- 长臂猿-企业应用及系统软件平台
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
 大模型引发的人工智能热潮,正在驱动市场参与者加速新一代AI的研发,也驱动行业企业开始引入新的应用。为了进一步推动大模型产业生态的健康发展,AIGC开放社区联合大模型厂商、服务商、开源社区、应用方等共同成立一个独立的第三方、非营利性组织:Open LLMs Benchmark开放大模型基准委员会。
大模型引发的人工智能热潮,正在驱动市场参与者加速新一代AI的研发,也驱动行业企业开始引入新的应用。为了进一步推动大模型产业生态的健康发展,AIGC开放社区联合大模型厂商、服务商、开源社区、应用方等共同成立一个独立的第三方、非营利性组织:Open LLMs Benchmark开放大模型基准委员会。
5月31日,Open LLMs Benchmark委员会顺利召开大模型评测基准第二次研讨会,来自委员会的40余位行业专家参会。会议由Open LLMs Benchmark委员会秘书处陈龙负责主持。
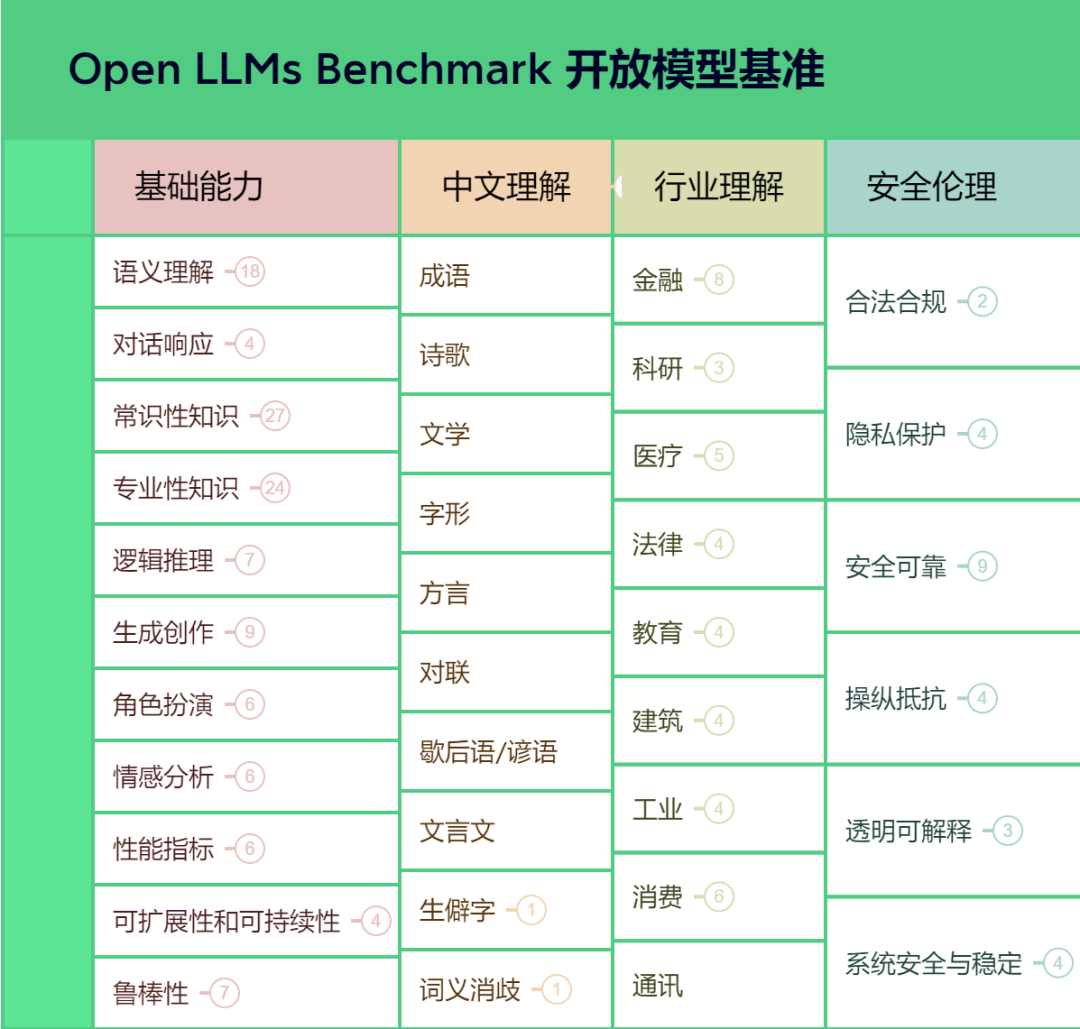
AIGC开放社区负责人郭政纲首先对当前基准推进工作进行了总结,并且对基准框架做了详细介绍,最后介绍了整个基准工作的安排。
根据初次研讨会以及反馈意见,基准修订包含以下内容:
1、针对基准的定位,聚焦于大语言模型,侧重中文语境、行业能力、安全伦理范畴;
2、基础能力增加性能指标、可扩展性与可持续性、鲁棒性指标;
3、针对专业性知识与行业能力的区别,划分明确边界与细分指标;
4、对于常识性知识和专业知识进一步明确边界和指标;
5、增加科研行业能力基准,主要包含代码分析、文献辅助阅读、实验方案撰写与步骤咨询;
6、关于涌现能力,基于目前框架,融入基础能力与行业能力评测之中,比如对话响应能力,生成创作能力,以及零样本学习能力、泛化能力等。
会上,来自三井住友的陈婧和mesen带来大模型企业应用实践的分享。结合自身业务需要,对大模型在中文支持、资料检索、逻辑推理、算力消耗和易用性等方面给出评价,内容翔实,为企业部署大模型带来广泛的借鉴意义。
南京航空航天大学陈钢教授带来以《基于EDA的生成式大模型通用测评标准设计及初步测评结果》的主题分享。提出评测四项原则,并展示了详细的评测过程及结果,为大模型评测工作带来非常有价值的思考。
中兴通讯王长金分享了对于当前基准框架的看法并提出了建议。
腾讯许良晟分享了大模型评测的实践和经验,对基准工作表示了支持。
本次会议对大模型评测基准进行了全面介绍,明确了大模型基准的框架。未来,Open LLMs Benchmark委员会将密切跟踪大模型前沿动态,组建相关基准推进组,持续开展技术研究、基准研制、评估测试、产业交流等工作。
Open LLMs Benchmark委员会欢迎更多行业专家的加入。
点击阅读原文,或者扫描下方二维码提交申请加入委员会:

关于Open LLMs Benchmark委员会
随着近年来人工智能技术的飞速发展,尤其是深度学习领域的突破,大型语言模型(LLMs)已经成为了研究和应用的热点。这些模型在自然语言处理、机器翻译等领域取得了显著的成果。然而,随着模型规模的不断扩大,如何对这些大模型进行有效、公平、可靠的评测,已经成为了业界关注的重要问题。
为了解决这一问题,AIGC开放社区联合大模型厂商、服务商、开源社区、应用方等共同成立一个独立的第三方、非营利性组织:Open LLMs Benchmark开放大模型基准委员会,旨在构建一个公开、透明、可靠的大模型评测基准,为全球相关研究者、开发者和企业提供参考。
联系方式:
郭政纲
13260410653
nero@aigcopen.com
陈 龙
13226611521
chenlong@aigcopen.com
END

本文来自AIGC开放社区