- 长臂猿-企业应用及系统软件平台
来源:blog.csdn.net/weixin_42475060/article/details/129399125

import numpy as npimport plotly.express as pxdef thresholding_algo(y, lag, threshold):""":param y: 输入列表:param lag: 滑动窗口大小:param threshold: 调节系数,用于调节容忍范围的大小。:return:"""# signals:信号列表signals = np.zeros(len(y))avgFilter = np.zeros(len(y))# 初始化平均值列表、差值列表avgFilter[lag - 1] = np.mean(y[0:lag])dif_li = [0] * len(y)for i in range(lag, len(y)):if i < len(y) - lag - 30:for j in range(i + 11, len(y)):if y[j] >= y[i - 1]:breakif j >= len(y) - 30:back = y[i - 1]else:back = np.mean(y[j + 11:j + 20 + lag])else:back = y[i - 1]# 前后均值差值计算tmp = abs(back - avgFilter[i - 1])dif = (tmp if tmp > 1 else 1)if abs(y[i] - avgFilter[i - 1]) > dif * threshold:signals[i] = (1 if y[i] > avgFilter[i - 1] else -1)avgFilter[i] = np.mean(y[(i - lag):i])y[i] = avgFilter[i - 1]else:signals[i] = 0avgFilter[i] = np.mean(y[(i - lag):i])dif_li[i] = difreturn dict(signals=np.asarray(signals),avgFilter=np.asarray(avgFilter),y=np.asarray(y),dif=np.asarray(dif_li),)

public static Map<String, double[]> thresholding_algo(double[] y, int lag, double threshold) {double[] signals = new double[y.length];double[] avgFilter = new double[y.length];Arrays.fill(avgFilter, 0.0);avgFilter[lag - 1] = mean(Arrays.copyOfRange(y, 0, lag));double[] dif_li = new double[y.length];Arrays.fill(dif_li, 0.0);for (int i = lag; i < y.length; i++) {int j;if (i < y.length - lag - 30) {for (j = i + 11; j < y.length; j++) {if (y[j] >= y[i - 1]) {break;}}double back;if (j >= y.length - 30) {back = y[i - 1];} else {back = mean(Arrays.copyOfRange(y, j + 11, j + 20 + lag));}} else {back = y[i - 1];}double tmp = Math.abs(back - avgFilter[i - 1]);double dif = tmp > 1 ? tmp : 1;if (Math.abs(y[i] - avgFilter[i - 1]) > dif * threshold) {signals[i] = y[i] > avgFilter[i - 1] ? 1 : -1;avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));y[i] = avgFilter[i - 1];} else {signals[i] = 0;avgFilter[i] = mean(Arrays.copyOfRange(y, i - lag, i));}dif_li[i] = dif;}Map<String, double[]> result = new HashMap<>();result.put("signals", signals);result.put("avgFilter", avgFilter);result.put("y", y);result.put("dif", dif_li);return result;}private static double mean(double[] array) {double sum = 0.0;for (double d : array) {sum += d;}return sum / array.length;}

def Fusion_algorithm(y_list):"""最终的融合算法1、第一次遍历列表: 处理掉小于上一个值的点,使其等于上一个值。2、第二次使用z-score来处理异常点:一种基于统计方法的时序异常检测算法借鉴了一些经典的统计方法,比如Z-score和移动平均线该算法将时间序列中的每个数据点都看作是来自一个正态分布,通过计算每个数据点与其临接数据点的平均值和标准差,可以获得Z-score并将其用于检测异常值,将z-score大于3的数据点视为异常值,缺点:如果异常点太多,则该算法的准确性较差。3、:param y_list: 传入需要处理的时间序列:return:"""# 第一次处理for i in range(1, len(y_list)):difference = y_list[i] - y_list[i - 1]if difference <= 0:y_list[i] = y_list[i - 1]# 基于突变检测的方法:如果一个数据点的值与前一个数据点的值之间的差异超过某个阈值,# 则该数据点可能是一个突变的异常点。这种方法需要使用一些突变检测算法,如Z-score突变检测、CUSUM(Cumulative Sum)# else:# if abs(difference) > 2 * np.mean(y_list[:i]):# y_list[i] = y_list[i - 1]# 第二次处理# 计算每个点的移动平均值和标准差ma = np.mean(y_list)# std = np.std(np.array(y_list))std = np.std(y_list)# 计算Z-scorez_score = [(x - ma) / std for x in y_list]# 检测异常值for i in range(len(y_list)):# 如果z-score大于3,则为异常点,去除if z_score[i] > 3:print(y_list[i])y_list[i] = y_list[i - 1]return y_list


import numpy as npfrom sklearn.ensemble import IsolationForestimport plotly.express as pximport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansimport jsondef Fusion_algorithm(y_list):for i in range(1, len(y_list)):difference = y_list[i] - y_list[i - 1]if difference <= 0:y_list[i] = y_list[i - 1]# else:# if abs(difference) > 2 * np.mean(y_list[:i]):# y_list[i] = y_list[i - 1]ma = np.mean(y_list)std = np.std(y_list)z_score = [(x - ma) / std for x in y_list]for i in range(len(y_list)):if z_score[i] > 3:print(y_list[i])y_list[i] = y_list[i - 1]return y_list


# Buggy Pythonimport Randoma = random.randint(1,12)b = random.randint(1,12)for i in range(10):question = "What is "+a+" x "+b+"? "answer = input(question)if answer = a*bprint (Well done!)else:print("No.")









class PBA(nn.Module):def __init__(self, PerformanceThreshold, DistributionType, AttentionWeightRange):super(PBA, self).__init__()self.PerformanceThreshold = PerformanceThresholdself.DistributionType = DistributionTypeself.AttentionWeightRange = AttentionWeightRangedef forward(self, input, performance_scores):# 计算注意力分数attention_scores = []for i in range(len(input)):if performance_scores[i] > self.PerformanceThreshold:attention_scores.append(performance_scores[i])else:attention_scores.append(0.0)# 将性能分数映射到注意力权重if self.DistributionType == "softmax":attention_weights = F.softmax(torch.tensor(attention_scores), dim=0)elif self.DistributionType == "sigmoid":attention_weights = torch.sigmoid(torch.tensor(attention_scores))else:raise ValueError("Unknown distribution type: {}".format(self.DistributionType))# 缩放注意力权重到指定范围attention_weights = attention_weights * (self.AttentionWeightRange[1] - self.AttentionWeightRange[0]) + self.AttentionWeightRange[0]# 计算加权输入weighted_input = torch.mul(input, attention_weights.unsqueeze(1).expand_as(input))output = torch.sum(weighted_input, dim=0)return output
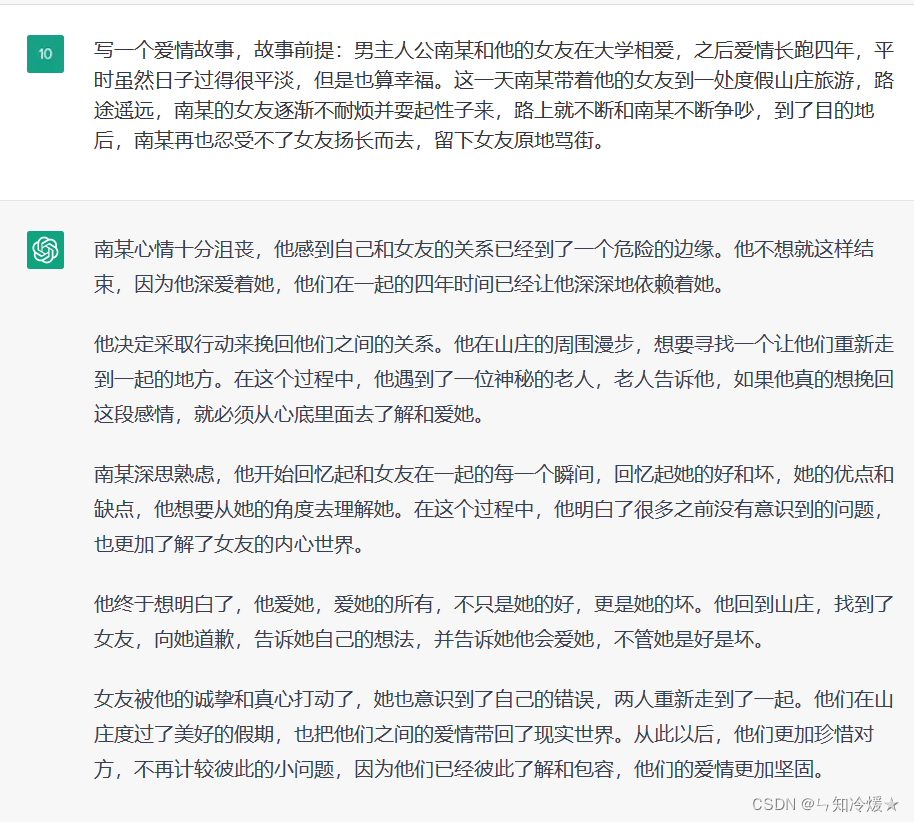


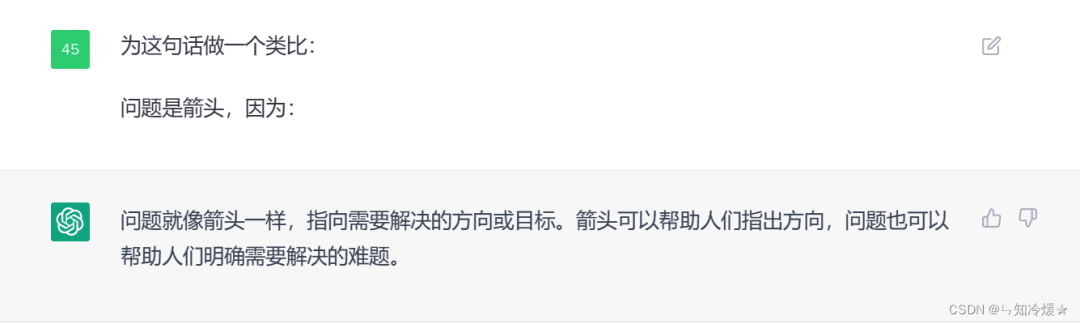
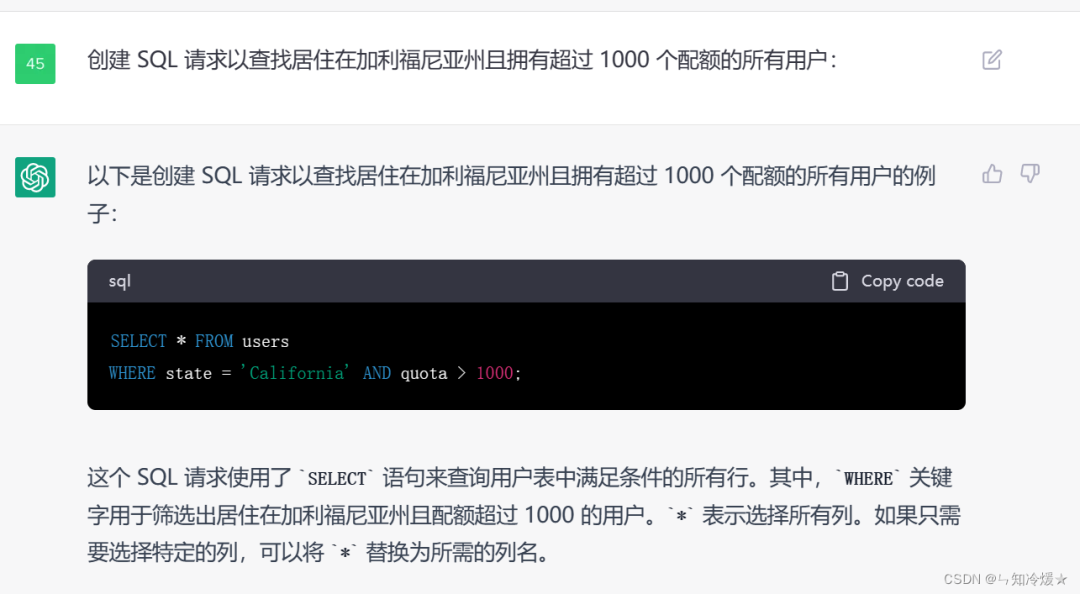
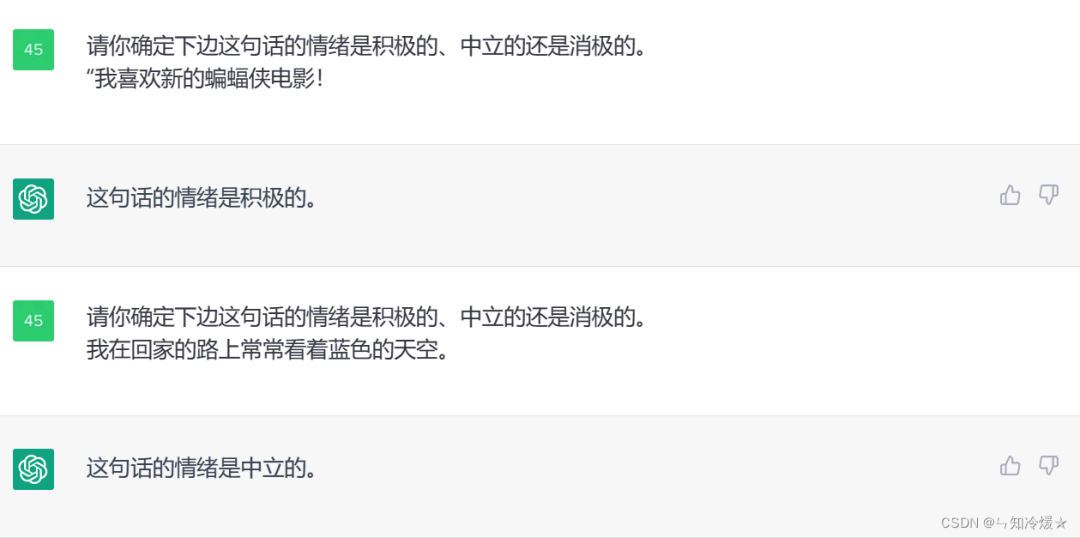

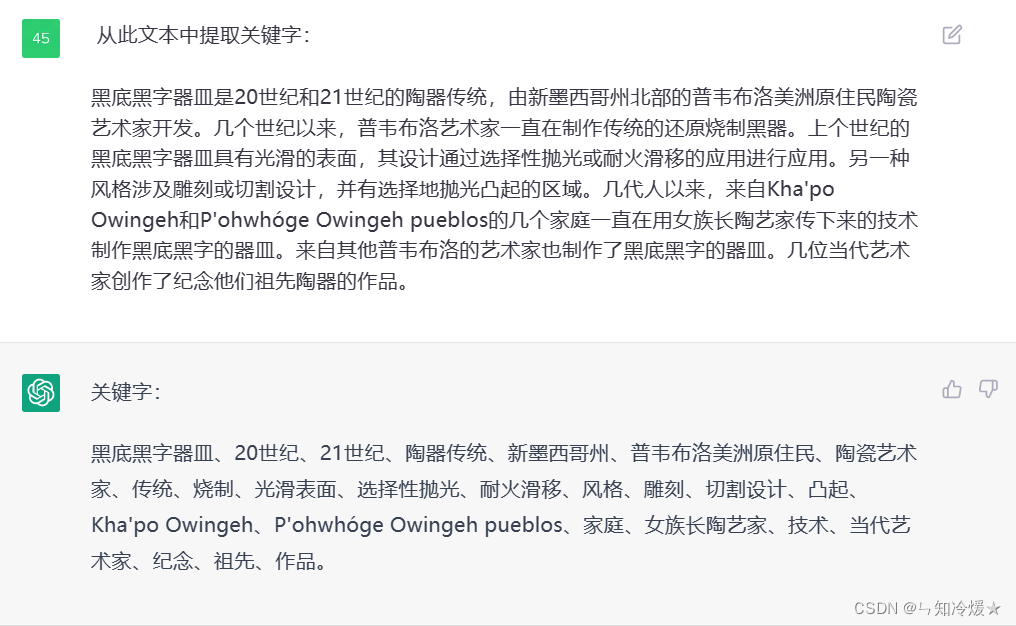
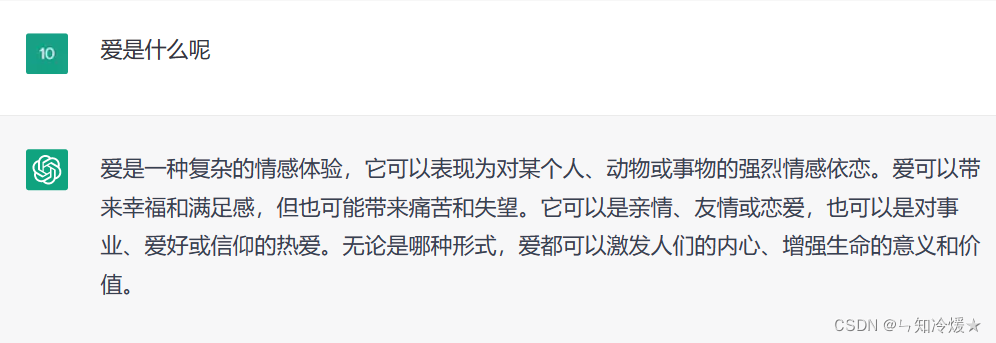
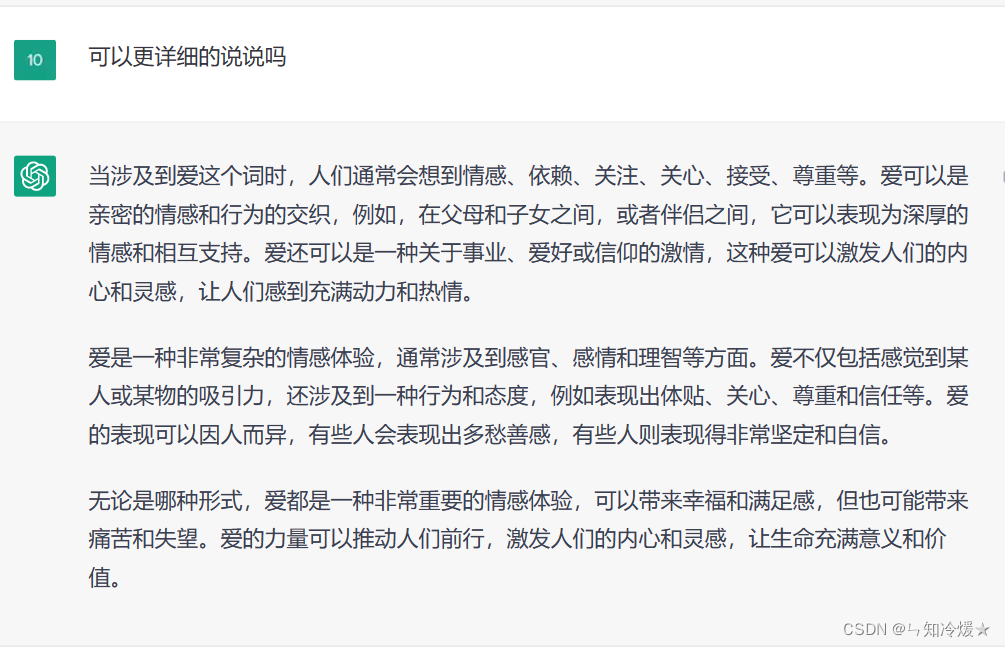
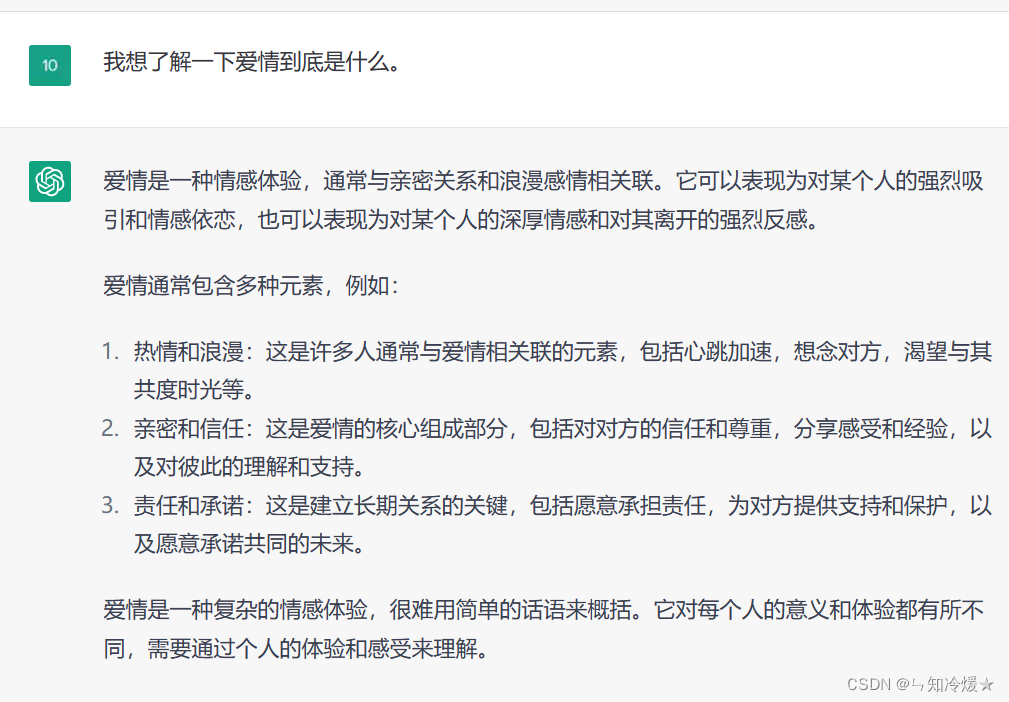
现在有一些小程序,让AI扮演一些角色对话,就是用这种方法实现的。

经常收到读者的私信,许多读者都想购买ChatGPT独立账号,这里为大家找到了一个比较优质的渠道,大家可以直接扫描下方二维码购买。

限时福利

本文来自程序员老鬼