- 长臂猿-企业应用及系统软件平台
专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
最新研究表明,准确建模人类的3D空间音频与视觉场景的匹配,是实现虚拟环境沉浸感和临场感的关键。但多数学术界和企业目前只专注于视觉方面,而忽略了同样重要的听觉。
为了加速3D空间音频的研发进程,上海AI实验室和Meta联合开发了一种可为人体生成3D空间音频模型将其开源。
据悉该模型使用了头戴式麦克风的音频信号以及人体姿态作为输入,输出包围发声人身体的三维音场,从而可以在三维空间的任意位置渲染出空间音频。
论文地址:https://arxiv.org/abs/2311.06285
开源地址:https://github.com/facebookresearch/SoundingBodies

从技术层面来看,要开发一个3D空间音频模型并不容易,主要面临三大技术难题。1)音源位置未知,系统需要区分一些细微的身体动作声,判断声音来自左手还是右手;
2)麦克风距离音源较远,无法直接获取音源信号;3)语音和身体动作声混合在一起,无法进行分离。
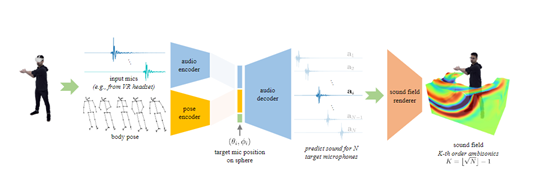
为了解决这些问题,研究人员构建了一个多模态融合模式,并加入身体姿态信息来消除声源的位置歧义,以生成正确的空间音频。
音频编码器
该模块的作用是处理来自头戴式麦克风的输入音频信号。通常我们想要模拟VR场景,用户需要戴着头盔,而音频是来自头盔上的麦克风。
输入音频包含语音和身体动作产生的各种声音,比如手拍、脚步声等。音频编码器的技术原理是首先根据可能的音源位置(比如不同的身体部位),对输入音频进行时间平移对齐。
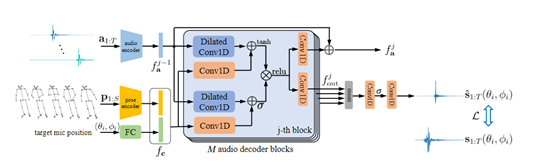
然后把时间对齐后的多个音频信号在通道维度上拼接在一起,传入一个全连接层,得到最终的音频特征表达。这种机制的好处是包含了来自各个可能音源位置的音频信息。
人体姿态编码器
主要作用是分析输入的人体姿态关键点,并生成姿态特征表达。当一个人产生音频的时候,他的身体动作会提供音源位置的强烈提示,例如,拍手声就是来自手部位置。所以人的姿态序列对生成正确的三维空间音频非常重要。

具体来说,首先获取身体各个关键点的三维坐标信息,然后通过卷积网络学习生成每个关节点的特征表达。最后将所有关节点的特征在通道维度上拼接,传入多层全连接网络,得到最终的姿态特征。
音频解码器
这个模块是基于以上获得的音频和姿态特征,以及想要生成的三维目标位置,预测这个位置的音频输出。所以,该解码器包含多个解码层。
同时, 每个解码块都包含卷积层、门控层和残差连接,可以捕获音频的长时序上下文。同时,解码块通过条件输入,结合音频特征、姿态特征和目标位置编码,来生成三维目标位置的音频输出。
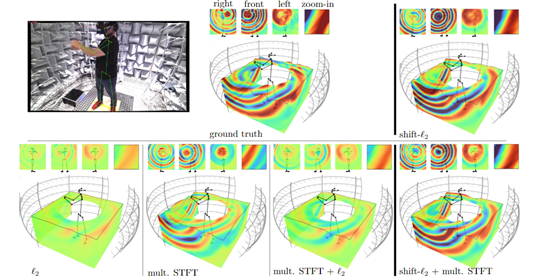
通过这种多模态特征解析和逐步上采样,系统最后可以扩展到整个三维空间,合成身临其境的3D音场效果。
尽管该模型在3D空间音频生成方面实现了技术突破,为建立真正沉浸式的虚拟人类迈出了关键一步。但研究人员表示,目前仅适用于渲染人体音,无法处理非自由音场传播环境,因为计算量较大,难以部署到资源受限的消费类设备上。
本文素材来源上海AI实验室论文,如有侵权请联系删除
END
 《遇见未来 发现AI视觉艺术》故事接龙AI短片大赛
《遇见未来 发现AI视觉艺术》故事接龙AI短片大赛
