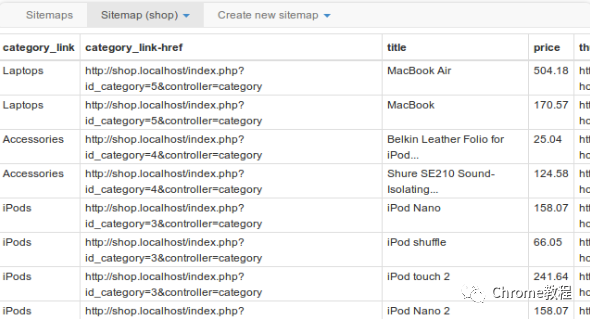
WebScraper爬虫插件下载及使用教程
WebScraper爬虫插件是一种简单而强大的网络数据提取工具,它能够帮助用户从网页上提取所需信息。它的使用不需要任何编程知识,通过其直观的点选界面,即使是初学者也能轻松掌握。
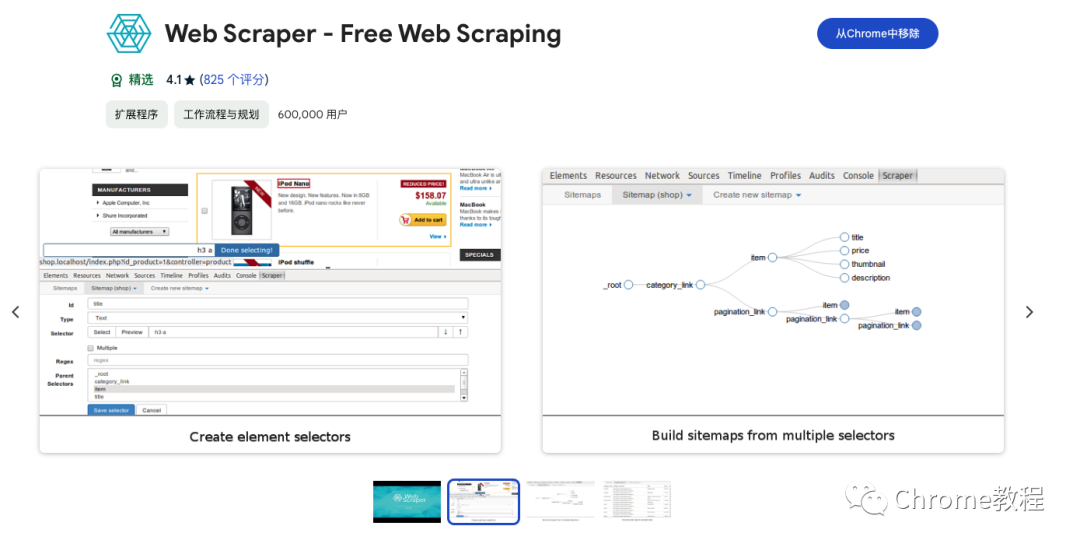
本教程旨在帮助您全面了解和使用WebScraper爬虫插件,从基本功能到实际应用,再到数据提取和导出,您将学会如何有效地利用这个工具。
 WebScraper的主要特点
WebScraper的主要特点
- 多种数据提取类型:支持文本、图片、URL等多种数据类型。
- 动态页面数据抓取:能够处理JavaScript和AJAX生成的内容,以及无限滚动页面。
- 数据导出:支持将数据导出为CSV或XLSX格式,便于在Excel或Google Sheets等工具中进一步处理。
安装和启动
安装插件:首先,在您的浏览器中安装WebScraper插件。
以下是WebScraper插件的安装步骤:
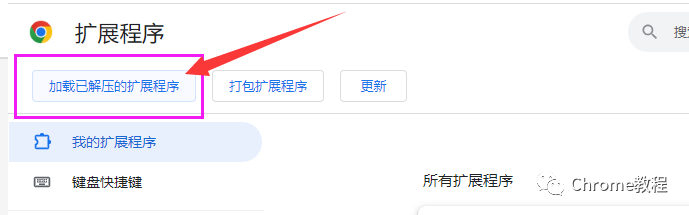
1.获取安装包:考虑到网络原因,部分同学无法实现在线安装,这种情况下可以直接通过离线安装的方法来解决。点击下方公众号,回复关键字:webscraper 获取安装包。2.安装包下载好后,打开chrome浏览器的扩展程序界面:
对于Chrome浏览器: 在地址栏中输入 chrome://extensions/ 并按Enter。对于Microsoft Edge(基于Chromium的新版本): 输入 edge://extensions/ 并按Enter。在扩展程序页面的右上角,你会看到一个“开发者模式”的切换按钮。确保它是打开(或启用)的。解压ZIP文件后,点击”加载已解压的扩展程序“选择该文件夹,即可加载成功。
使用步骤详解
创建站点地图
- 在“WebScraper”标签中点击“Create new sitemap”。
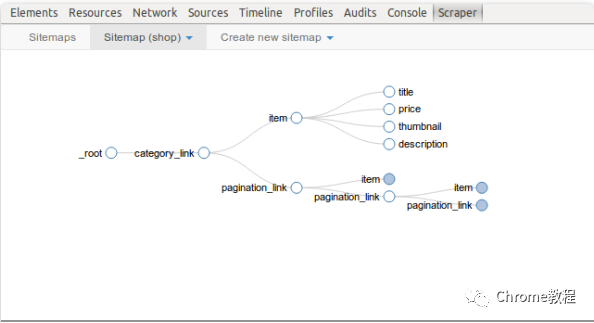
添加数据提取选择器
- 在站点地图中,点击“Add new selector”。
- 输入选择器名称,选择适当的类型(例如文本、链接、图片等)。
- 设置选择器的其他参数,例如选择器的父选择器或延迟时间(对于动态加载内容)。
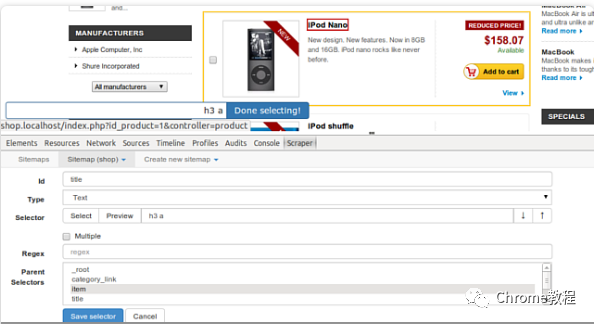
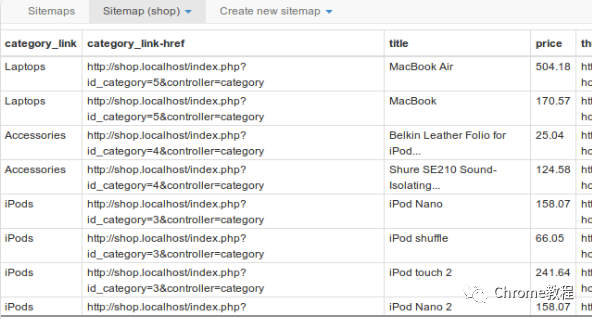
启动爬虫和导出数据
- 在站点地图视图中,点击“Scrape”按钮开始数据提取过程。
- 抓取完成后,点击“Export data”以CSV或XLSX格式导出数据。
结语
WebScraper爬虫插件是一个功能强大且用户友好的工具,适用于各种网页数据抓取需求。无论您是数据分析师、市场营销专家,还是简单地想要从网页上提取有用信息,WebScraper都能为您提供有效的解决方案。通过遵循本教程中的步骤,您将能够轻松掌握WebScraper的使用方法,并充分利用其强大功能。希望本教程能帮助您成功使用WebScraper爬虫插件。如果您在使用过程中遇到任何问题,欢迎访问WebScraper的官方论坛,那里有丰富的教程、常见问题解答以及一个友好的用户社区。祝您使用愉快!