- 长臂猿-企业应用及系统软件平台

作者 | Claude2-100k、袁滚滚
出品 | CSDN(ID:CSDNnews)
继今年 3 月的首届 NPCon 大会、8 月的新程序员大会(NPCon):AI 模型技术与应用峰会北京站之后,CSDN、《新程序员》与 LF AI&Data 、ZTE 中兴联合将 AICon&NPCon 带到深圳,围绕算力资源运维、模型训练部署、AI 能力构建等方面,为不同规模阶段的企业、团队、个人开发者,提供如何构建 AI 基础设施、实现工程落地,提供全链路的建议和方案。
CSDN 在关注 AI 技术突破的同时,更加关注 AI 工程实现方面的进展,希望帮助更多开发者,紧跟 AI 技术发展,快速成为「 AI-Native」 的开发者。

本次 AICon&NPCon 在模型与模型技术大发展的背景之下,邀请到了多位技术专家和明星开源项目,分享了最新的项目实践与思考。
同时在大会上,LF AI & Data Outreach chair 谭中意宣告 Generative AI Commons 成立,将持续在生成式 AI 、模型和模型技术为更多项目提供孵化与支持。
以下是本次活动演讲内容的重点回顾,完整回放请访问文末链接。
栾鹏:开源一站式机器学习平台
Cube-Studio
Cube-Studio 作为国内较早开源的云原生一站式机器学习/深度学习AI平台,项目负责人栾鹏,分享了 Cube-Studio 的平台功能和架构设计。

Cube-Studio 提供了丰富的AI相关功能,提供了包括数据管理、在线开发、模型训练、AutoML、模型推理、模型应用市场等服务。得到了大量开发者和企业的认可和采用,目前 Cube-Studio 在国内开源 MLOps 平台中居于前列,累计已经有上百家企业、团队对其进行了私有化部署。

Cube-Studio 下一步计划继续完善平台的各项功能,提供更好的产品体验,同时欢迎更多感兴趣的小伙伴加入社区使用、参与贡献。
RWKV:Transformer 时代的新型
大模型架构
RWKV Foundation 的侯皓文,全方位的介绍了RWKV的技术优势,相比于 Transformer 结构,RWKV 可以实现高效的模型训练和推理,适用于各类任务。

目前,在多个模型基准中取得不错成绩,也获得了全球范围内开发者和技术专家的认可。目前 RWKV 也已经加入 LF AI&Data 的孵化项目,成为 Generative AI Commons 第一个技术项目。
Dify.AI :LLMs App Stack 实践与前瞻
Dify.AI 联合创始人和产品 VP 延君晨,分享了 LLM 应用栈的实践,讨论了如何通过 Dify.AI 更好地将大语言模型应用于实际场景,也展示了 Dify.AI 各个模块的功能,如何帮助开发者快速构建应用。


开场致辞 & Linux 基金会 AI 发展纲要
LF AI & Data 董事会主席、中兴通讯股份有限公司开源战略总监孟伟在下午做了开场致辞,同时 Linux 基金会副总裁,LF AI & Data 执行总监 Ibrahim Haddad 通过视频,分享了下一步计划。
Generative AI Commons 圆桌论坛
LF AI & Data Outreach chair 谭中意在活动上宣告 Generative AI Commons 成立,将致力于通过透明的合作和可信的中立治理,来推动开源生成式人工智能技术的发展,包括大型语言模型(LLM)。谭中意在分享中介绍了 LF AI & Data 成立生成式 AI 委员会的初衷,组织架构、工作内容、进展和规划等等。
在随后的圆桌论坛中,Linux 基金会亚太区副总裁杨轩、LF AI & Data 董事会主席孟伟、LF AI & Data Outreach chair 谭中意、百度高级架构师 张军,以及 CSDN 人工智能技术主编袁滚滚,共同围绕 Generative AI Commons 未来的发展计划展开了讨论。

Generative AI Commons 将倡导开源和开放科学原则,促进合作开发,同时确保公平透明的管理。该倡议旨在创建一个中立、包容的社区,让各组织合作开发企业平台,填补生成式人工智能领域的关键空白。它拥有数千名成员,并与各行业部门开展合作,推动领先开源技术的发展。
未来 Generative AI Commons 将在可信的大型语言模型、人工智能生命周期工具、开放数据资源、开放性评估框架、合乎道德的人工智能治理和教育这些方面作为重点关注和发展的领域。
俊哲:浅谈开源大模型许可协议
中国信通院研究员俊哲介绍了大模型时代的开源许可协议情况,包括开源软件许可协议、开放数据许可协议和开放AI模型许可协议的区别。

在他的分享中,重点阐释了大模型时代开源许可协议许可内容的泛化问题,刨析开源软件、开放数据、开放人工智能许可协议的异同点,

他还介绍了信通院制定的面向 AI 模型的纸鸢开源许可协议,重点介绍了纸鸢的编制思路和重要定义。

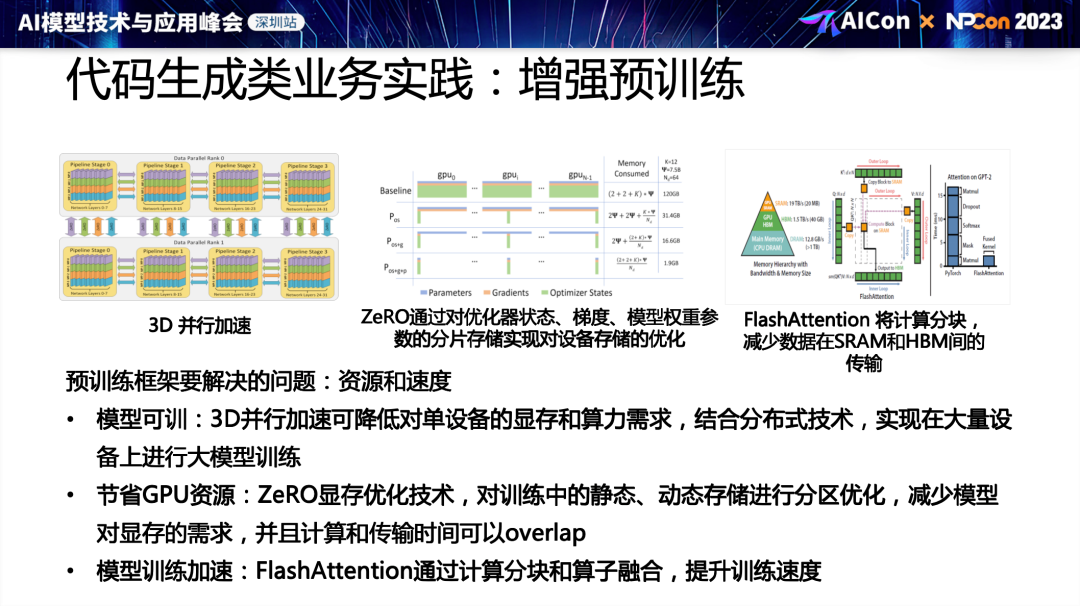
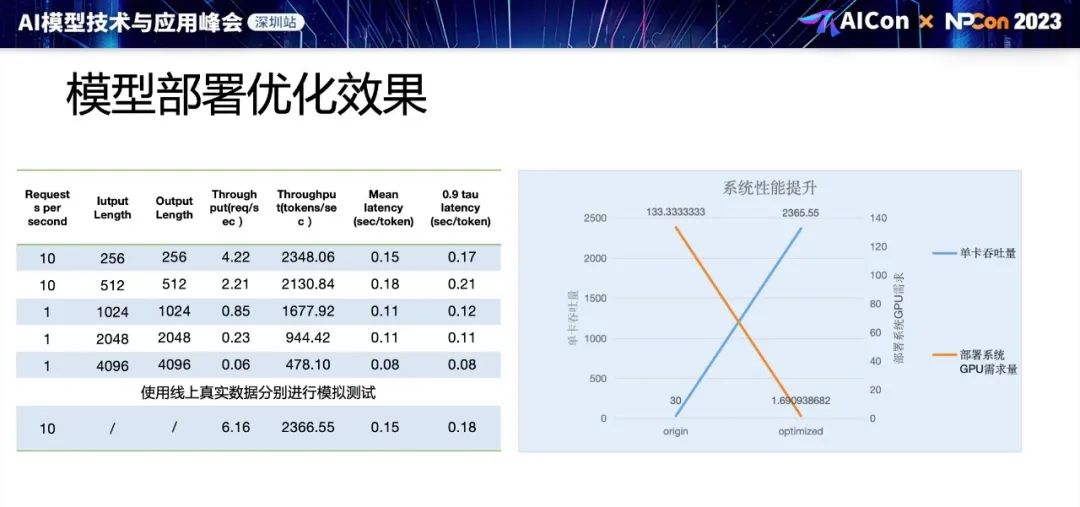
刘涛:LLM 模型部署优化工程实践
LLM 的模型部署需要海量的 GPU 资源,有效的推理优化才能降低部署成本,中兴通讯工程师刘涛分享了当下代码生成模型的业务时间和企业内部部署 LLM 模型的实践。

通过模型量化、3D并行、混合精度等方法,显著降低了模型部署的GPU需求,提高了推理吞吐量。
谭中意:ToB 大模型应用开发的 LLMOps 探讨
随着大语言模型的广泛应用,构建弹性可扩展且高可用的推理服务成为急迫需求。LF AI & Data Outreach chair 谭中意老师的分享,着眼模型云原生部署实践的环节。

谭中意老师介绍了针对推理服务的弹性、负载均衡、资源管理等方面采取的关键技术和优化手段,希望为 AI 实践者搭建高效稳定的 LLM 服务提供参考。

张军:飞桨开源大模型开发套件
百度架构师张军介绍了基于飞桨深度学习框架开发的大模型套件,旨在提供高性能、灵活易用的大模型全流程应用能力,在开发、训练、精调、压推、推理、部署六大环节提供端到端全流程优化。

其中的 PaddleNLP 和 PaddleMix 等项目,提供了大模型开发的全流程工具链和跨模态能力,降低了模型训练和部署的门槛。

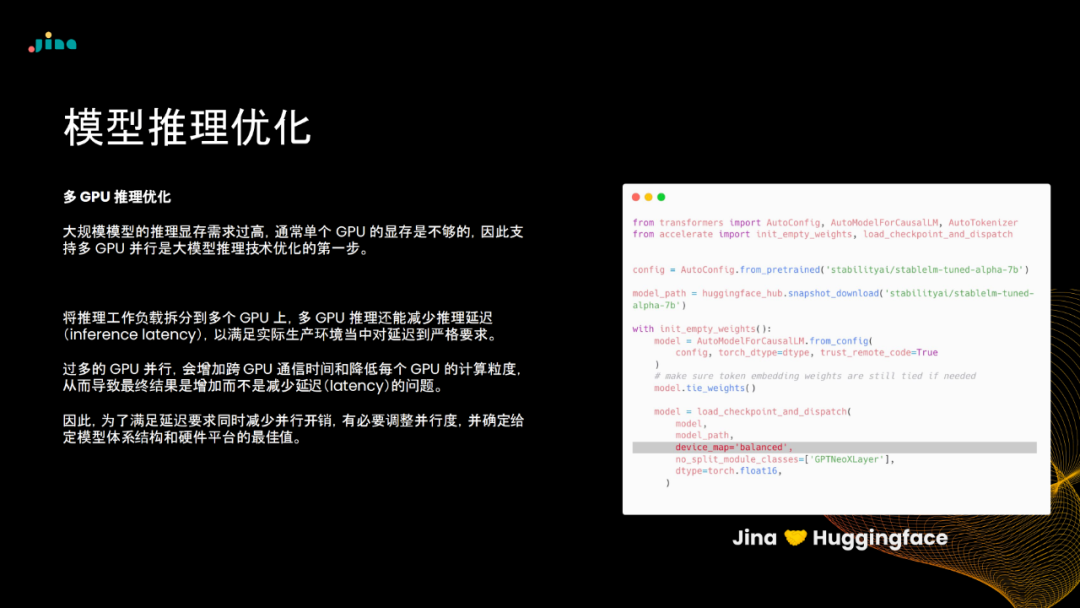
王峰:面向高弹性与高可用的 LLM
推理服务实践
随着大语言模型的广泛应用,构建弹性可扩展且高可用的推理服务成为急迫需求。Jina AI 研发总监王峰的分享着眼于模型云原生部署实践,介绍针对推理服务的弹性、负载均衡、资源管理等方面采取的关键技术和优化手段。

Jina AI 开源的 RunGPT 框架,通过微服务和云原生的基础架构设计,帮助开发者简化模型部署流程。