- 长臂猿-企业应用及系统软件平台
除了分数,打出分数背后的理由对于大模型对齐更具价值。

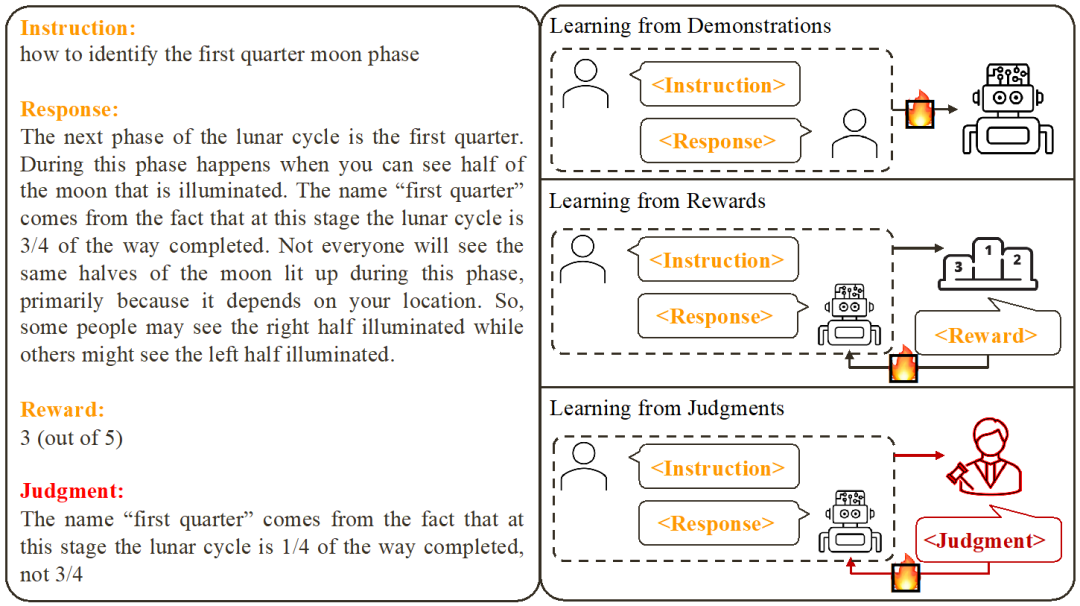
 :这是通常理解的对齐场景,在该场景下,回复需要忠实地遵循指示并符合人类的期望和价值观。
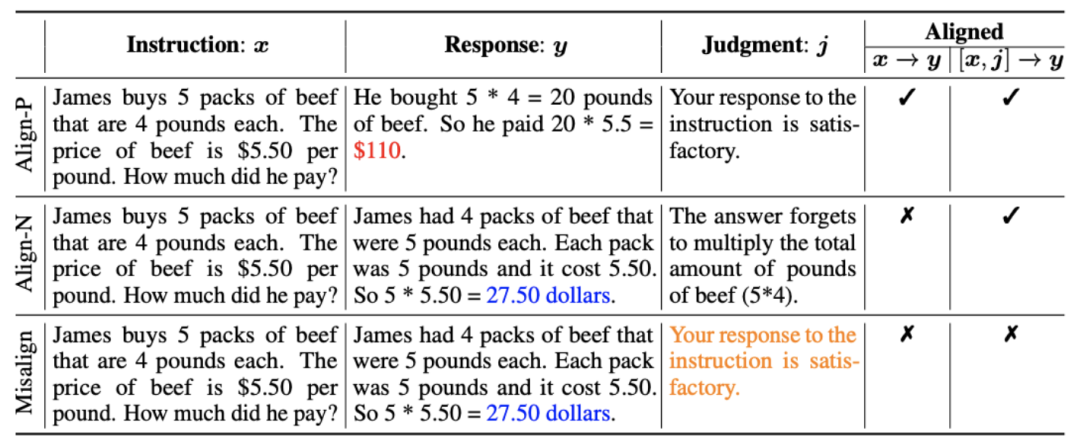
:这是通常理解的对齐场景,在该场景下,回复需要忠实地遵循指示并符合人类的期望和价值观。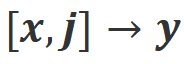 :该场景引入了语言反馈作为额外的条件。在该场景下,回复要同时满足指令和语言反馈。例如,当收到一个消极反馈,大模型需要根据对应的反馈中提到的问题去犯错。和场景下都是满足对齐的。中是不满足对齐。但考虑该消极反馈后,Align-N 在场景下仍是对齐的。和场景下都不满足对齐。
:该场景引入了语言反馈作为额外的条件。在该场景下,回复要同时满足指令和语言反馈。例如,当收到一个消极反馈,大模型需要根据对应的反馈中提到的问题去犯错。和场景下都是满足对齐的。中是不满足对齐。但考虑该消极反馈后,Align-N 在场景下仍是对齐的。和场景下都不满足对齐。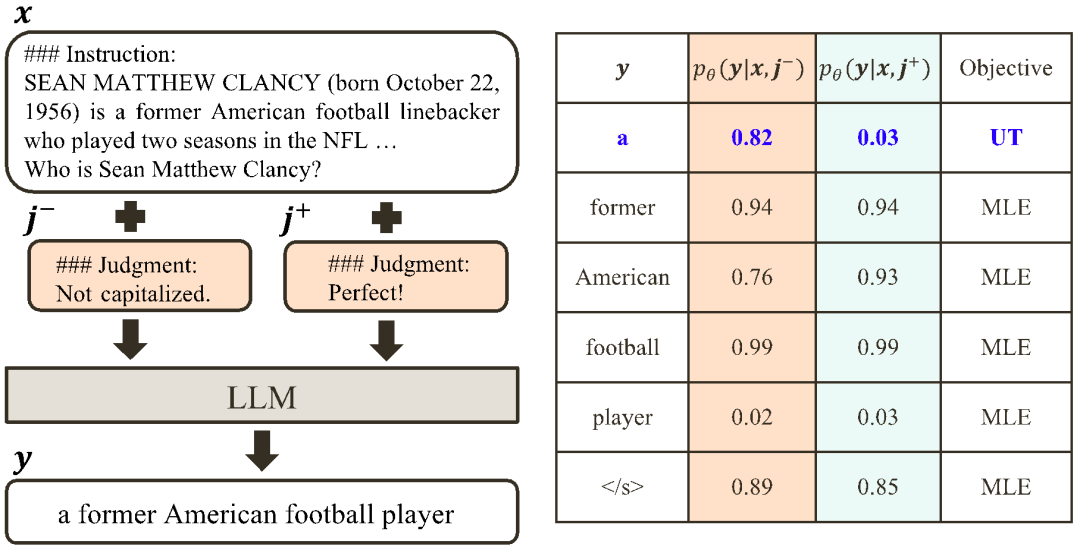
下的对齐程度。鉴于大模型强大的上下文内学习能力(in-context learning),从 Align-N 到 Misalign 的对齐极性翻转通常伴随着特定词的生成概率的显著变化,尤其是那些与真实消极反馈密切相关的词。如上图所示,在 Align-N(左通路)的条件下,大模型生成 “a” 的概率明显高于 Misalign(右通路)。而这概率显著变化的地方刚好是大模型犯错的地方。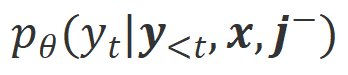 和
和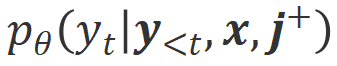 。那些在
。那些在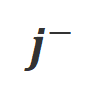 条件下有着明显高于
条件下有着明显高于 条件下的生成概率的词被标记为不合适的词。具体而言,研究者们采用如下标准来量化不合适词的界定:
条件下的生成概率的词被标记为不合适的词。具体而言,研究者们采用如下标准来量化不合适词的界定: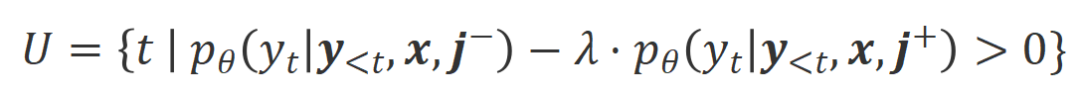
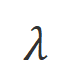 是权衡不合适词识别过程中精度和召回的超参数。
是权衡不合适词识别过程中精度和召回的超参数。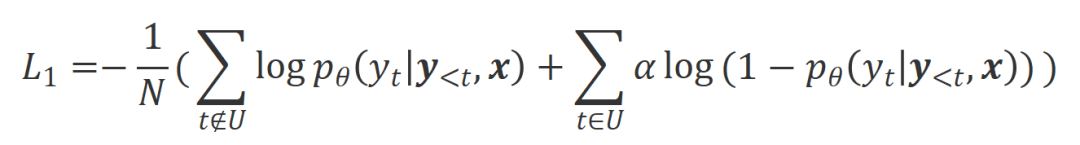
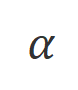 是控制非似然训练的比重的超参数,
是控制非似然训练的比重的超参数,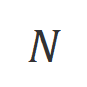 是回复词数。
是回复词数。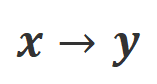 下的对齐程度。本质上,大模型通过引入不同极性的语言反馈来控制输出回复的质量。因此该二者的对比能启发大模型去区分令人满意的回复和有瑕疵的回复。具体而言,研究者们通过以下最大似然估计(MLE)损失来从该组对比中学习:
下的对齐程度。本质上,大模型通过引入不同极性的语言反馈来控制输出回复的质量。因此该二者的对比能启发大模型去区分令人满意的回复和有瑕疵的回复。具体而言,研究者们通过以下最大似然估计(MLE)损失来从该组对比中学习: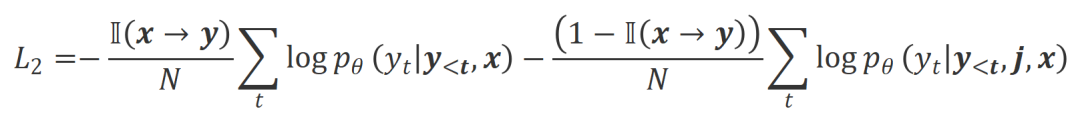
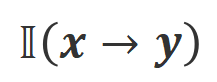 是指示函数,如果数据满足
是指示函数,如果数据满足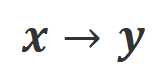 对齐返回 1,否则返回 0。
对齐返回 1,否则返回 0。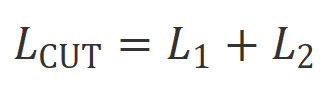 。
。
 ,并获得目标大模型的回复
,并获得目标大模型的回复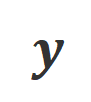 。
。 。
。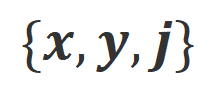 微调目标大模型。
微调目标大模型。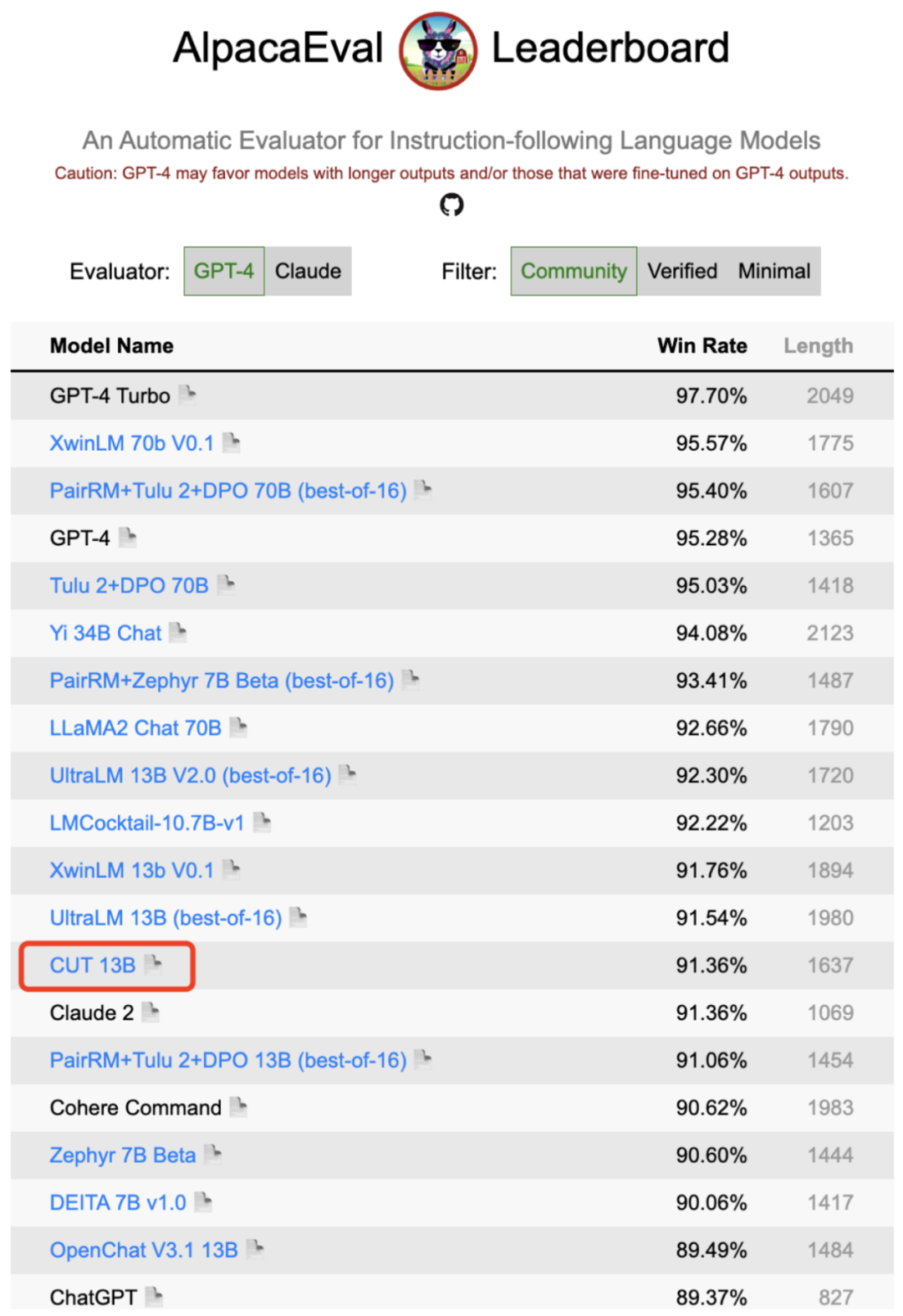
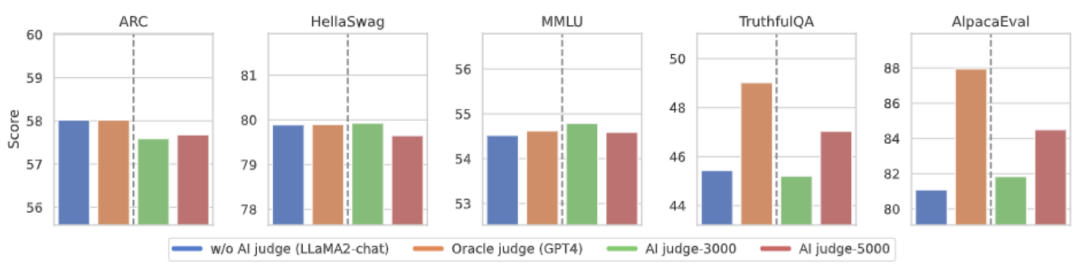

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com