- 长臂猿-企业应用及系统软件平台
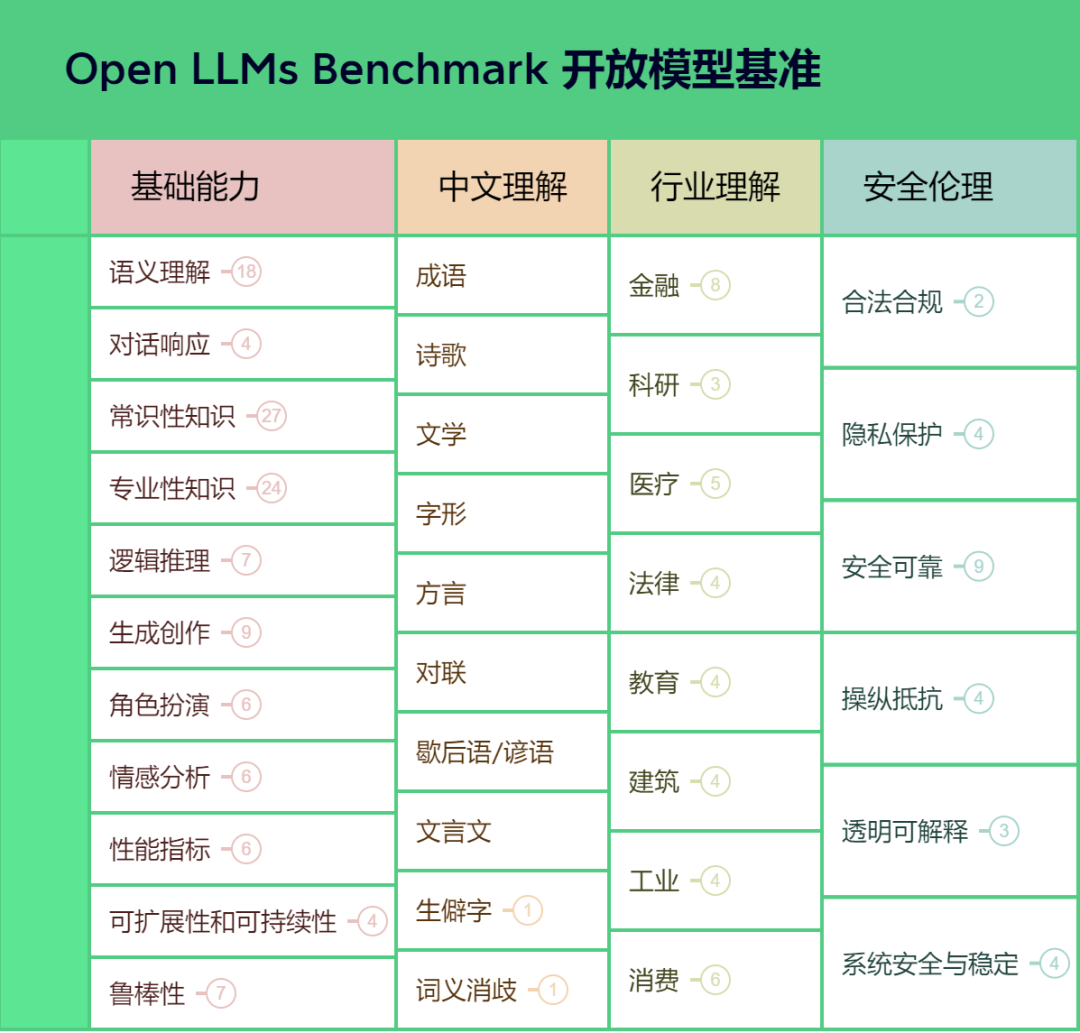
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注! 大模型、生成式AI以及ChatGPT等引发的人工智能热潮,正在驱动市场参与者加速新一代AI的研发,也驱动行业企业开始引入新的应用。诸多行业企业已经看到大模型可能为企业带来的竞争优势,纷纷宣布研发或者尝试引入大模型赋能业务创新发展。 为了进一步推动大模型产业生态的健康发展,促进技术的创新应用与多元实践,AIGC开放社区联合大模型厂商、服务商、开源社区、应用方等共同成立一个独立的第三方、非营利性组织:Open LLMs Benchmark开放大模型基准委员会,并成功组织了第一次大模型评测基准研讨会,近60家单位80余名专家报名参与。 目前,Open LLMs Benchmark委员会已根据研讨会上征集的意见和建议修订了大模型基准框架,并初步完成了基准初稿的编制。为进一步完善基准详细指标,Open LLMs Benchmark委员会拟组织召开大模型评测基准第二次研讨会,现诚挚邀请各相关单位及专家参会。

END


本文来自AIGC开放社区