- 长臂猿-企业应用及系统软件平台
机器之心专栏 机器之心编辑部
大模型工具学习系统性综述 + 开源工具平台,清华、人大、北邮、UIUC、NYU、CMU 等联合发布。






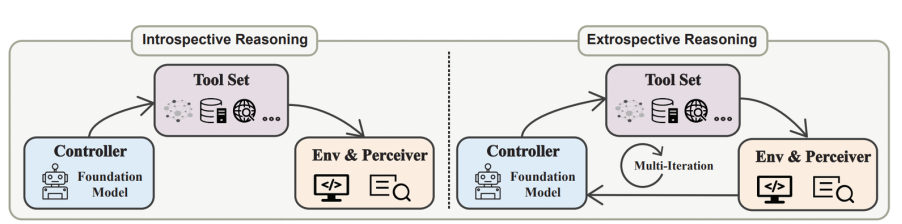
 ,在时间步 t,环境
,在时间步 t,环境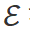 提供工具执行的反馈
提供工具执行的反馈 。感知器
。感知器 接收用户反馈
接收用户反馈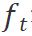 和环境反馈
和环境反馈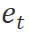 ,并生成总结反馈
,并生成总结反馈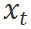 。控制器
。控制器 生成计划
生成计划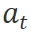 ,选择并执行来自
,选择并执行来自 的合适工具。这个过程可以建模为以下概率分布:
的合适工具。这个过程可以建模为以下概率分布: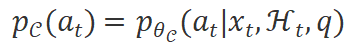
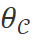 表示控制器
表示控制器 的参数,
的参数,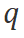 表示用户查询或指令,
表示用户查询或指令,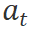 代表工具的具体执行计划,
代表工具的具体执行计划,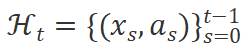 表示历史的反馈和计划。我们可以进一步将上式分解:
表示历史的反馈和计划。我们可以进一步将上式分解:
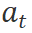 可以分为两个子任务:基于用户意图选择适当的工具和使用所选工具执行的具体操作。例如,对于 “我想预订下周去北京的飞机” 的指令,控制器
可以分为两个子任务:基于用户意图选择适当的工具和使用所选工具执行的具体操作。例如,对于 “我想预订下周去北京的飞机” 的指令,控制器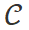 首先推断出用户的目标是预订一次去北京的航班。接着,模型选择航空公司预订系统作为工具。最后,它将时间和目的地作为初步计划输入以完成第二个子任务。良好的工具学习框架必须具备纠错的能力:例如如果下周没有飞往北京的航班,控制器
首先推断出用户的目标是预订一次去北京的航班。接着,模型选择航空公司预订系统作为工具。最后,它将时间和目的地作为初步计划输入以完成第二个子任务。良好的工具学习框架必须具备纠错的能力:例如如果下周没有飞往北京的航班,控制器 可以在接受到该反馈后更新计划。
可以在接受到该反馈后更新计划。





© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
本文来自机器之心