- 长臂猿-企业应用及系统软件平台
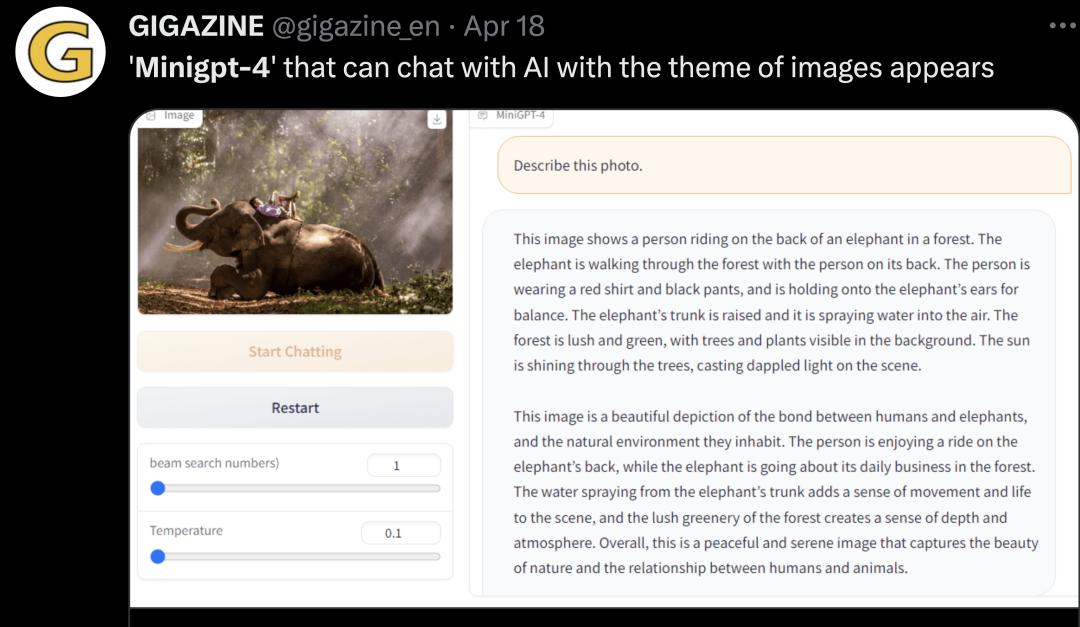
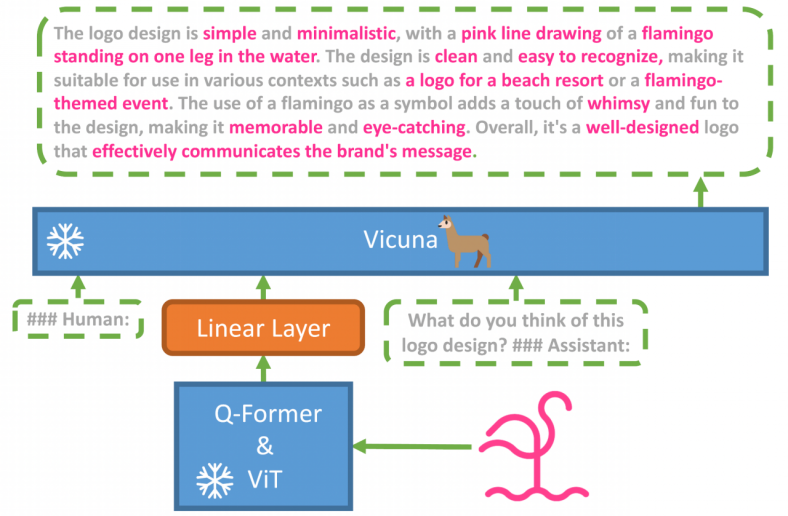
GPT-4 已经发布一个多月了,但识图功能还是体验不了。来自阿卜杜拉国王科技大学的研究者推出了类似产品 ——MiniGPT-4,大家可以上手体验了。 对人类来说,理解一张图的信息,不过是一件微不足道的小事,人类几乎不用思考,就能随口说出图片的含义。就像下图,手机插入的充电器多少有点不合适。人类一眼就能看出问题所在,但对AI来说,难度还是非常大的。 GPT-4的出现,开始让这些问题变得简单,它能很快的指出图中问题所在VGA线充iPhone。 其实GPT-4的魅力远不及此,更炸场的是利用手绘草图直接生成网站,在草稿纸上画一个潦草的示意图,拍张照片,然后发给GPT-4,让它按照示意图写网站代码,嗖嗖的,GPT-4就把网页代码写出来了。 但遗憾的是,GPT-4这一功能目前仍未向公众开放,想要上手体验也无从谈起。不过,已经有人等不及了,来自阿卜杜拉国王科技大学(KAUST)的团队上手开发了一个GPT-4的类似产品——MiniGPT-4。团队研究人员包括朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny,他们均来自KAUST的Vision-CAIR课题组。 MiniGPT-4展示了许多类似于GPT-4的能力,例如生成详细的图像描述并从手写草稿创建网站。此外,作者还观察到MiniGPT-4的其他新兴能力,包括根据给定的图像创作故事和诗歌,提供解决图像中显示的问题的解决方案,根据食品照片教用户如何烹饪等。 MiniGPT-4看图说话不在话下 MiniGPT-4效果到底如何呢?我们先从几个示例来说明。此外,为了更好的体验MiniGPT-4,建议使用英文输入进行测试。 首先考察一下MiniGPT-4对图片的描述能力。对于左边的图,MiniGPT-4给出的回答大致为「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4给出的回答是这张图像在现实世界并不常见,并给出了原因。 免责声明:所载内容来源于互联网,微信公众号等公开渠道,我们对文中观点持中立态度,本文仅供参考、交流。转载的稿件版权归原作者和机构所有,如有侵权,请联系我们删除。 点击查看↓↓ 阿里版ChatGPT突然官宣!我们用16个提问,火速进行了测评……













王慧文的光年之外开张,阿里知乎等四家大模型抢开发布会
ChatGPT平替「小羊驼」Mac可跑!2行代码单GPU,UC伯克利再发70亿参数开源模型

本文来自AI新探索