7 Papers | 浙大研究获SIGMOD 2023最佳论文;GPT-4拿下最
机器之心 & ArXiv Weekly
参与:楚航、罗若天、梅洪源
本周论文包括 10% 成本定制专属类 GPT-4 多模态大模型;GPT-4 拿下最难数学推理数据集新 SOTA 等研究。
- Transfer Visual Prompt Generator across LLMs
- Progressive-Hint Prompting Improves Reasoning in Large Language Models
- AutoML-GPT: Automatic Machine Learning with GPT
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
- Unlimiformer: Long-Range Transformers with Unlimited Length Input
- Detecting Logic Bugs of Join Optimizations in DBMS
- REASONER: An Explainable Recommendation Dataset with Multi-aspect Real User Labeled Ground Truths
论文 1:Transfer Visual Prompt Generator across LLMs- 论文地址:https://arxiv.org/pdf/2305.01278.pdf
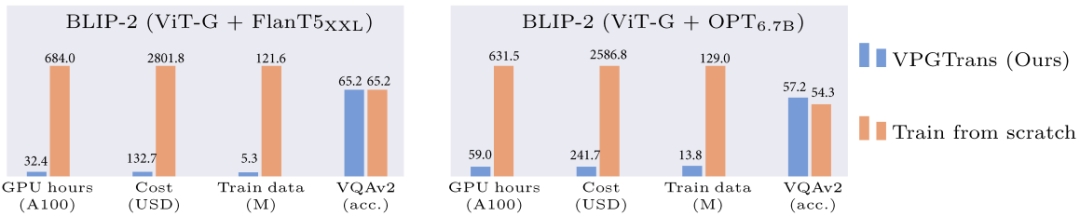
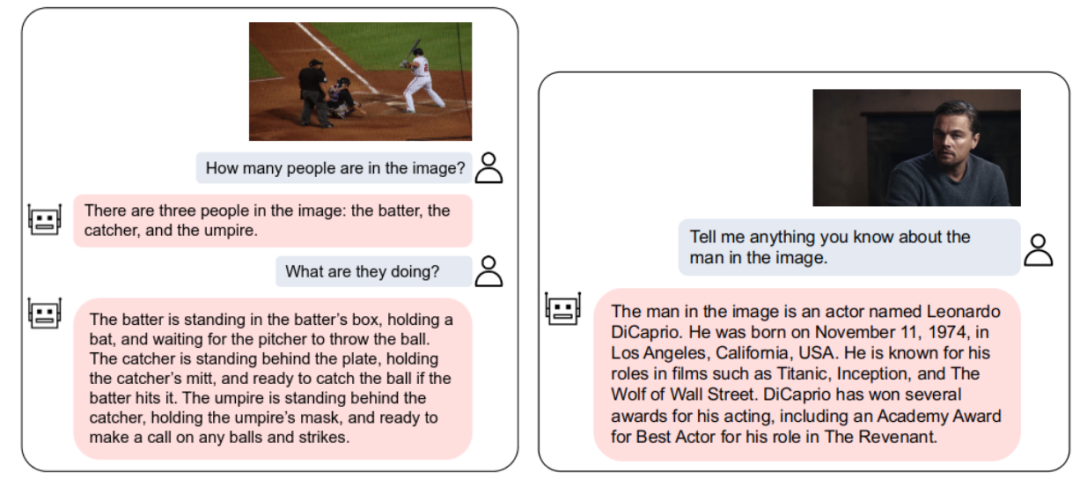
摘要:本文提出的 VPGTrans 方法,可以快速 (少于 10% 训练时间) 将已有的多模态对话模型的视觉模块迁移到新的语言模型,且达到类似或更优效果。比如,相比于从头训练视觉模块,本文可以将 BLIP-2 FlanT5-XXL 的训练开销从 19000 + 人民币缩减到不到 1000 元:通过 VPGTrans 框架可以根据需求为各种新的大语言模型灵活添加视觉模块。比如在 LLaMA-7B 和 Vicuna-7B 基础上制作了 VL-LLaMA 和 VL-Vicuna。开源多模态对话模型:本文开源了 VL-Vicuna,可实现高质量的多模态对话:推荐:10% 成本定制专属类 GPT-4 多模态大模型。论文 2:Progressive-Hint Prompting Improves Reasoning in Large Language Models- 作者:Chuanyang Zheng、Zhengying Liu 等
- 论文地址:https://arxiv.org/abs/2304.09797
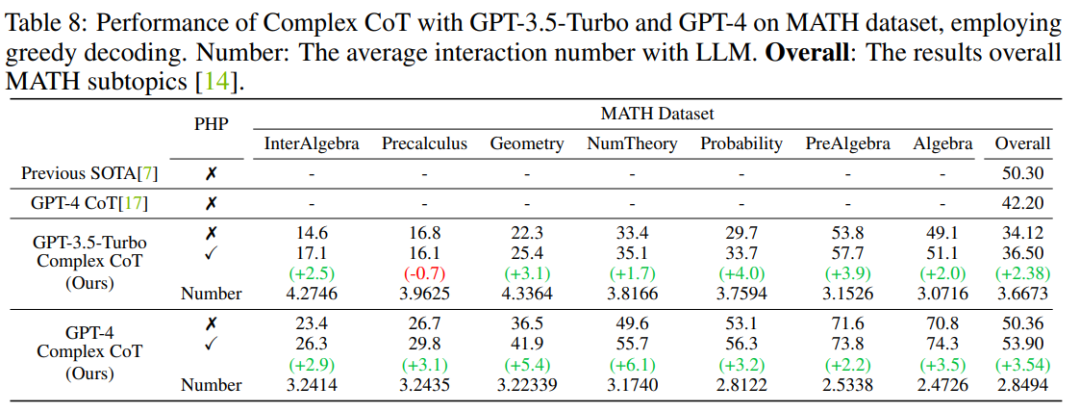
摘要:近期,华为联和港中文发表论文《Progressive-Hint Prompting Improves Reasoning in Large Language Models》,提出 Progressive-Hint Prompting (PHP),用来模拟人类做题过程。在 PHP 框架下,Large Language Model (LLM) 能够利用前几次生成的推理答案作为之后推理的提示,逐步靠近最终的正确答案。要使用 PHP,只需要满足两个要求: 1) 问题能够和推理答案进行合并,形成新的问题;2) 模型可以处理这个新的问题,给出新的推理答案。结果表明,GP-T-4+PHP 在多个数据集上取得了 SOTA 结果,包括 SVAMP (91.9%), AQuA (79.9%), GSM8K (95.5%) 以及 MATH (53.9%)。该方法大幅超过 GPT-4+CoT。比如,在现在最难的数学推理数据集 MATH 上,GPT-4+CoT 只有 42.5%,而 GPT-4+PHP 在 MATH 数据集的 Nember Theory (数论) 子集提升 6.1%, 将 MATH 整体提升到 53.9%,达到 SOTA。推荐:GPT-4 拿下最难数学推理数据集新 SOTA。论文 3:AutoML-GPT: Automatic Machine Learning with GPT- 作者:Shujian Zhang、Chengyue Gong 等
- 论文地址:https://papers.labml.ai/paper/35151be0eb2011edb95839eec3084ddd
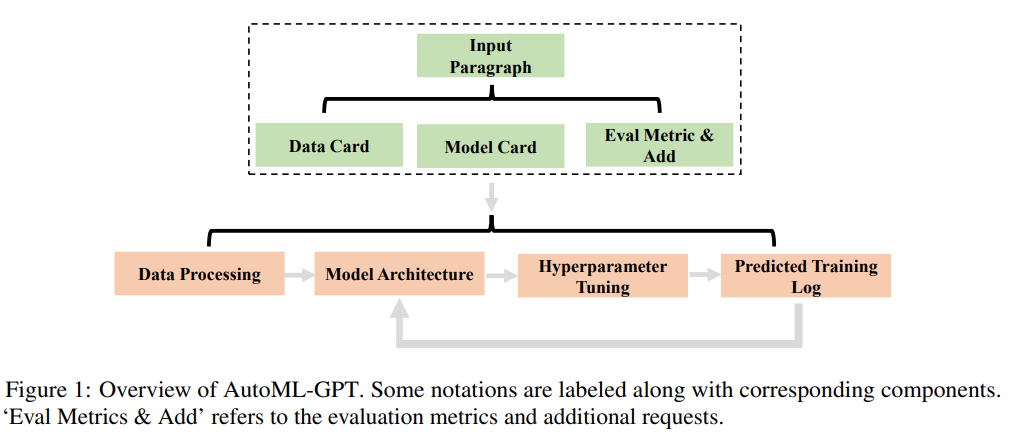
摘要:近期,来自德克萨斯州大学奥斯汀分校的研究者提出一种新思路 —— 开发任务导向型 prompt,利用 LLM 实现训练 pipeline 的自动化,并基于此思路推出新型系统 AutoML-GPT。AutoML-GPT 使用 GPT 作为各种 AI 模型之间的桥梁,并用优化过的超参数来动态训练模型。AutoML-GPT 动态地接收来自 Model Card [Mitchell et al., 2019] 和 Data Card [Gebru et al., 2021] 的用户请求,并组成相应的 prompt 段落。最后,AutoML-GPT 借助该 prompt 段落自动进行多项实验,包括处理数据、构建模型架构、调整超参数和预测训练日志。AutoML-GPT 通过最大限度地利用其强大的 NLP 能力和现有的人工智能模型,解决了各种测试和数据集中复杂的 AI 任务。大量实验和消融研究表明,AutoML-GPT 对许多人工智能任务(包括 CV 任务、NLP 任务)是通用的、有效的。论文 4:MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers- 作者:Lili Yu 、 Daniel Simig 等
- 论文地址:https://arxiv.org/pdf/2305.07185.pdf
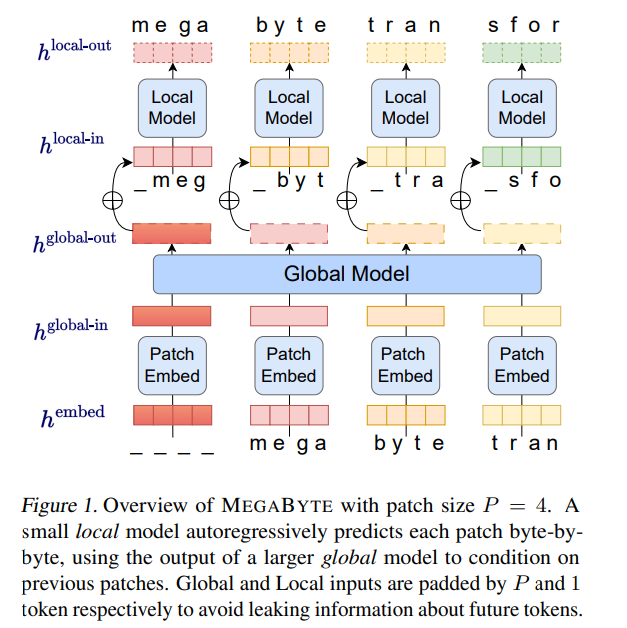
摘要:Meta AI 发表的一篇新论文,提出了一种名为「 MEGABYTE」的多尺度解码器架构,可以对超过一百万字节的序列进行端到端可微建模。重要的是,该论文展现出了抛弃 tokenization 的可行性,被 Karpathy 评价为「很有前途(Promising)」。该方法将字节序列分割成固定大小的 patch,和 token 类似。1. patch 嵌入器,它通过无损地连接每个字节的嵌入来简单地编码 patch;2. 全局模块 —— 带有输入和输出 patch 表征的大型自回归 transformer;3. 局部模块 —— 一个小型自回归模型,可预测 patch 中的字节。至关重要的是,该研究发现对许多任务来说,大多数字节都相对容易预测(例如,完成给定前几个字符的单词),这意味着没有必要对每个字节都使用大型神经网络,而是可以使用小得多的模型进行 intra-patch 建模。推荐:一定要「分词」吗?Andrej Karpathy:是时候抛弃这个历史包袱了。论文 5:Unlimiformer: Long-Range Transformers with Unlimited Length Input- 作者:Amanda Bertsch 、 Uri Alon 等
- 论文地址:https://arxiv.org/pdf/2305.01625v1.pdf
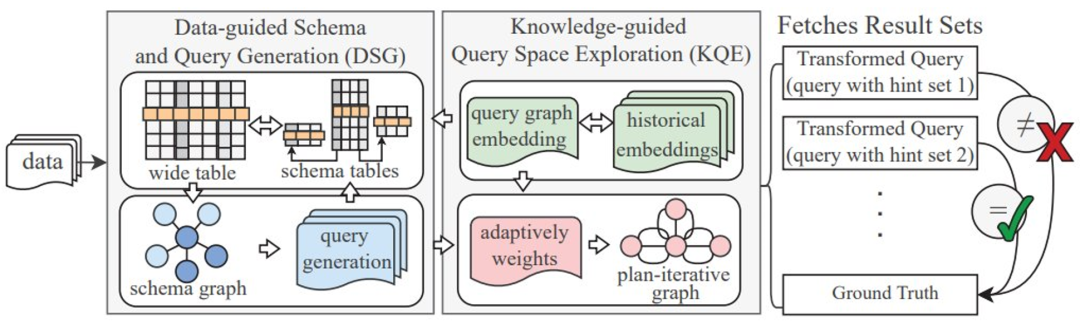
摘要:来自卡内基梅隆大学的研究者引入了 Unlimiformer。这是一种基于检索的方法,这种方法增强了预训练的语言模型,以在测试时接受无限长度的输入。Unlimiformer 可以被注入到任何现有的编码器 - 解码器 transformer 中,能够处理长度不限的输入。给定一个长的输入序列,Unlimiformer 可以在所有输入 token 的隐藏状态上构建一个数据存储。然后,解码器的标准交叉注意力机制能够查询数据存储,并关注前 k 个输入 token。数据存储可以存储在 GPU 或 CPU 内存中,能够次线性查询。Unlimiformer 可以直接应用于经过训练的模型,并且可以在没有任何进一步训练的情况下改进现有的 checkpoint。Unlimiformer 经过微调后,性能会得到进一步提高。本文证明,Unlimiformer 可以应用于多个基础模型,如 BART(Lewis et al.,2020a)或 PRIMERA(Xiao et al.,2022),且无需添加权重和重新训练。在各种长程 seq2seq 数据集中,Unlimiformer 不仅在这些数据集上比 Longformer(Beltagy et al.,2020b)、SLED(Ivgi et al.,2022)和 Memorizing transformers(Wu et al.,2021)等强长程 Transformer 表现更好,而且本文还发现 Unlimiform 可以应用于 Longformer 编码器模型之上,以进行进一步改进。推荐:Unlimiformer 把上下文长度拉到无限长。论文 6:Detecting Logic Bugs of Join Optimizations in DBMS摘要:浙大的研究者提出了一种名为 Transformed Query Synthesis(TQS)的方法。在检测 DBMS 中连接优化的逻辑漏洞任务上,TQS 是一种普适且成本高效的全新工具。为了展现该方法的通用性和有效性,研究者在四个常用 DBMS 上对 TQS 进行了评估:MySQL、MariaDB、TiDB 和 PolarDB。运行了 24 小时后,TQS 成功找到了 115 个漏洞,包括 MySQL 中 31 个、MariaDB 中 30 个、TiDB 中 31 个、PolarDB 中 23 个。通过分析根本原因,可归纳出这些漏洞的类型,其中 MySQL 中的漏洞有 7 种、MariaDB 有 5 种、TiDB 有 5 种、PolarDB 有 3 种。研究者已经将发现的漏洞提交给相应的社区并且收到了积极的反馈。图 2 给出了 TQS 的架构概况。给定一个基准数据集和目标 DBMS,TQS 通过基于数据集生成查询来搜索 DBMS 可能存在的逻辑漏洞。TQS 有两大关键组件:数据引导的模式和查询生成(DSG)和知识引导的查询空间探索(KQE):推荐:浙大研究获 SIGMOD 2023 最佳论文。论文 7:REASONER: An Explainable Recommendation Dataset with Multi-aspect Real User Labeled Ground Truths- 作者:Xu Chen 、 Jingsen Zhang 等
- 论文地址:https://arxiv.org/pdf/2303.00168.pdf
摘要:来自中国人民大学和华为的研究者联合构建了一个新的可解释推荐数据集 ——REASONER (Real Users Labeled Multi-aspect Explanations for Explainable Recommendation)。该数据集构建于视频推荐场景,包含了多种推荐解释目的的真值,例如,增强推荐说服力、解释信息量以及用户满意度等。可广泛应用于可解释推荐、推荐系统纠偏以及基于心理学的推荐等领域。同时,该研究也开发了一个可解释推荐工具包,包含了十个知名的可解释推荐模型方便大家使用。- 多模态的候选解释:用户可以根据自身偏好为每个推荐的视频选择文本解释或视觉解释。
- 多方面的解释真值:从推荐说服力、解释信息量和用户满意度三个方面提供推荐解释真值。
- 真实用户标注:数据集中的解释真值的标注者正是产生交互记录的人。
- 丰富的用户特征:该研究收集了参与用户的多方面的特征信息(已脱敏)。
推荐:多角度、真实用户标注,人大 & 华为推出可解释推荐数据集 REASONER。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com