- 长臂猿-企业应用及系统软件平台
机器之心专栏 本文将分 3 期进行连载,共介绍 17 个在OCR任务上曾取得 SOTA 的经典模型。 第 1 期:CTPN、TextBoxes、SegLink、RRPN、FTSN、DMPNet 第 2 期:EAST、PixelLink、TextBoxes++、DBNet、CRNN、RARE 第 3 期:ABCNet、Deep TextSpotter、SEE、FOTS、End-to-End TextSpotter 您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。模型 SOTA!模型资源站收录情况 模型来源论文 CTPN https://sota.jiqizhixin.com/project/ctpn
收录实现数量:3
支持框架:PyTorch、TensorFlowDetecting Text in Natural Image with Connectionist Text Proposal Network TextBoxes https://sota.jiqizhixin.com/project/textboxes TextBoxes: A Fast Text Detector with a Single Deep Neural Network SegLink https://sota.jiqizhixin.com/project/seglink-2
收录实现数量:2
支持框架:TensorFlowDetecting Oriented Text in Natural Images by Linking Segments RRPN https://sota.jiqizhixin.com/project/rrpn
收录实现数量:1
支持框架:PyTorchArbitrary-Oriented Scene Text Detection via Rotation Proposals FTSN https://sota.jiqizhixin.com/project/ftsn Fused Text Segmentation Networks for Multi-oriented Scene Text Detection DMPNet https://sota.jiqizhixin.com/project/dmpnet Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection
光学字符识别(Optical Character Recognition,OCR)是指对文本资料进行扫描后对图像文件进行分析处理,以获取文字及版面信息的过程。一般来说,在获取到文字之前需要首先对文字进行定位,即执行文本检测任务,将图像中的文字区域位置检测出来;在找到文本所在区域之后,对该区域中的文字进行文字识别。文字识别就是通过输入文字图片,然后解码成文字的方法。OCR解码是文字识别中最为核心的问题。传统技术解决方案中,分别训练文本检测和文字识别两个模型,然后在实施阶段将这两个模型串联到数据流水线中组成图文识别系统。
对于文本检测任务,主要包括两种场景,一种是简单场景,另一种是复杂场景。简单场景主要是对印刷文件等的文本检测,例如像书本扫描、屏幕截图,或是清晰度高、规整的照片等。由于印刷字体的排版很规范,背景清晰,现在的检测、识别技术已经很成熟了,检测的效果都比较好。通过利用计算机视觉中的图像形态学操作,包括膨胀、腐蚀基本操作,即可实现简单场景的文字检测。复杂场景主要是指自然场景,由于光照环境以及文字存在着很多样的形式,例如灯箱广告牌、产品包装盒、设备说明、商标等,存在角度倾斜、变形、背景复杂、光线忽明忽暗、清晰度不足等情况,这时要将文本检测出来难度就比较大了,此时主要考虑引入深度学习模型进行检测。
对于文字识别任务,一般由下面的步骤组成:首先是读取输入的图像,提取图像特征,因此,需要有个卷积层用于读取图像和提取特征;然后,由于文本序列是不定长的,因此需要处理不定长序列预测的问题;再次,为了提升模型的适用性,最好不要要求对输入字符进行分割,直接可进行端到端的训练,这样可减少大量的分割标注工作,这时就要引入 CTC 模型(Connectionist temporal classification, 联接时间分类)来解决样本的分割对齐的问题;最后,根据一定的规则,对模型输出结果进行纠正处理,输出正确结果。
最近流行的技术解决方案中,考虑用一个多目标网络直接训练出一个端到端的模型以替代两阶段模型。在训练阶段,端到端模型的输入是训练图像及图像中的文本坐标、文本内容,模型优化目标是输出端边框坐标预测误差与文本内容预测误差的加权和。在实施阶段,原始图像经过端到端模型处理后直接输出预测文本信息。相比于传统方案,该方案中模型训练效率更高、资源开销更少。
我们在这篇报告中分别总结了OCR中必备的文本检测模型、文字识别模型和端到端的方法。其中,文本检测模型主要考虑复杂场景中的深度学习模型。
一、文本检测模型
CTPN( Connectionist Text Proposal Network )是在ECCV 2016中提出的一种文本检测模型。CTPN是从Faster RCNN改进而来的,结合了CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,是非常经典的文本检测模型。CTPN是基于Anchor的算法,在检测横向分布的文字时能得到较好的效果。CTPN结构与Faster R-CNN基本类似,但是加入了LSTM层。
假设输入N张图片,首先,利用VGG提取特征,获得大小为 N×C×H×W 的conv5 feature map;然后,在conv5上做3×3 的滑动窗口,即每个点都结合周围3×3 区域特征以获得一个长度为3×3×C 的特征向量。输出N×9C×H×W 的feature map,该特征显然只有CNN学习到的空间特征;再将这个feature map进行Reshape,Reshape: Nx9CxHxW→(NH)xWx9C;然后,以Batch=NH 且最大时间长度Tmax=W 的数据流输入双向LSTM,学习每一行的序列特征。双向LSTM输出(NH)×W×256 ,再经Reshape恢复形状:Reshape: (NH)xWx256→Nx256xHxW,该特征既包含空间特征,也包含了LSTM学习到的序列特征;然后经过“FC”卷积层,变为N×512×H×W 的特征;最后经过类似Faster R-CNN的RPN网络,获得text proposals。
 图1(a) CTPN结构。通过VGG16模型的最后一个卷积图(conv5)密集地滑动一个3×3的空间窗口。每行的顺序窗口由双向LSTM(BLSTM)循环连接,其中每个窗口的卷积特征(3×3×C)被用作256D BLSTM(包括两个128D LSTM)的输入。RNN层连接到512D全连接层,然后是输出层,共同预测文本/非文本分数、y轴坐标和k个anchor的side-refinement偏移。(b)CTPN输出连续的固定宽度的细刻度文本建议。每个box的颜色表示文本/非文本得分。最终只呈现正分数的方框
图1(a) CTPN结构。通过VGG16模型的最后一个卷积图(conv5)密集地滑动一个3×3的空间窗口。每行的顺序窗口由双向LSTM(BLSTM)循环连接,其中每个窗口的卷积特征(3×3×C)被用作256D BLSTM(包括两个128D LSTM)的输入。RNN层连接到512D全连接层,然后是输出层,共同预测文本/非文本分数、y轴坐标和k个anchor的side-refinement偏移。(b)CTPN输出连续的固定宽度的细刻度文本建议。每个box的颜色表示文本/非文本得分。最终只呈现正分数的方框
CTPN网络最后输出的预测参数包括三部分:纵向坐标(vertical coordinates),表示每一个box的中心点x坐标和高度;分数(scores),表示是否是文本区域的置信度;水平偏移量(side-refinement)用于精修文本框的左右边缘部分,表示对于左右两侧边界处box的坐标偏移值。具体的数量如下:2k个vertical coordinate,因为一个anchor用的是中心位置的高(y坐标)和矩形框的高度两个值表示的,所以一共2k个输出。2k个score,因为预测了k个text proposal,所以有2k个分数,text和non-text各有一个分数。k个side-refinement,这部分主要是用来精修文本行的两个端点的,表示的是每个proposal的水平平移量。这样就可以得到一个密集预测的text proposal,接下来使用一个标准的非极大值抑制算法(NMS)来滤除多余的box。最后使用基于图的文本行构造算法,将得到的文本段合并成文本行。构造文本行的方法是,令每两个相近的anchor组成一个pair,然后合并不同的pair直到无法再合并,这就构成了一个文本区域。
最后,CTPN 的 loss 分为三部分:(1)预测每个 anchor 是否包含文本区域的classification loss;(2)文本区域中每个 anchor 的中心y坐标cy与高度h的regression loss;(3)文本区域两侧 anchor 的中心x坐标cx 的regression loss。
| 项目 | SOTA!平台项目详情页 |
|---|---|
CTPN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/ctpn |
TextBoxes 是一个端到端可训练的快速文本检测算法,是改进版的SSD。TextBoxes整体网络结构如图2所示,TextBoxes共有28层卷积,前13层来自于VGG-16(conv_1到conv4_3),后接9个额外的卷积层,最后是包含6个卷积层的多重输出层,被称为text-box layers,分别和前面的9个卷积层相连。由于这些default box都是细长型的,使得box在水平方向密集在垂直方向上稀疏,从而导致该模型对水平方向上的文字检测结果较好。text-box layers的输出通道数是72(2个通道预测分数,4个通道预测位置偏移量,共12个anchor,所以共(2+4) x 12=72个通道),整合所有的 text-box layers的输出结果后再使用NMS( nonmaximum suppression )处理,就得到了最终的结果。
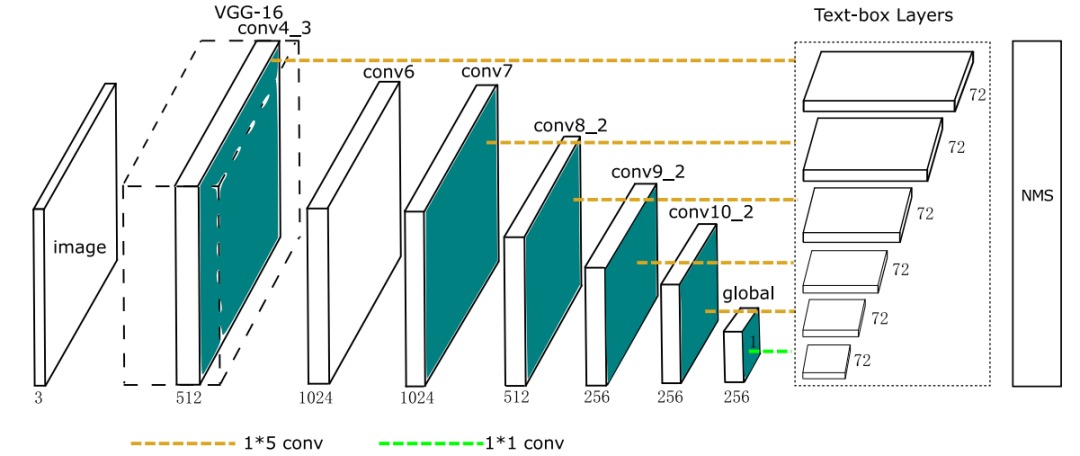 图2 TextBoxes架构。TextBoxes是一个28层的全卷积网络。其中,13层是继承自VGG-16。9个额外的卷积层被附加在VGG-16层之后。文本框层与其中6个卷积层相连。在每个map位置上,一个文本框层预测了一个72维的向量,即12个默认框的文本存在分数(2维)和偏移量(4维)。对所有文本框层的汇总输出进行了NMS处理
图2 TextBoxes架构。TextBoxes是一个28层的全卷积网络。其中,13层是继承自VGG-16。9个额外的卷积层被附加在VGG-16层之后。文本框层与其中6个卷积层相连。在每个map位置上,一个文本框层预测了一个72维的向量,即12个默认框的文本存在分数(2维)和偏移量(4维)。对所有文本框层的汇总输出进行了NMS处理
Text-box layer是TextBoxes的核心,同时负责两种预测:文本行/非文本行预测和文本行的bbox预测,在每个特征图的每个位置上,它同时输出文本行的概率及其相对于default box的偏移。对于bbox的预测公式如下:
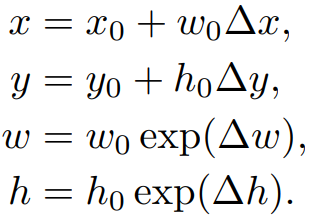
训练图像中文本行的ground truth与default box的匹配原则,采用的也是box overlap。这有效地将文本行按照各自的尺寸和宽高比进行划分。为了更好地适应文本行的large aspect ratio,论文中设计长宽比分别是1、2、3、5、7、10的default box(即长条形的default box)。但同时也引入了另外一个问题:default box在水平方向上排列紧密而垂直方向上排列稀疏,这会造成检测失误的情况。针对上述问题,论文中将水平方向上的这些默认框全部向下平移半个区域的单位(图3中黑色与绿色,蓝色与红色),这样一个位置总共12个默认框,解决了默认框排列不均匀的问题。
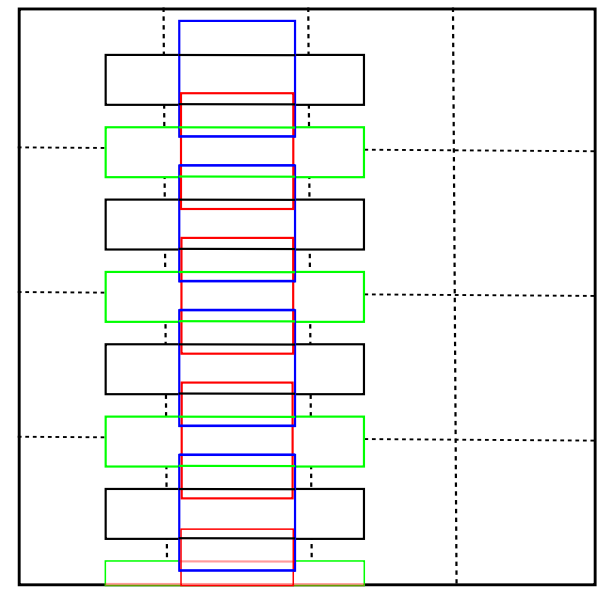
图3 4 x 4网格的默认box说明。为了更好的可视化,只绘制了一列长宽比为1和5的默认框。其余的长宽比为2、3、7和10,它们的位置类似。黑色(ar:5)和蓝色(ar:1)的默认框在其单元格中居中。绿色(ar:5)和红色(ar:1)方框具有相同的长宽比,并分别与网格中心有一个垂直偏移(单元格高度的一半)
此外在 text-box layers中替换传统的33卷积为不规则的15和5x1卷积核,这种 inception-style过滤器生成矩形接收场,更好地适合具有较大纵横比的文本,也避免了方形接收场会带来的噪声信号。
损失函数方面,TextBoxes的损失函数由两部分构成,一是二分类的损失函数,由于TextBoxes只会把区域分成两类,一类是背景,一类含有文字,因此这部分是一个二分类的softmax损失函数。二是预测的bounding box位置的回归损失,这部分使用的是smooth L1损失函数。
检测过程中可能会遇到文字区域过长,超过了默认框的最大比例的问题,即使在anchor和卷积滤波器上进行优化,也仍然很难检测出极端纵横比和大小的文本。解决办法是将原图片放缩到不同的大小(对于每张图片,分别rescale到300300,700700,300700,500700,1600 x 1600),这样某些在水平方向很长的文字就会被挤压从而满足默认框的比例,这种方法提高了检测的准确度,但是会消耗一定的运算能力。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| TextBoxes | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/textboxes |
SegLink将检测文本行的任务分解为检测segment和link的两个小任务,依然是采用了SSD结构,重点是改变了网络的输出,即数据的表现形式,然后融合两个小任务的结果最终输出文本行。完整结构如图4。
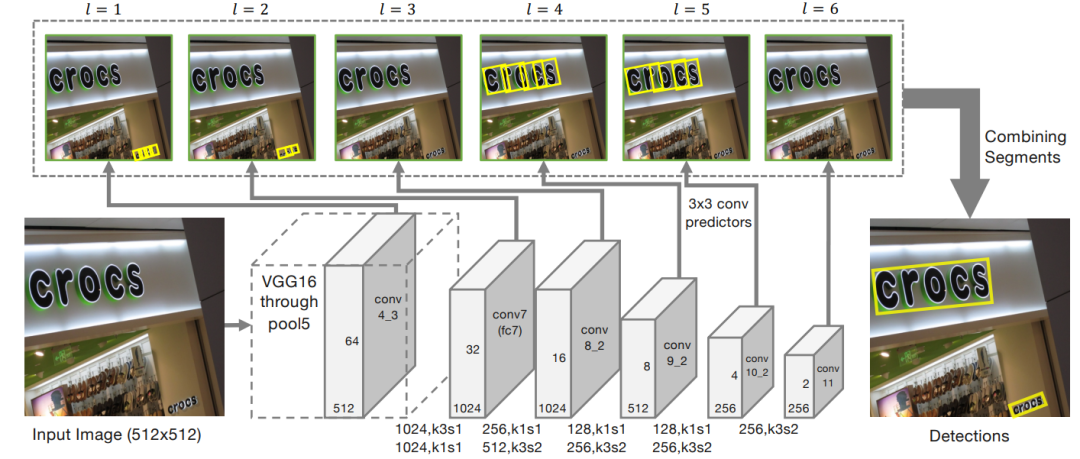 图4 SegLink网络结构。网络由卷积特征层(显示为灰色块)和卷积预测器(灰色细箭头)组成。卷积滤波器的格式为"(#filters),k(kernel size)s(stride)"。一个多行过滤器规格意味着一个隐藏层之间。分段(黄框)和链接(未显示)由卷积预测器在多个特征层(以l = 1 ... 6为索引)上检测,并通过组合算法组合成整个单词
图4 SegLink网络结构。网络由卷积特征层(显示为灰色块)和卷积预测器(灰色细箭头)组成。卷积滤波器的格式为"(#filters),k(kernel size)s(stride)"。一个多行过滤器规格意味着一个隐藏层之间。分段(黄框)和链接(未显示)由卷积预测器在多个特征层(以l = 1 ... 6为索引)上检测,并通过组合算法组合成整个单词
SegLink的完整工作流程如下:
主干网络沿用SSD网络结构,修改了最后的Pooling层,将其改为卷积层.具体来说:首先,用VGG16作为base net,并将VGG16的最后两个全连接层改成卷积层。接着增加一些额外的卷积层,用于提取更深的特征,最后,修改SSD的池化层,将其改为卷积层;
提取不同层的特征图,文中提取了conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11;
对不同层的特征图使用3x3的卷积层以得到最终的输出,不同特征层输出的维度是不一样的,因为除了conv4_3层外,其它层存在跨层的link。这里segment是text的带方向bbox信息,link是不同bbox的连接信息;
通过融合规则,将segment的box信息和link信息进行融合,得到最终的文本行。
Segments表示一个文本框里的一个部分,可以是一个文字也可以是多个文字。segment是一个增加了方向信息的五元组x、y、w、h、θ,分别表示:中心的坐标,矩形框的宽高,矩形框的角度。在SSD中,每个特征图的每一个像素会生成多个default box,但是在seglink中,只有一个宽高比为1的default box。对于segments的预测包括:2个segment score和5个geometric offsets(xs,ys,ws,hs,θs)。
link主要是用于连接上述segment,对于link detection部分,主要分成层内link检测(within-layer)和跨层link检测(cross-layer),分别表示特征图内和跨特征图的segment是否应该相连。每个link有两个分数,一个用是正分,一个是负分,正分用来表示二者是否属于同一个单词;负分表示二者是否属于不同单词,应该断开连接。Within-Layer Link:衡量了每一个特征图内部的segment是否应该相连,对于当前的segment,会寻找其八邻域内的segment是否与其相连。Cross-Layer Link:衡量了当前特征图和其上一级特征图内部的segment是否应该相连,对于当前的segment,会寻找其四邻域内的segment是否与其相连。如l6 层和l5 层, 所以只需要对conv7, conv8_2, conv9_2, conv10_2, conv11进行cross-layer link检测。
Combining Segments with Links算法的流程是:首先,通过人工设定的两个参数 α 和β对网络预测的segments和links进行滤除;然后,将每个segment看成节点,link看成边,建立图模型,再用DFS(depth first search)找到连通分量,每个连通分量包含一系列segments(用B表示),执行Alg1进行融合输出单词的box,Alg1算法其实就是一个平均的过程。先计算所有的segment的平均θ作为文本行的θ,再根据已求的θ为已知条件,求出最可能过每个segment的直线,以segment的最左和最右为边界的线段中点作为word的中心点(x, y),最后用线段长度加上首尾segment的平均宽度作为word的宽度,用所有segment的高度的平均值作为word的高度。

| 项目 | SOTA!平台项目详情页 |
|---|---|
SegLink | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/seglink-2 |
RRPN(Rotation Region Proposal Network)即基于文本倾斜角信息的旋转区域建议网络,是一种基于旋转的自然场景图像任意文本检测框架,能够基于旋转的方法和一个端到端的文本检测系统来进行任意方向的文本检测。
框架结构
RRPN框架的主要结构如下:在框架的前面使用了VGG-16的卷积层,它由两个兄弟分支共享,即最后一个卷积层的特征映射的克隆和RRPN。RRPN为文本实例生成面向任意性的建议,并进一步对建议bounding box进行回归,以更好地适应文本实例。从RRPN分支出来的同级层是RRPN的分类层(cls)和回归层(reg)。这两层的输出是来自cls的分数和来自reg的坐标信息,计算和汇总它们的Loss函数以形成一个多任务损失函数。然后,通过将来自RRPN的任意方向的文本建议投射到特征图上,RRoI pooling层作为特征汇集层。最后,使用两个全连接层构成的分类器,将具有RRoI特征的区域分为文本和背景。具体如图5所示。
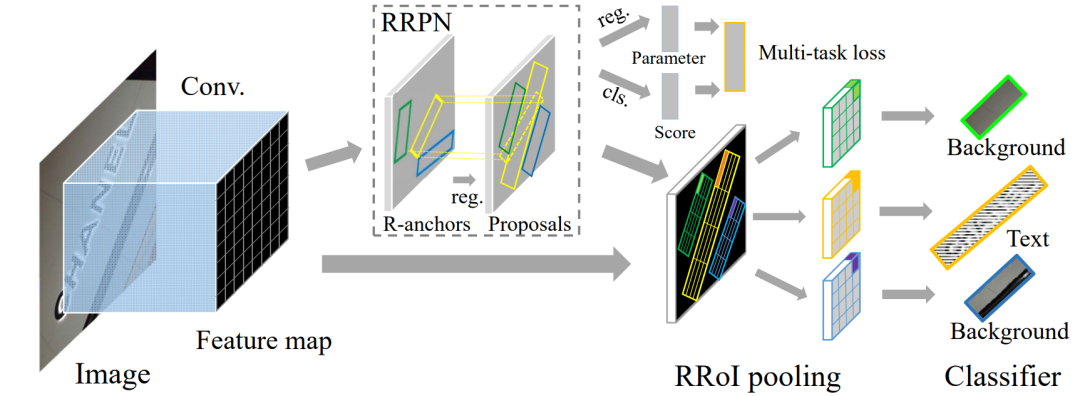 图5 基于旋转的文本检测管道
图5 基于旋转的文本检测管道
R-Anchor
传统的RPN的anchor均是与坐标轴平行的矩形,而RRPN中添加了角度信息,将这样的锚点叫做R-Anchor。R-Anchor由(x,y,w,h,θ) 五要素组成,其中,(x,y) 表示bounding box的几何中心(RPN中是左上角)。(w,h) 分别是bounding box的长边和短边。θ 是anchor的旋转角度,通过θ+kπ 将θ 的范围控制在[−π4,3π4) 。
图像扩充
为了缓解过拟合的问题,作者增加了模型对选择区域的检测能力,RRPN使用了数据扩充的方法增加样本的数量。RRPN使用的扩充方法之一是:对于一张尺寸为I_W×I_H 的输入图像,设其中一个Ground Truth表示为(x,y,w,h,θ) ,旋转α 后得到的Ground Truth为(x′,y′,w′,h′,θ′) ,其中,Ground Truth的尺寸并不会改变,即w′=w ,h′=h 。θ′=θ+α+kπ ,kπ 用于将θ′ 的范围控制到[−π4,3π4) 之间。(x′,y′) 的计算方式为:
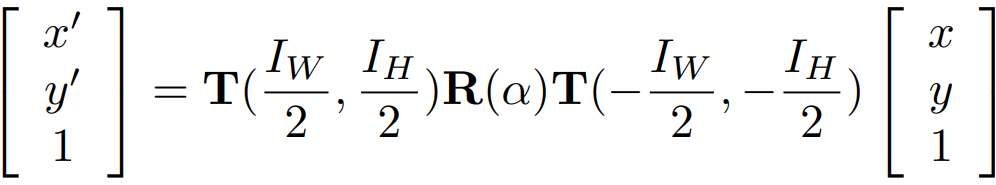
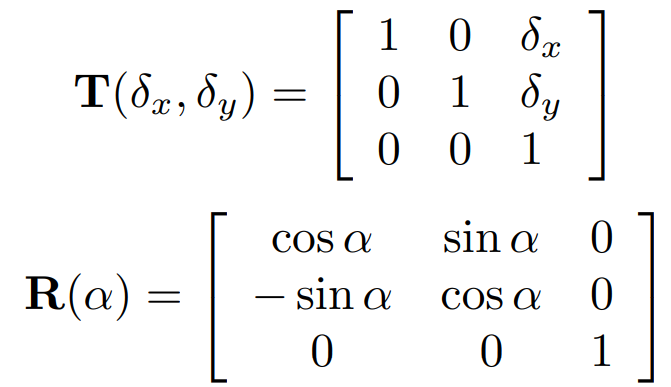
正负anchor的判断规则
由于RRPN中引入了角度标签,传统RPN的anchor正负的判断方法是不能应用到RRPN中的。RRPN的正anchor的判断规则满足下面两点(and关系):当anchor与Ground Truth的IoU大于0.7;当anchor与Ground Truth的夹角小于π/12。RRPN的负anchor的判断规则满足下述二者之一(or关系):与anchor的IoU小于0.3;与anchor的IoU大于0.7,但是夹角也大于π/12 。在训练时,只有判断为正anchor和负anchor的样本参与训练,其它不满足的样本并不会训练。
IoU计算方法
RRPN中IoU的计算和RPN思路相同,具体如图6所示,两个相交旋转矩形的交集可根据交点的个数分为三种情况,分别是4个,6个,8个交点:
 图6 IoU计算示例:(a)4个点,(b)6个点,(c)8个点(矩形的顶点为黑色,而交点为绿色)。考虑到(b),首先将交点I、J、L、K和内部顶点A、C加入P集,对P集进行排序,得到凸多边形AIJCKL,然后计算交点面积 Area(AIJCKL) = Area(∆AIJ)+Area(∆AJC)+ Area(∆ACK)+ Area(∆AKL)
图6 IoU计算示例:(a)4个点,(b)6个点,(c)8个点(矩形的顶点为黑色,而交点为绿色)。考虑到(b),首先将交点I、J、L、K和内部顶点A、C加入P集,对P集进行排序,得到凸多边形AIJCKL,然后计算交点面积 Area(AIJCKL) = Area(∆AIJ)+Area(∆AJC)+ Area(∆ACK)+ Area(∆AKL)
损失函数
RRPN的损失函数由分类任务和回归任务组成:
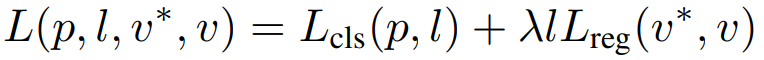
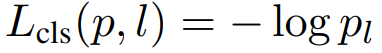
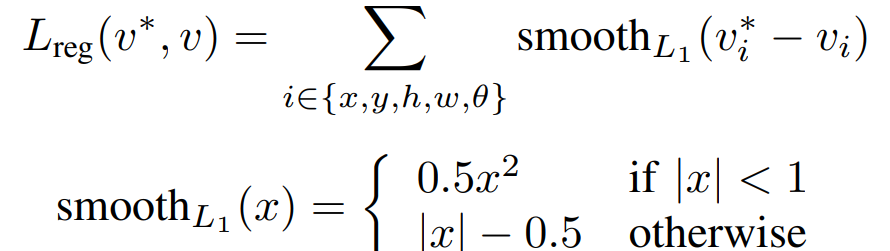
位置精校
传统的NMS只考虑IoU一个因素,而这点在RRPN中不再适用。Skew-NMS在NMS的基础上加入了IoU信息:保留IoU大于0.7的最大的候选框;如果所有的候选框均位于[0.3,0.7] 之间,则保留小于π/12 的最小候选框。
进一步的,引入RRoI Pooling用于RRPN中的旋转矩形的池化。首先需要设置超参数Hr 和Wr ,分别表示池化后得到的Feature Map的高和宽。然后将RRPN得到的候选区域等分成Hr×Wr 个小区域,每个子区域的大小是w/Wr × h/Hr ,这时每个区域仍然是带角度的。接着通过仿射变换将子区域转换成平行于坐标轴的矩形,最后通过Max Pooling得到长度固定的特征向量。RRoI Pooling伪代码如下,其中,第一层for循环是遍历候选区域的所有子区域,第5-7行通过仿射变换将子区域转换成标准矩形;第二个for循环用于取得每个子区域的最大值,第10-11行由于对标准矩形中元素的插值,使用了向下取整的方式。在RRoI Pooling之后,引入两个全连接层来判断待检测区域是前景区域还是背景区域。

| 项目 | SOTA!平台项目详情页 |
|---|---|
| RRPN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/rrpn |
本文从实例感知语义分割的角度介绍了一种新的面向多向场景文本检测的端到端框架。具体提出了融合文本分割网络( Fused Text Segmentation Networks ,FTSN),它在特征提取过程中结合了多级特征,因为与一般对象相比,文本实例可能依赖于更精细的特征表达。FTSN利用来自语义分割任务和基于区域建议的对象检测任务的优点,同时检测和分割文本实例。
FTSN具体框架如图7。FTSN是一个深度CNN模型,主要由三部分组成。通过resnet-101主干提取每个图像的特征表示,然后将多级特征图融合为FusedMapA,将其馈送到用于感兴趣的文本区域(ROI)生成的区域建议网络( region proposed network ,RPN)和用于稍后的FusedMapB,再进行 rois'PSROIPooling。最后,将rois发送到检测、分段和框回归分支,以输出像素级别的文本实例及其对应的边界框bounding 波。后处理部分包括NMS和最小四边形生成。
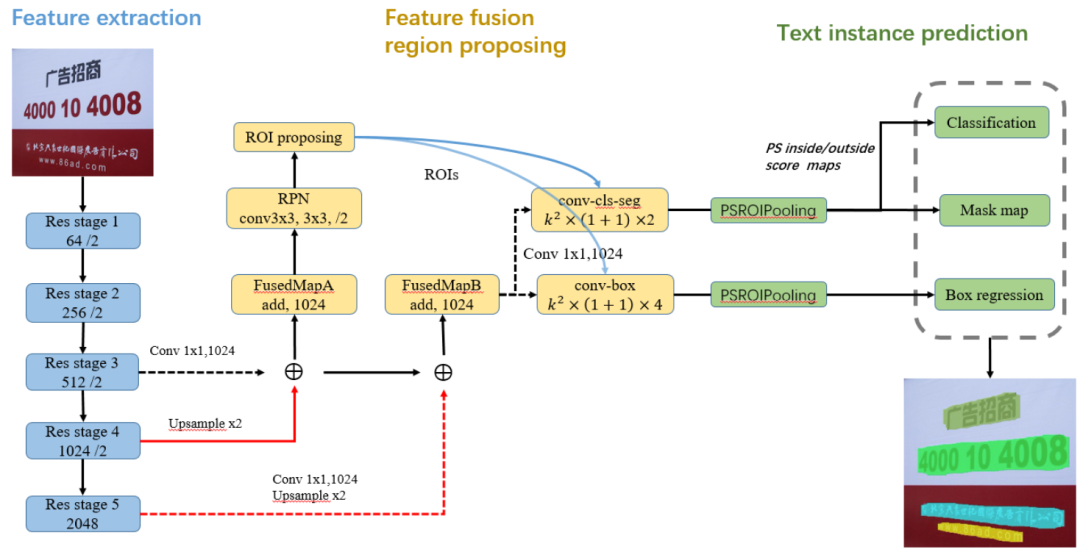 图7 所提出的框架由三部分组成:特征提取、特征融合以及区域建议和文本实例预测。虚线表示具有1x1核大小和1024个输出通道的卷积。红色的线是用于上采样操作,蓝色的线表示使用给定的ROI进行PSROIPooling的特征图
图7 所提出的框架由三部分组成:特征提取、特征融合以及区域建议和文本实例预测。虚线表示具有1x1核大小和1024个输出通道的卷积。红色的线是用于上采样操作,蓝色的线表示使用给定的ROI进行PSROIPooling的特征图
网络架构
卷积特征表示是以融合的方式设计的。文本实例不像一般的物体,如人和车,具有相对强的语义。相反,文本在类内的几何形状上往往有巨大的差异。因此,低层次的特征应该被考虑在内。resnet-101由五个阶段组成。在区域建模之前,第三阶段和第四阶段的上采样特征图通过元素相加形成FusedMapA,然后将第五阶段的上采样特征图与FusedMapA融合,形成FusedMapB。值得注意的是,在第五阶段不涉及下采样。相反,使用洞算法(Hole algorithm)来保持特征的跨度,并保持接受域。这样做的原因是,文本属性和分割任务都可能需要更精细的特征,涉及到最后的下采样可能会失去一些有用的信息。因为使用第三阶段的特征跨度可能会导致原始RPN中出现数百万个anchor,从而使模型训练变得困难,所以增加了一个3×3的跨度2卷积,以减少这种巨大的anchor数量。
之后,使用联合掩码预测和分类,在conv-cls-seg特征图上通过PSROIPooling生成的2×(1+1)内/外得分图上同时对文本实例进行分类和掩码,box regression分支利用PSROIPooling之后的convbox的4×(1+1)特征图("1+1 "表示一个类别为文本,另一个为背景)。
真实标签和损失函数
整个多任务损失L可以解释为:
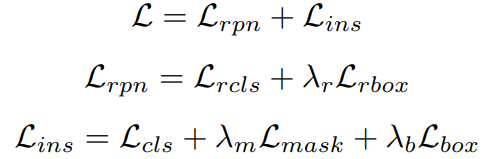
ℓ由两个子阶段损失组成:RPN损失 ℓ_rpn,其中,ℓ_rcls是用于区域建议分类,而 ℓ_rbox用于box regression;基于每个ROI的文本实例损失ℓ_ins,其中,ℓ_cls、ℓ_mask和ℓ_box分别代表实例分类、掩码和box regression任务的损失。
后处理
为了得到最终的检测结果,使用非最大抑制机制(NMS)来过滤重叠的文本实例,并保留那些具有最高分的文本。在NMS之后,为每个文本实例生成一个覆盖掩码的最小四边形,如图7所示。标准的NMS计算边界框之间的IoU,这对于字级和近水平的结果过滤来说可能是不错的。然而,当它们接近和严重倾斜时,它可能会过滤一些正确的线级检测结果。因此,作者提出了一个改良的NMS,称为Mask-NMS,以处理这种情况。Mask-NMS主要是将bounding box IoU的计算改为所谓的Mask maximum-intersection(MMI):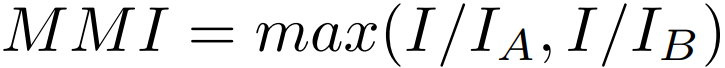
其中,IA、IB是两个要计算的文本实例的掩码区域,I是掩码之间的交集区域。使用掩码区的最大交集来替代原始的IoU,原因是检测可能很容易同时涉及同一行的行级和字级文本实例。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| FTSN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/ftsn |
由于多方位、透视变形以及文字大小、颜色和比例的变化,检测附带的场景文本是一项具有挑战性的任务。传统的研究只集中在使用矩形边界框或水平滑动窗口来定位文本,这可能会导致冗余的背景噪声、不必要的重叠甚至信息损失。为了解决这些问题,提出了一种新的基于卷积神经网络(CNNs)的方法,命名为深度匹配先验网络( Deep Matching Prior Network ,DMPNet),以检测具有更紧密四边形的文本。主要包括下述核心内容:1) 多边形滑窗(Quadrilateral sliding window),普通方法里的滑窗,一般来说都是矩形,多边形的滑窗可以更加契合场景中的不规则文字。2)序贯协议(Sequential protocol),在回归的时候能够准确有序的找到回归点的坐标。它可以唯一决定任意平面凸四边形的四个顶点的顺序。3) 共享的蒙特卡洛算法(Shared Monte-Carlo),在计算非极大值抑制的时候,可以快速准确地计算两个多边形的重叠面积。4) 光滑的ln损失(Smooth Ln loss)。相比l1损失或者l2损失,ln损失可以提高模型的鲁棒性和定位精度。
多边形滑窗
作者提出了倾斜四边形作为anchor box,如图8所示:在正方形窗口内增加两个45度的矩形窗;在长矩形窗内增加两个长平行四边形窗口;在高矩形窗内增加两个高平行四边形窗口。
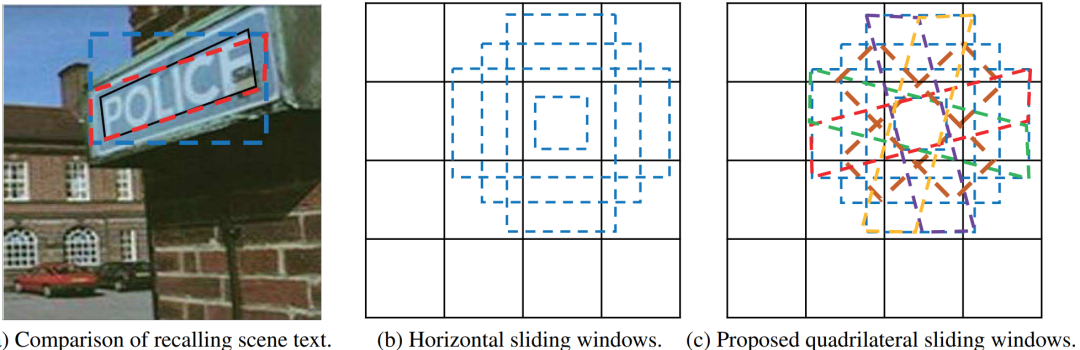 图8 水平滑动窗口和多边形滑动窗口的比较。(a): 黑色边框代表ground-truth;红色代表本文方法。蓝色代表水平滑动窗口。可以看出,四边形窗口比矩形窗口更容易回忆起文本,具有更高的交集比(IoU)。(b): 水平滑动窗口。(c): 多边形滑动窗口。不同的多边形滑动窗口可以用不同的颜色来区分
图8 水平滑动窗口和多边形滑动窗口的比较。(a): 黑色边框代表ground-truth;红色代表本文方法。蓝色代表水平滑动窗口。可以看出,四边形窗口比矩形窗口更容易回忆起文本,具有更高的交集比(IoU)。(b): 水平滑动窗口。(c): 多边形滑动窗口。不同的多边形滑动窗口可以用不同的颜色来区分
共享的蒙特卡洛算法
为了确定哪个Anchor box是Positive的,需要计算gt box和anchor box之间的IoU,作者指出原来的算法只能计算矩形之间的IoU,并且效率还不高。因此,他们提出了基于Monte-Carlo的方法来计算多边形的面积。1)对于GT( ground truth ),首先在它的外接矩形框里面均匀采样10000点,然后统计在GT多边形里面的点,得到GT的面积;2)如果Sliding window的外接矩形和GT的外界矩形不相交,那么GT和Sliding window的IoU就是0,否则根据1)的方法计算Sliding window的面积。然后统计GT里面的点在Sliding window里面的比例,求得交叉区域的面积,得到IoU。
序贯协议
对于水平的矩形框,只需要预测两个对角点的位置即可唯一确定该矩形,但对于任意的四边形,则需要同时预测四个角点的坐标。为了统一角点的顺序,论文提出了一种序贯协议。
预测给定多边形上四个点的最终顺序:首先在四个点里面选择 x 坐标最小的,如果有两个点的x一样,那么选择y最小的点作为第一个点;确定完点1之后,连接第一个点与其它三个点,找到中间那条,确定点3;然后画出对角线L13,假设中线 Lm:ax+by+c=0,并且我们定义一个待定点 P(xp,yp),找到在L(P)>0的P点为第二个点,否则为第4个点;最后连接点1、3和点2、4。比较对角线的斜率,以斜率较大、横坐标较小的点为新的第一个点,若斜率为正无穷,则以纵坐标较小的点为新的第一个点,然后重新确定其余三个点。
在回归四个角点的坐标时,论文是通过回归其到外接矩形中心点的相对位置完成的。从给定的坐标中,能计算出外接矩形的最小值X_min和最大值X_max,外接水平矩形的宽 W_chr=X_max-X_min,同样的,能得到高度H_chr。受Faster RCNN的启发,论文设定最终的回归目标为:
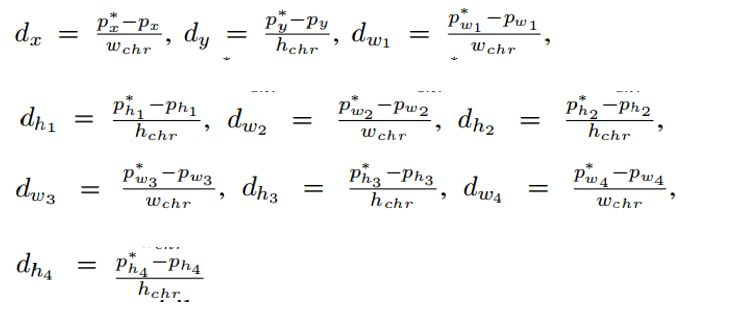
光滑的ln损失
一般回归的loss会用L2 loss或者smoothed L1 loss,其中smoothed L1 loss相比L2 loss,对于离群值的敏感度更小。但是从训练的角度来说,L2 loss能够加快收敛的速度。因为当预测值和真实值相差比较大的时候,L1 loss的梯度始终是1,但是L2 loss的梯度和误差是同一量级,这样可以加快收敛。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DMPNet | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dmpnet |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。