专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球社交、科技巨头Meta在官网开源了全新模型——Llama Guard。据悉,Llama Guard是一个基于Llama 2-7b的输入、输出保护模型,可对人机会话过程中的提问和回复进行分类,以判断其是否存在风险。可与Llama 2等模型一起使用,极大提升其安全性。Llama
Guard也是Meta推出的“Purple Llama”安全评估项目中,输入、输出保障环节的重要组成部分,这也是首个在输入输出防护中区分用户与AI风险的模型。Llama
Guard地址:https://huggingface.co/meta-llama/LlamaGuard-7bPurple
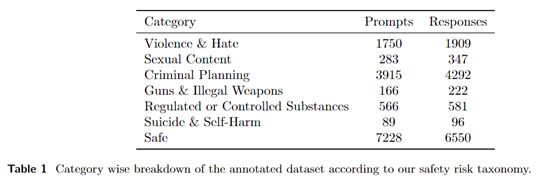
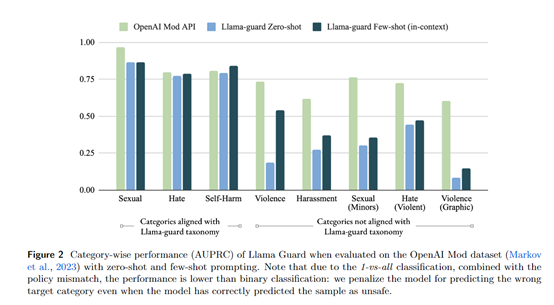
Llama地址:https://github.com/facebookresearch/PurpleLlama论文地址:https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/研究人员设计了一个包含法律和政策风险的安全风险分类体系。分类体系包含6大类可能的安全风险:暴力与仇恨、色情内容、非法武器、犯罪计划等。通过使用Anthropic提供的人机对话数据集,对数据进行标记。标记内容包括对话提问与回应中的风险类别及是否存在安全隐患。最终收集了近14000条标注好的对话样本。再以Llama 2-7b作为基础模型,采用指令式学习框架进行训练。此框架将分类任务表述为一个接一个的指令任务。使Llama Guard根据输入指令和数据学习进行多类分类。研究人员为用户提问和机器回复分别编写指令,实现对其语义结构的区分。还采取数据增强方法,强化模型只考虑给定输入中的分类信息。首先在内部测试集上进行验证,Llama Guard在整体和每个单独分类上的表现都超过了其他内容监管工具。然后,研究人员采用零样本和少量实例学习的方法,将Llama Guard迁移到其他公开测试集上进行验证。测试结果显示,在ToxicChat数据集上,Llama
Guar的平均准确率高于所有基线方法;在OpenAI评估数据集上,Llama Guard在零样本的情况下与OpenAI内容监管API表现相当。此外,Llama Guard使用了指令调优,可以适配不同的AI分类法或政策。用户可以通过零样本或小样本的方式便可实现指令迁移,以适配不同的应用场景需求。本文素材来源Llama Guard论文,如有侵权请联系删除
END