- 长臂猿-企业应用及系统软件平台
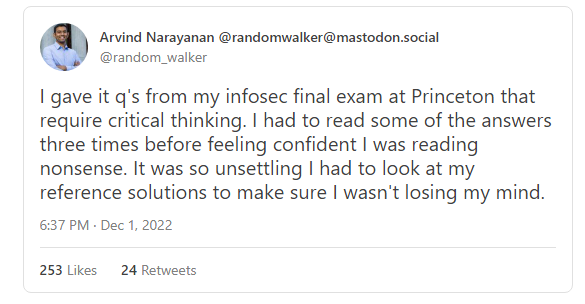
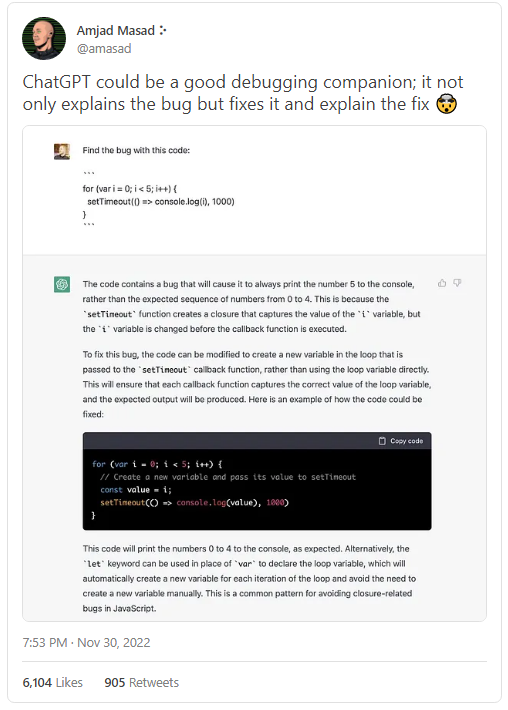
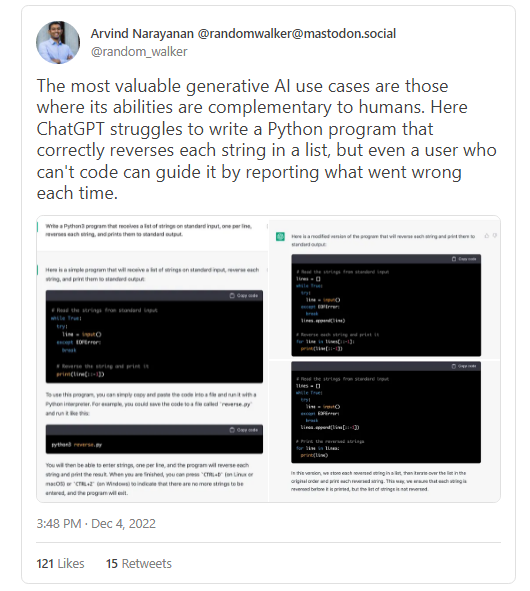
本文最初发布于 AI Snake Oil。 哲学家 Harry Frankfurt 将“胡话(bullshit )”定义为不考虑真相而旨在说服别人的言论。按照这个标准,OpenAI 的新聊天机器人 ChatGPT 是有史以来最能胡扯的。 大型语言模型(LLM)经过训练后可以生成貌似合理的文本,而不是正确的陈述。只要是你能想到的话题,ChatGPT 听起来都令人信服,它非常擅长这一点。 但 OpenAI 很清楚,训练过程并没有包含真相来源。也就是说,在教育或回答健康问题之类的应用程序中,以目前的形式使用 ChatGPT 不是一个好主意。尽管机器人经常能给出很好的答案,但有时也会完全失败。它总是很有说服力,所以很难区分。 不过,虽然在一般情况下,ChatGPT 和其他 LLM 都无法辨别真相,但在以下三类任务中,它们非常有用: 用户很容易检查机器人的答案是否正确的任务,例如调试帮助。 与真相无关的任务,比如写小说。 可以将实际存在的训练数据子集作为真相来源的任务,例如语言翻译。 让我们开始吧。先是坏消息,再是好消息。 ChatGPT 是迄今为止最好的聊天机器人。不久前,它生成了一些奇奇怪怪的文本,比如解释如何从录像机中取出花生酱三明治……按圣经的风格。 但人们对更严肃的应用场景也很感兴趣,比如将其用作学习工具。有些人甚至预测,谷歌将变得多余。是的,ChatGPT 通常非常擅长回答问题。但危险在于,除非你已经知道答案,否则你无法判断它什么时候是错的。 我们试着提了一些基本的信息安全问题。在大多数情况下,答案听起来似乎是合理的,但实际上是胡扯。下面是一些更复杂的问题: (阅读原推文:https://twitter.com/random_walker/status/1598385725363261441) 关于 ChatGPT 和教育,还有一个说法:大学注定要消亡,因为 ChatGPT 可以写论文。这样说很愚蠢。是的,LLM 可以写出似乎合理的论文。但是,家庭作业论文的消亡对学习而言是件好事!我们在一个月前写过一篇文章,最近也没什么实际的变化。 搜索呢?谷歌的知识面板已经因权威地提供错误信息而臭名昭著。用 LLM 取代它们可能会让事情变得更糟。Chirag Shah 和 Emily Bender 的一篇论文探讨了用 LLM 取代搜索引擎后会出什么错。 事实上,这些模型无法辨别真相,这就是我们说 Meta 面向科学的大型语言模型 Calactica 考虑不周的原因。在科学领域,准确性很重要。它很快就遭到了强烈的抵制,公开演示三天后被撤下。类似地,如果你想使用 LLM 回答与健康相关的查询,那么正确性和可靠性就是一切。 当然可以。但他们听起来令人信服的能力也在迅速提高!因此,我们怀疑,即使是专家也越来越难以发现错误。 事实上,像 Galactica 和 ChatGPT 这样的模型非常擅长按任何要求的风格生成听起来权威的文本:法律语言、官场语言、Wiki 页面、学术论文、课堂笔记,甚至问答论坛的答案。这产生的一个副作用是,我们不能再根据文本的形式来衡量其可信度和合理性。 StackOverflow 吃了不少苦头。在网站上,用户回答编程问题就可以获得积分,积分可以带来特权,包括减少广告和使用版主工具。在 ChatGPT 向公众公开发布后,问答论坛收到了数千个使用 LLM 生成的错误答案。但因为这些答案的书写风格是对的,所以必须经过专家审查才能删除。不到一周,该公司就不得不禁止使用 ChatGPT 生成的答案,以减少听起来似乎正确的错误答案。 除非 LLM 响应的准确性可以提高,否则我们推测,它在应用程序中的合理应用仍然会比较有限。请注意,GPT-3 已经有两年半的历史了。我们听到的是,这个领域每周都在进步,所以两年半就像几个世纪一样。当它发布时,人们满怀信心地预测,相关应用程序将出现“寒武纪大爆发”。但到目前为止,除了 GitHub Copilot 之外,还没有一个主流的应用程序。 准确性问题并非毫无希望。有趣的是,LLM 似乎在学习让人信服的过程中获得了一些辨别真相的能力。当研究人员要求 LLM 评估自己提出的答案的准确性时,它比随机应变地判断要好得多!为了提高生成答案的准确性,研究人员正在将这种能力整合到聊天机器人的默认行为中。 同时,下面有三种 LLM 非常适用的任务。 调试代码是一种可以让程序员(尤其是新手)从 LLM 中受益的应用。在这种情况下,LLM 指出的错误通常很容易验证,所以即使机器人的答案可能有时是错的,也不是一个太大的问题。 (阅读原推文:https://twitter.com/amasad/status/1598042665375105024) 生成代码很复杂。理论上,用户可以验证自动生成的代码是否有 Bug(可能在 LLM 的帮助下)。但目前还不清楚,这是否会比手动编码更快。安全漏洞是一个特别严重的问题。去年的一项研究发现,Copilot 生成不安全代码的概率为 40%。他们没有将这一数值与人类程序员进行比较,也没有就是否使用 Copilot 以及何时使用 Copilot 合适提供建议,但从结果中明显可以看出,需要谨慎使用。 Copilot 旨在提高专家的工作效率。那些不会编码的用户呢——他们能使用人工智能工具生成简单的脚本吗?这方面的承诺有很多。这里有一个小实验: (阅读原推文: https://twitter.com/random_walker/status/1599430575102001153) 使用 LLM 生成代码是一个活跃的研究领域。在提高代码生成的正确性以及减少 Bug 出现的频率方面,还有很大的改进空间。这是一个令人兴奋的领域。 ChatGPT 在上周已经成为了一种娱乐。从编写关于特定人物的笑话,到用智者快言快语的风格解释算法,人们发现了这个工具的许多创造性用途。但是,我们是否可以将 ChatGPT 用于更有野心的项目,比如写小说? LLM 还远不足以生成长篇文本,比如整部小说,因为它们一次只能存储少量的词元。尽管如此,作者和研究人员仍在尝试用它们来获得创意,扩展思路,以及改变文本的风格(例如,“重写这段文本,使其更像狄更斯写的”)。交互式小说游戏如 AI Dungeon 使用 LLM 基于用户输入充实故事情节。我们认为,在这一领域继续改进不存在什么根本性的障碍。 同样,文本转图像和图像转图像工具也非常适合娱乐,因为创作者可以调整提示信息,直到得到他们喜欢的图像。在最近兴起的应用程序 Lensa 中,用户只要上传几张自拍照,它就能生成各种风格的肖像。它后台使用了 Stable Diffusion,这是来自 Stability AI 的一个开源图像生成模型。 先不要得意忘形:种族主义、性别歧视和有偏见的输出仍然是所有生成模型(包括 ChatGPT)都面临的一个问题。该模型包含一个内容过滤器,可以拒绝不适当的请求,相对于以前的工具来说,它的效果已经足够好,感觉上有很大的改进,不过仍然有很长的路要走。 值得注意的是,GPT-3 的效果与专用语言翻译模型大致相当,ChatGPT 可能也一样。可能的原因是它可以利用语料库中的基本事实(大致包含网络上的所有文本)。例如,有些网页被翻译成多种语言。当然,在训练过程中,并没有显式的标签告诉模型哪些文本彼此对应,但模型很可能可以自动发现这一点。 目前,如果效果差不多,似乎也没有什么理由说聊天机器人会比谷歌等现有的翻译工具更好。一种可能性是,当两个说不同语言的人进行对话时,像 ChatGPT 这样的工具可以扮演传译员的角色,其优点是,在对话中使用的工具可以跟踪对话。这使它能够参考上下文,更有效地完成翻译,并且对用户来说不那么尴尬。 依托精心挑选的可以像病毒一样传播的例子,生成式 AI 的发布往往让人觉得印象深刻。但这还不是事情的全部。对于许多应用程序来说,即使是 10% 的失败率也太高了。似乎只有在相当有限的一组用例中,缺乏真相来源才不算是什么大问题。虽然这些用途仍然非常令人兴奋,但是,似乎还没有什么迹象表明,人们很快就会在日常生活中使用聊天机器人——用于学习,或作为搜索引擎替代品,或作为交谈对象。 与此同时,我们已经看到,LLM 的第一个突出应用是生成错误信息(Stack Overflow)。当然,垃圾邮件发送者已经在使用 GPT-3 进行搜索引擎营销,他们很高兴拥有 ChatGPT。但是,正如关于转型的预测被夸大了一样,我们不同意网络将很快淹没在错误信息的海洋中这样的说法。 我们期待看到人们创造性地使用 LLM,我们也对炒作和常见的自助服务 AGI 话题感到不安。 声明:本文为 InfoQ 翻译,未经许可禁止转载。 原文链接: https://aisnakeoil.substack.com/p/chatgpt-is-a-bullshit-generator-but

你也「在看」吗? ????
本文来自AI前线