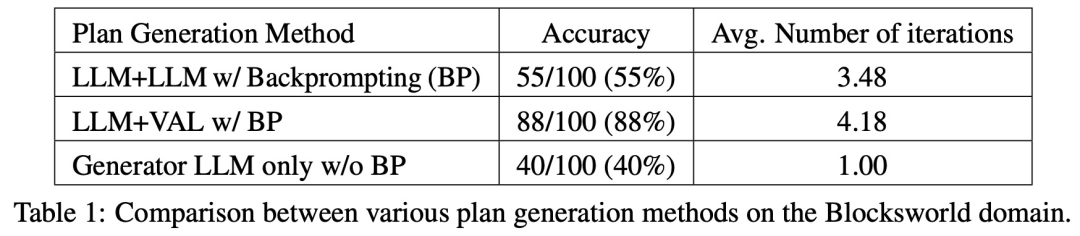
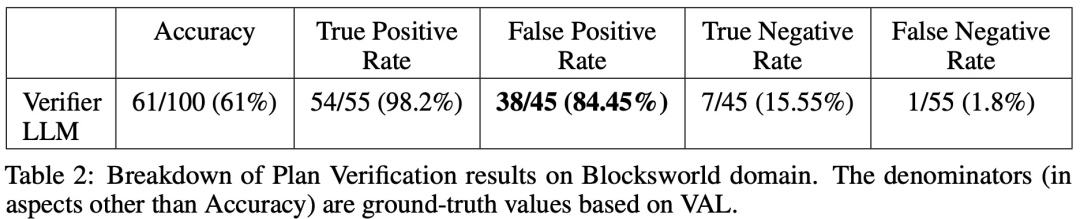
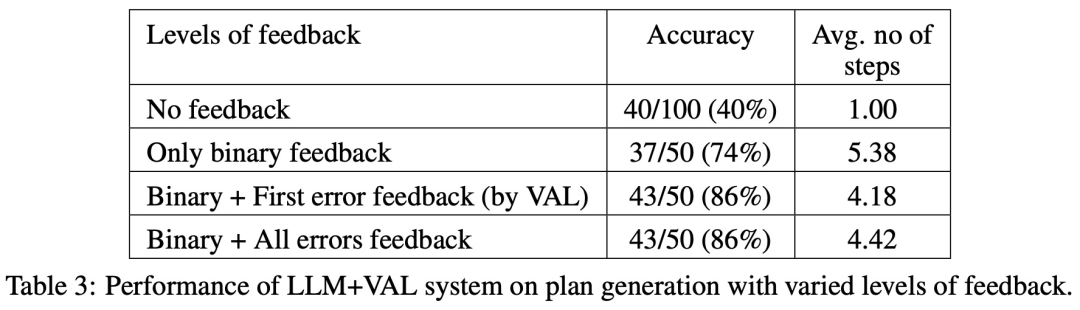
论文 2:Can Large Language Models Really Improve by Self-critiquing Their Own Plans?在论文《Can Large Language Models Really Improve by Self-critiquing Their Own Plans?》中,研究团队探究了 LLM 在规划(planning)的情境下自我验证 / 批判的能力。这篇论文对 LLM 批判自身输出结果的能力进行了系统研究,特别是在经典规划问题的背景下。虽然最近的研究对 LLM 的自我批判潜力持乐观态度,尤其是在迭代环境中,但这项研究却提出了不同的观点。论文地址:https://arxiv.org/abs/2310.08118令人意外的是,研究结果表明,自我批判会降低规划生成的性能,特别是与具有外部验证器和 LLM 验证器的系统相比。LLM 会产生大量错误信息,从而损害系统的可靠性。研究者在经典 AI 规划域 Blocksworld 上进行的实证评估突出表明,在规划问题中,LLM 的自我批判功能并不有效。验证器可能会产生大量错误,这对整个系统的可靠性不利,尤其是在规划的正确性至关重要的领域。有趣的是,反馈的性质(二进制或详细反馈)对规划生成性能没有明显影响,这表明核心问题在于 LLM 的二进制验证能力,而不是反馈的粒度。如下图所示,该研究的评估架构包括 2 个 LLM—— 生成器 LLM + 验证器 LLM。对于给定的实例,生成器 LLM 负责生成候选规划,而验证器 LLM 决定其正确性。如果发现规划不正确,验证器会提供反馈,给出其错误的原因。然后,该反馈被传输到生成器 LLM 中,并 prompt 生成器 LLM 生成新的候选规划。该研究所有实验均采用 GPT-4 作为默认 LLM。该研究在 Blocksworld 上对几种规划生成方法进行了实验和比较。具体来说,该研究生成了 100 个随机实例,用于对各种方法进行评估。为了对最终 LLM 规划的正确性进行真实评估,该研究采用了外部验证器 VAL。如表 1 所示,LLM+LLM backprompt 方法在准确性方面略优于非 backprompt 方法。在 100 个实例中,验证器准确识别了 61 个(61%)。下表显示了 LLM 在接受不同级别反馈(包括没有反馈)时的表现。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com