- 长臂猿-企业应用及系统软件平台
机器之心报道
大语言模型处理上下文 token 的能力,是越来越长了。
今年 2 月,Meta 发布的 LLaMA 大型语言模型系列,成功推动了开源聊天机器人的发展。因为 LLaMA 比之前发布的很多大模型参数少(参数量从 70 亿到 650 亿不等),但性能更好,例如,最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B,所以一经发布让很多研究者兴奋不已。
然而,LLaMA 仅授权给学术界的研发人员使用,从而限制了该模型的商业应用。
因而,研究者开始寻找那些可用于商业用途的 LLaMA,UC 伯克利的博士生 Hao Liu 发起的项目 OpenLLaMA,就是其中一个比较热门的 LLaMA 开源复制品,其使用了与原始 LLaMA 完全相同的预处理和训练超参数,可以说 OpenLLaMA 完全按照 LLaMA 的训练步骤来的。最重要的一点是,该模型可商用。
OpenLLaMA 在 Together 公司发布的 RedPajama 数据集上训练完成,有三个模型版本,分别为 3B、7B 和 13B,这些模型都经过了 1T tokens 的训练。结果显示,OpenLLaMA 在多项任务中的表现都与原始 LLaMA 相当,甚至有超越的情况。
除了不断发布新模型,研究者对模型处理 token 的能力探索不断。
几天前,田渊栋团队的最新研究用不到 1000 步微调,将 LLaMA 上下文扩展到 32K。再往前追溯,GPT-4 支持 32k token(这相当于 50 页的文字) ,Claude 可以处理 100k token (大概相当于一键总结《哈利波特》第一部)等等。
现在,一个新的基于 OpenLLaMA 大型语言模型来了,它将上下文的长度扩展到 256k token,甚至更多。该研究由 IDEAS NCBR 、波兰科学院、华沙大学、 Google DeepMind 联合完成。

LongLLaMA 基于 OpenLLaMA 完成,微调方法采用 FOT ( Focused Transformer )。本文表明,FOT 可以用于对已经存在的大型模型进行微调,以扩展其上下文长度。
该研究以 OpenLLaMA-3B 和 OpenLLaMA-7B 模型为起点,并使用 FOT 对它们进行微调。由此产生的模型称之为 LONGLLAMAs,能够在其训练上下文长度之外进行外推(甚至可以达到 256K),并且在短上下文任务上还能保持性能。

项目地址:https://github.com/CStanKonrad/long_llama
论文地址:https://arxiv.org/pdf/2307.03170.pdf
有人将这一研究形容为 OpenLLaMA 的无限上下文版本,借助 FOT,模型很容易外推到更长的序列,例如在 8K token 上训练的模型,可以很容易外推到 256K 窗口大小。

本文用到了 FOT 方法,它是 Transformer 模型中一种即插即用的扩展,可用于训练新模型,也可对现有的较大模型进行更长上下文微调。
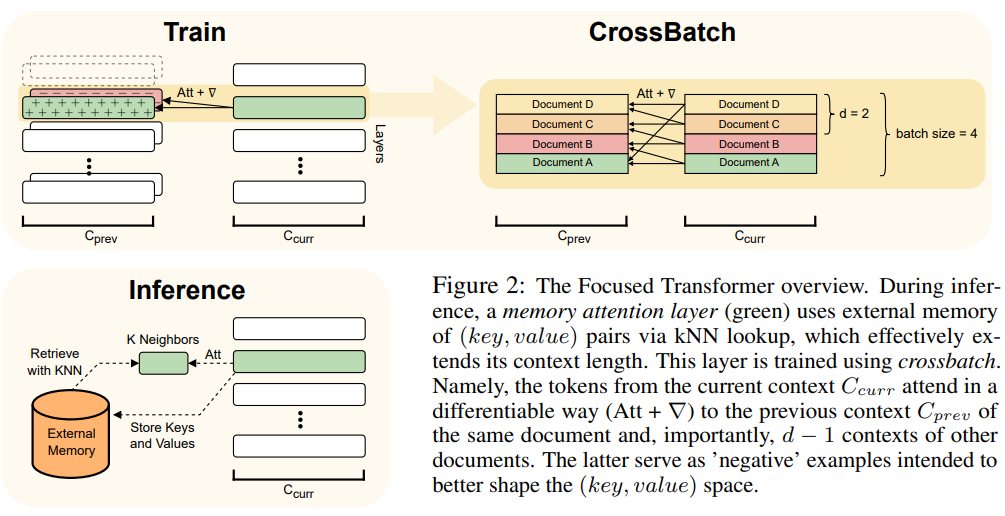
为了达到这一目的,FOT 使用了记忆注意力层和跨批次(crossbatch)训练过程:
记忆注意力层使模型能够在推理时从外部存储器中检索信息,从而有效地扩展了上下文;
跨批次训练过程使模型倾向于学习(键,值)表示,这些表示对于记忆注意力层的使用非常简便。
有关 FOT 架构的概述,请参见图 2:
下表为 LongLLaMA 的一些模型信息:

最后,该项目还提供了 LongLLaMA 与原始 OpenLLaMA 模型的比较结果。
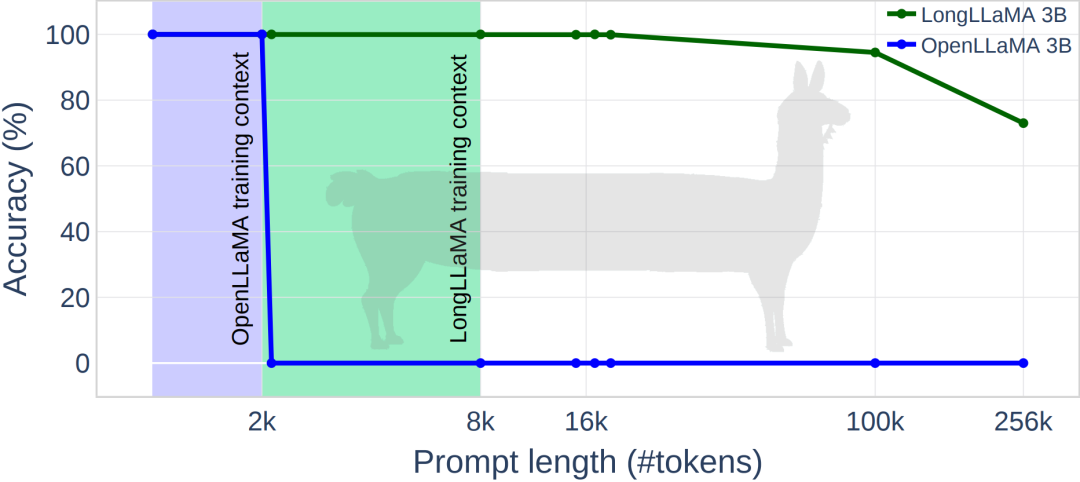
下图为 LongLLaMA 一些实验结果,在密码检索任务上,LongLLaMA 取得了良好的性能。具体而言,LongLLaMA 3B 模型远远超出了它的训练上下文长度 8K,对于 token 为 100k 时,准确率达到 94.5%,当 token 为 256k 时,准确率为 73%。
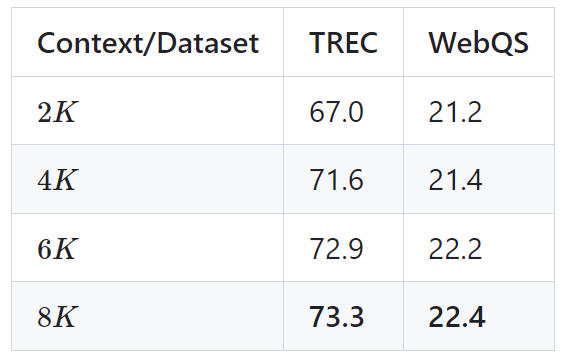
下表为 LongLLaMA 3B 模型在两个下游任务(TREC 问题分类和 WebQS 问题回答)上的结果,结果显示,在使用长上下文时,LongLLaMA 性能改进明显。
下表显示了即使在不需要长上下文的任务上,LongLLaMA 也能表现良好。实验在零样本设置下,对 LongLLaMA 和 OpenLLaMA 进行了比较。

了解更多细节,可参考原论文与项目。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
本文来自机器之心