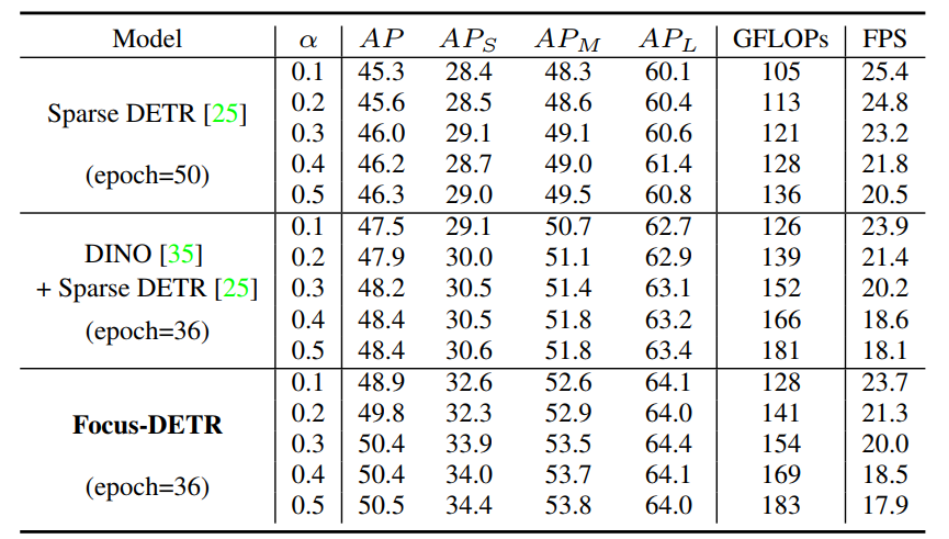
- 长臂猿-企业应用及系统软件平台
机器之心专栏

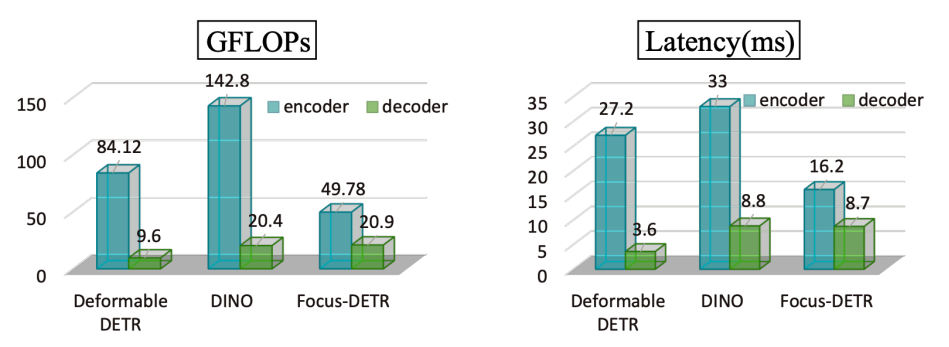
 的特征
的特征 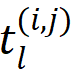 ,其中
,其中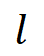 代表多尺度特征的层级序号,
代表多尺度特征的层级序号,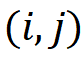 代表在二维特征图上的位置坐标,作者定义该特征在原图上的映射位置为
代表在二维特征图上的位置坐标,作者定义该特征在原图上的映射位置为 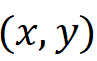 ,那么
,那么 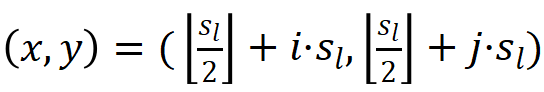 ,因此 特征所对应的标签应该为:
,因此 特征所对应的标签应该为: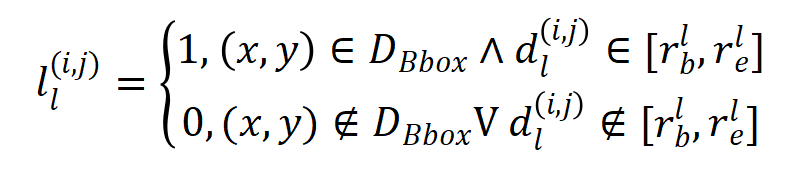
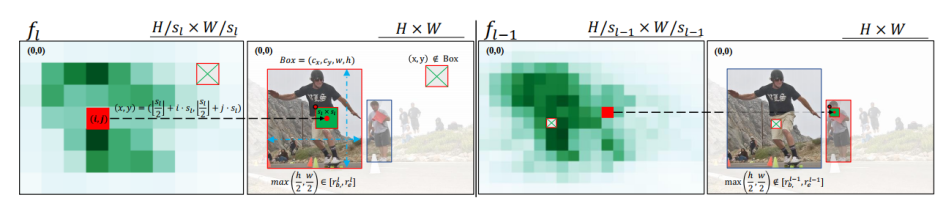
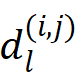 代表坐标和真值框中心之间的最大棋盘距离,
代表坐标和真值框中心之间的最大棋盘距离,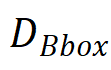 代表真值目标框,
代表真值目标框,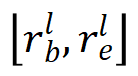 分别代表被第层特征图预测的目标的尺度的最大值和最小值,由于尺度重叠设置,
分别代表被第层特征图预测的目标的尺度的最大值和最小值,由于尺度重叠设置,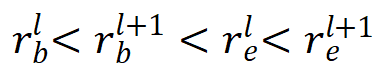 。
。
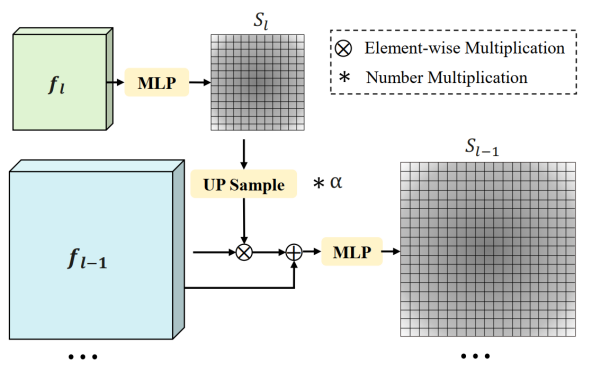
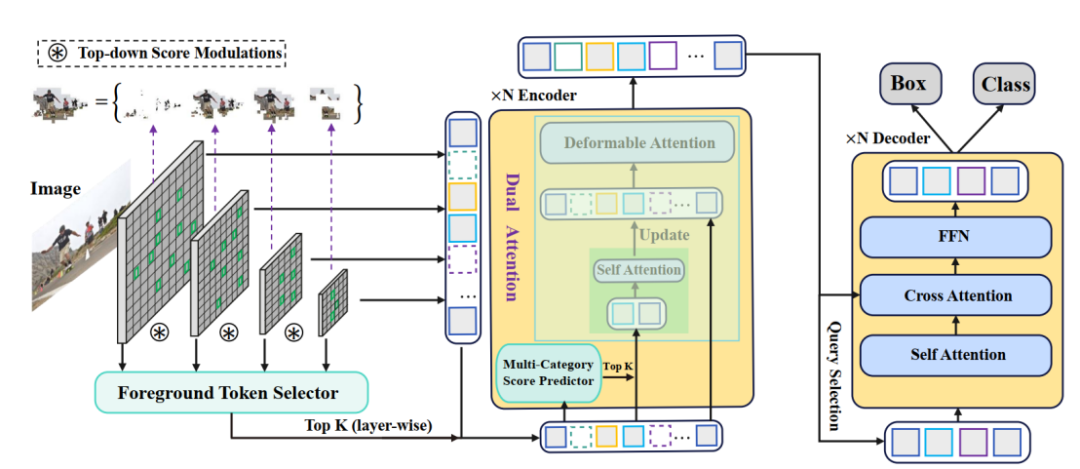
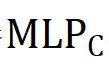 (・) 计算出的前景评分
(・) 计算出的前景评分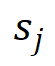 和类别评分
和类别评分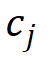 的乘积将作为作者最终的标准
的乘积将作为作者最终的标准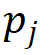 来确定注意力计算中涉及的细粒度特征,即:
来确定注意力计算中涉及的细粒度特征,即: 和分别代表前景得分和类别概率。
和分别代表前景得分和类别概率。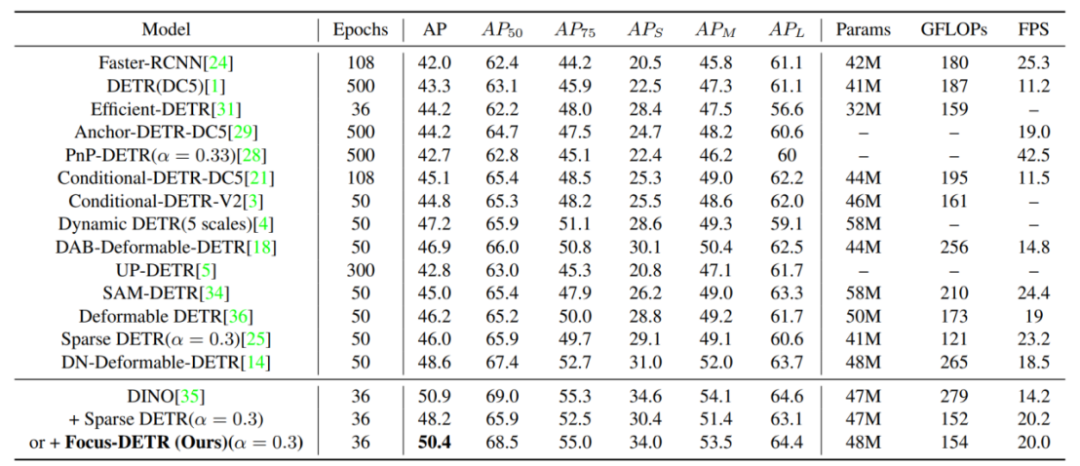
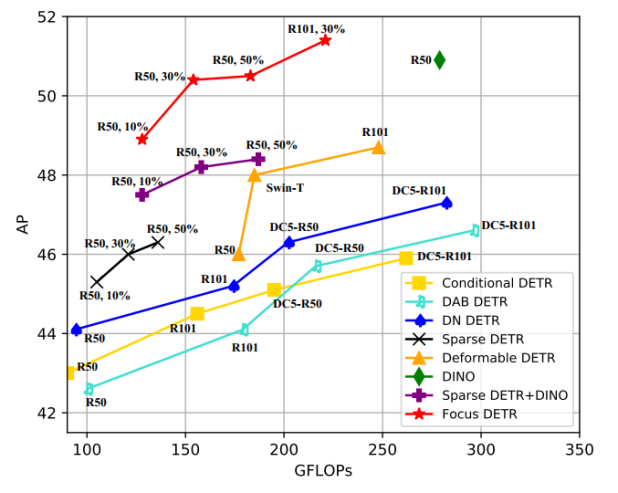

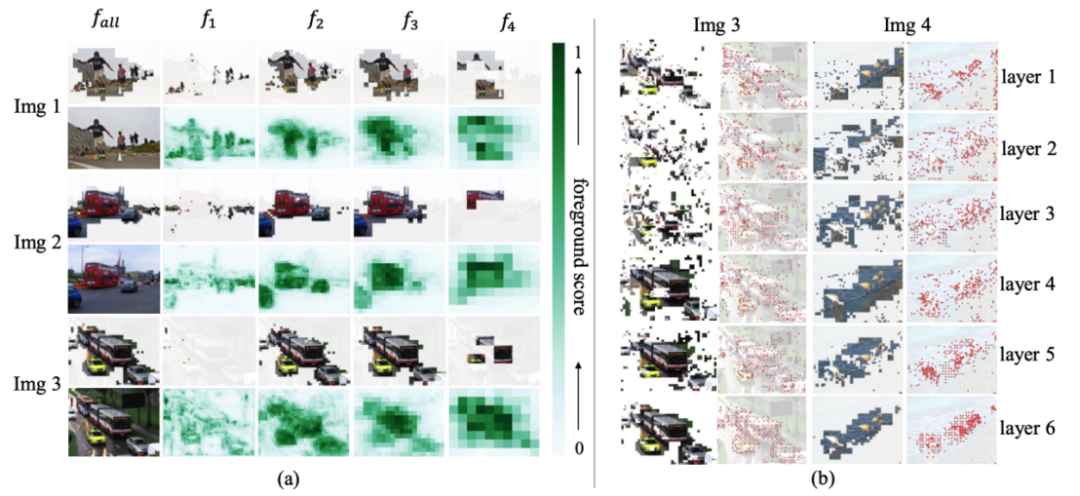
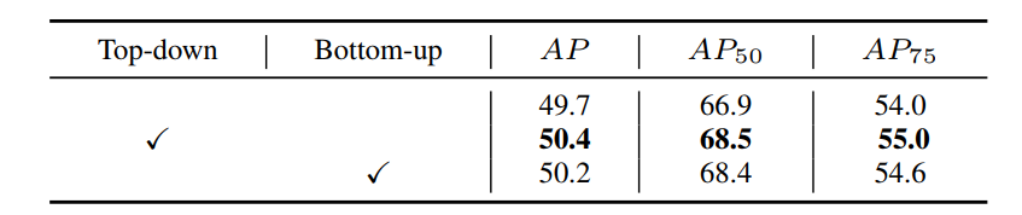
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com