- 长臂猿-企业应用及系统软件平台
大模型让信息的高效获取成为可能,专业领域的知识问答是大模型最适合的应用。

来源 | 北京庖丁科技
大模型已经狂飙了半年。然而,对于新技术,商业世界最关注的问题永远是,能用来干什么,要怎么用,成本是多少?
作为一家技术和产品力过硬的 AI 公司,不少希望早日应用新技术的客户找到我们,询问大模型在具体业务中的落地应用。大家经常问到的问题包括:能否私有化部署?成本高吗?训练自己的大模型是否可行?利用内部数据进行 Fine-tune,效果理想吗?我们的观点是:大模型让信息的高效获取成为可能,专业领域的知识问答是大模型最适合的应用。
但回归到业务本身,无论是算法的可靠性,还是系统的性价比,直接训练和部署大模型都不是当下的最优解。检索增强的大模型 (Retrieval-Augmented LLM) 是最务实的解法。
以下是本文的核心观点:
- 大模型最适合的应用场景是知识问答。
大模型最擅长、最成熟的能力,是自然语言处理。因此,它最擅长的两个任务就是“写作生成”和“问答对话”。训练集中有哪些语言,它也就掌握了哪些语言。以 GPT 为例,它所掌握的语言不仅仅包括中文、英文等人类语言,还包括 python、golang、java 等机器语言。
在企业中,大模型的能力可以在知识问答、辅助编程等场景助力效率的提升。其中,最广泛的应用场景当属知识问答:每个行业、每个岗位的职场人,都需要参照规则或者查询信息才能辅助决策。但即便是表现优秀的顶尖大模型 GPT-3.5/4,目前也存在以下几个问题:
模型幻觉 (hallucination):大模型会记忆训练语料库中包含的事实和知识。但是它无法回忆出事实:它的生成逻辑是根据概率生成下一个单词,给出的是一个最优的词汇梯次聚类,因此有可能生成具有错误事实的表述。这就是模型的幻觉问题。我们不能将输出视为它思考过给出的“回答 (answer)”,而仅仅是一个“结果 (result) ”,需要进行鉴别。
知识截断 (knowledge cutoff):它不知道自己训练完成后发生的事情。即使我们不断更新训练数据集,不断进行训练,也只是将它的知识截止日期推后了,而无法做到实时更新。
缺乏用户定制化:用户需要是在某个实际场景中解决 95% 的问题,而不是在 100 个场景中解决了 70%-80% 的问题。
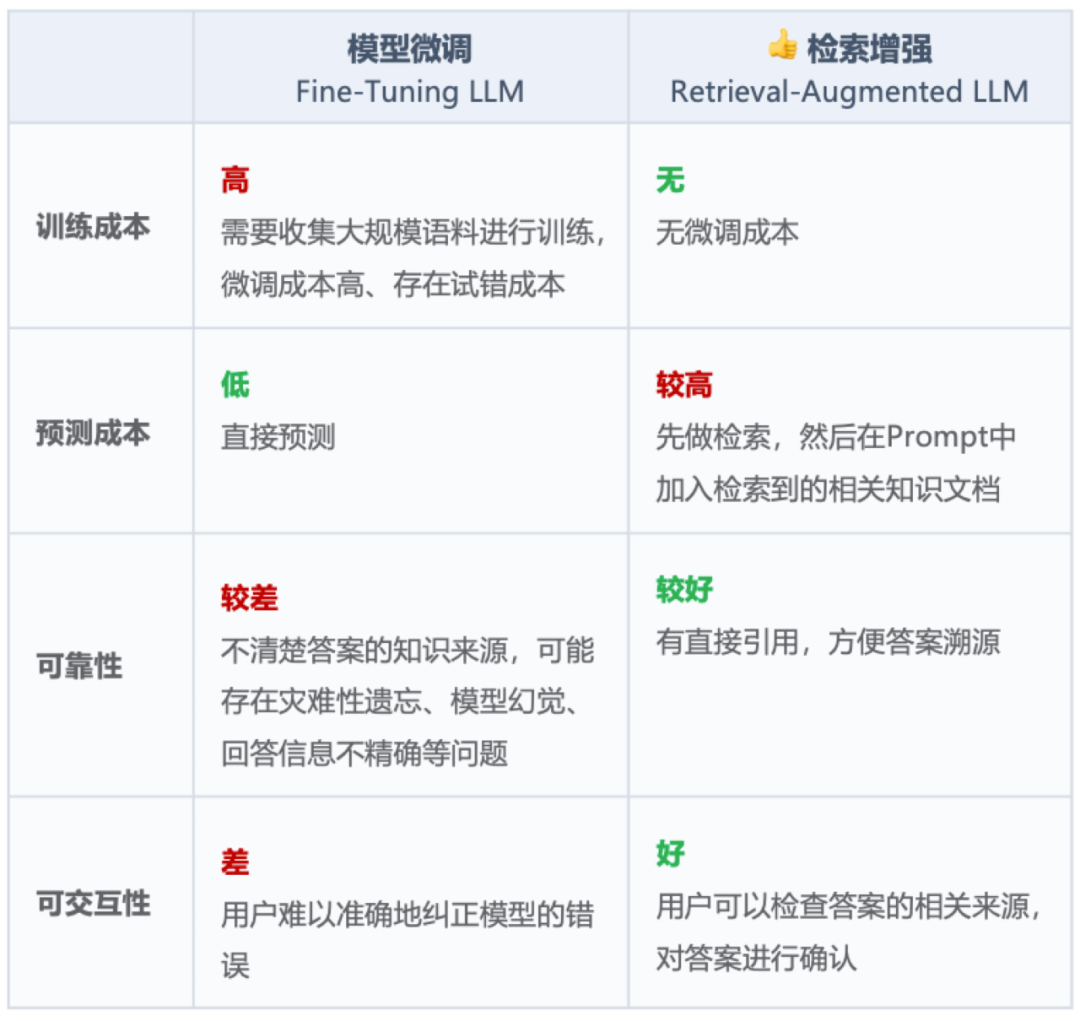
为了控制大模型的“幻觉”问题,保证在专业知识问答中的可用性,需要给大模型增加特定领域的知识储备。目前有两种证实有效的解决方案。一是考前封闭培训,再参加闭卷考试:基于行业数据的模型微调 (Fine-Tuning LLM),在训练数据集中加入专业知识。二是开卷考试,边查边答:结合向量数据库的检索增强 (Retrieval-Augmented LLM),在提示词 (Prompt) 中加入专业知识。
闭卷考试——模型微调 (Fine-Tuning LLM)
训练成本:高
预测成本:较低
可靠性:🌟
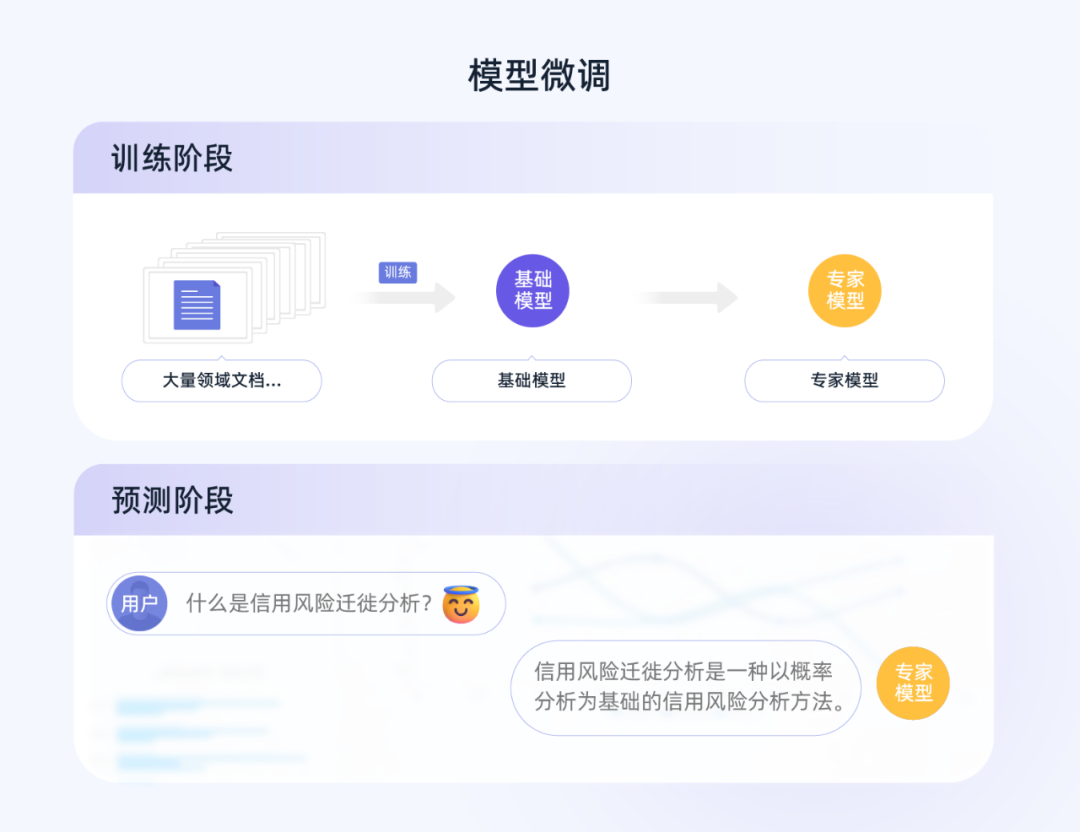
在通用语料库上训练的大模型,缺乏特定的领域知识,不能很好地泛化到特定的领域上。因此,在基础模型上用专业领域进行微调,理论上可以获得更为理想的效果。我们可以提前收集聚焦于垂直行业的领域文档、问答语料,对大模型进行继续训练,得到一个专家模型。
在这一步骤中,基础大模型本身的规模和高质量的大规模标注数据是关键。如果基础大模型本身的参数小,蕴含的基本概念和常识不足,微调带来的收益会非常有限。反过来,如果模型参数达到一定规模,训练的成本会很高,且存在一定的试错成本:这是一个探索性的学术实验,而不能保证 100% 的理想交付。
如果足够幸运,能够获得表现良好的专家模型,那么对于用户给出的问题,它就可以直接根据训练时存入的知识进行回答,无需依赖具体的文档。
开卷考试——检索增强 (Retrieval-Augmented LLM)
训练成本:无
预测成本:较高
可靠性:🌟🌟🌟
检索增强 (Retrieval-Augmented LLM),类似于让模型参加开卷考试。每一次作答前,模型都先从数据库里检索匹配相关内容,再根据此进行回答。这一方法将数据库和大模型的生成能力结合起来,类似于给大模型加了一个高性能外接硬盘。
由于不涉及到模型层面的训练和调整,这一方法对数据量的要求就小很多,只需收集面向具体问题的文档即可。技术人员需要做的,是不断优化检索召回的精度。
首先将企业内部各类知识 (包括.doc, .pdf, Markdown, 扫描件等等) 进行预处理,以机器可读、可检索的格式,存储到数据库中。然后在每次提问时,模型就可以“边搜边答”了:根据用户的提问,先在数据库中匹配检索相似度最高的文本块,将这些文档片段作为提示语,结合提问一起给到大模型,从而生成答案。

提示语 (Prompt) 是帮助人与大模型沟通的通道。如果随意提问,那么大模型给出的答案随机性很大、信息质量也比较低。检索增强的模式,帮助模型筛选出高度相关的信息块,并将上下文 (Context)、问题 (Query),一起打包成提示语 (Prompt) 发送给大模型,从而得到更高质量的回答。

我们认为,对于企业来说,比起训练自己的大模型,更务实的解决方案是调用更成熟的大模型,结合检索增强等其他技术手段,来满足实际使用的需求。
1. 专家模型,难以“小而美”
闭卷考试的方法对模型是个很大的考验。根据现有研究,大模型与小模型的能力存在较大的差异。大模型的能力存在“涌现性”,即在模型参数达到一定数量后出现性能的跳跃性增长[1],这说明较小的模型,即使经过微调也难以在专业领域获得良好的表现。
目前,业内的一个共识是,50B-60B 参数是模型智力涌现的门槛。对于其能力差别的原因,有研究发现,大模型由于有更多的参数量,可以对语义进行更细粒度的区分。例如对于一个代码的关键字 return,参数量大的模型可以精细地区分不同编程语言的 return 并激活不同的神经元[2]。这种能力对于多义词以及精细的内容理解是至关重要的。
尽管学界都在研究如何通过更小的模型实现更好的效果,从而节省成本,但现阶段还是一个技术卡点,突破需要时间。OpenAI 的研究表明,模型性能的规模定律仍然适用,增加模型的大小将继续提高性能。换言之,基于较大规模的模型参数,在大数据量上的预训练 (Pretraining) 仍然是提高模型智能水平的关键。
模型的训练也不存在“投机取巧”的捷径。通过采集 ChatGPT 的问答对,对较弱 (较小) 开源模型进行微调的方法,无法提高模型的实际能力。伯克利学者的研究结果表明,这些模仿模型表面上看输出质量不错,学习了 ChatGPT 的回答风格,但其真实能力经不住考验——更针对性的评估揭示,这些模型在具体的评测任务上与大模型之间的差距并没有缩小[3]。
专家模型如果想要“靠谱”,有两个关键点:一是要在足够好的基础模型上进行微调,二是获取到大量的高质量行业数据。同时,专家模型也依然是根据概率生成下一个单词,它的幻觉问题会有所减轻,但绝不可能避免。
此外,由于知识是以模型参数的方式存储的,它不清楚答案的知识来源于其训练阶段的什么具体文档;因此大模型本身无法提供“结果溯源”的功能,用户难以对结果进行校验。
2. 检索增强,给模型加上海马体
检索增强 (Retrieval-Augmented LLM) 的好处在于:
经济性:检索增强没有训练模型的成本,能够通过加入不同领域的知识来源快速进行领域的适配,更加经济。
可靠性高:通过检索,将相关度高的内容块加入 Prompt,这样大模型可以知道作答的知识从何而来,方便进行知识溯源,也支持人类用户对答案进行二次验证,准确性更有保障。
时效性强:检索增强的方法不在大语言模型层进行改动,只是将新近资料预处理后加入文档库,更新频率更高。机器可检索的文档库,如同一块外接的知识硬盘,起到了海马体一样的作用。在人脑中,海马体与记忆的编码、存储和检索密切相关,将大脑不同区域的信息整合起来。
大模型拥有短期记忆,它与我们的交互就像是一次次不断重来的闭卷考试,而检索增强将这一过程变成开卷考,从而增强了大模型的记忆,帮助其克服“幻觉”。一方面,大模型在生成答案前可以实时查询专门的数据和知识,让回答更精准;另一方面,我们也可以将历史的问答对、用户的反馈存入数据库,让大模型学习这些历史使用数据,从而更好地理解用户的需求。
3. 两种方法的对比
我们来总结下检索增强和模型微调两种方法各自的优劣:
检索增强的好处在于,没有高成本的训练、可以加入直接引用的产品设计、支持用户对 AI 生成答案的检查,但单次预测成本较高,因为需要在提示语中加入相关知识片段,需要消耗的 token 更多。模型微调虽然单次预测成本较低,但与高昂的训练成本比起来显得微不足道。
当然,将检索增强和模型微调两种方式结合是更好的方案,能够补充模型的领域常识,有“钞能力”的企业可以两套方案同时进行。同时,在此基础上进行提示词优化,例如将特定任务拆解为几个步骤,进行多轮提示,也可以更好地引导大模型输出更为理想的结果。
庖丁科技一直跟进大模型的技术进展,并探索可行的产品化方案。无论技术如何更迭,用户最关注的永远是稳定性、可用性、易用性。庖丁科技基于多年沉淀的基座能力,采用自研的富格式文档解析、Embedding 技术,结合不同的大语言模型,打造了 AI 专业知识问答助手 (海外版: ChatDOC;国内版: 庖丁解文)。
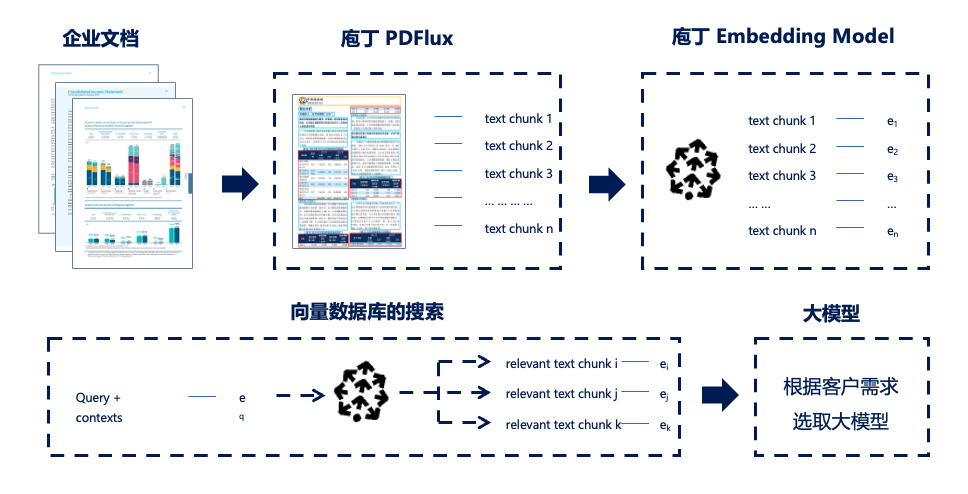
我们所采用的就是检索增强的解决方案,既能充分发挥大模型的能力,也较好地通过技术组合和产品设计,提高 AI 回答的可靠性。我们的技术优势在于:
1. 文档信息抽取的基础设施,准确提取数据
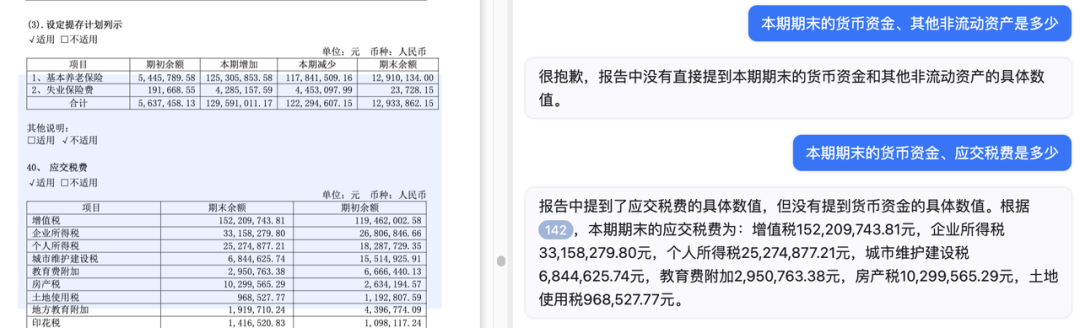
基于深度学习和计算机视觉技术,庖丁科技多年以来沉淀了的世界领先富格式文档解析技术,尤其是表格识别技术,我们能将信息损耗降至最低。例如,我们对同一份年报,提出一个相同的问题:本期期末的货币资金、应交税费是多少?
庖丁科技的 ChatDOC 可以从表格中提取出正确的数字,并溯源到底稿;
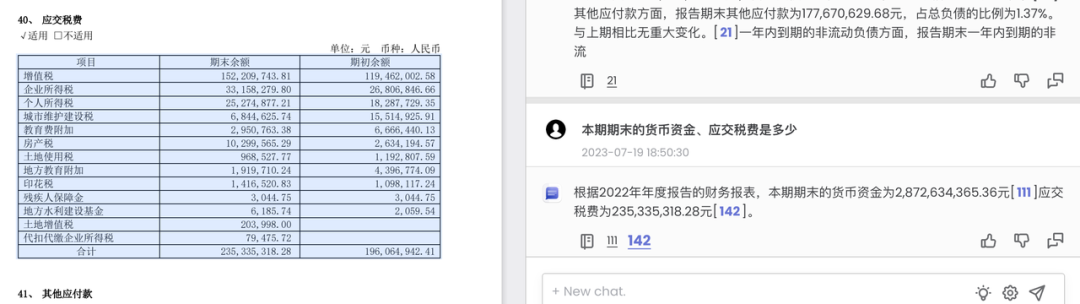
而类似的产品则无法给出正确的答案,很有可能是它并不能对应出表格的行列关系。
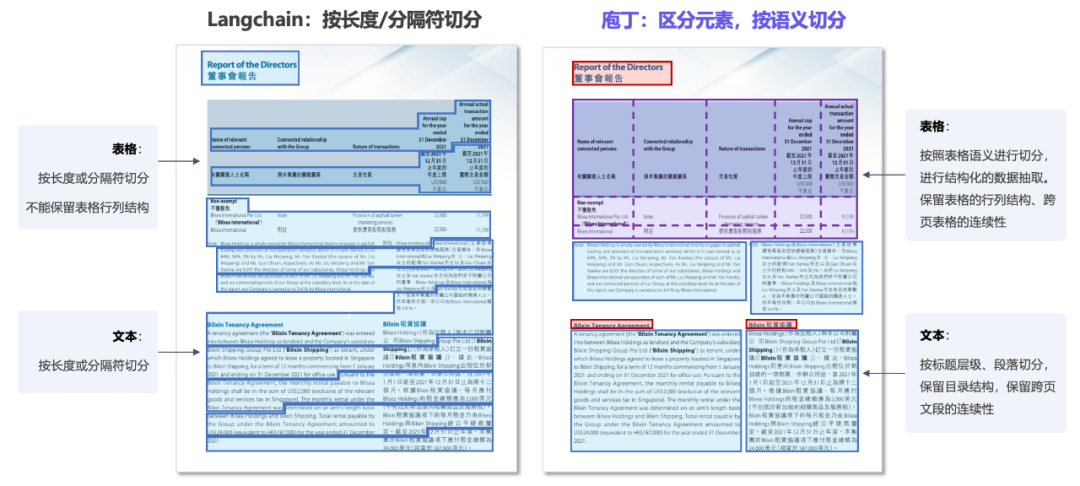
2. 将信息按照完整的知识单元存储,可用性高
为了便于大模型检索,我们需要将长文档切分为一个个小的知识块存储起来。
市面上开源的模型大部分是根据固定长度,或者换行符、分隔符进行切分,会将一个完整的知识模块拆分到不同文本块 (text chunk) 里。尤其是对于表格来说,只是将文字提取出来,而丢失了原来的结构和含义。而庖丁是按照语义进行段落切分、结构化抽取了表格数据,跨页、跨行均不影响知识的连续性。
3. 自研 Embedding 算法,检索匹配更相关
我们采用了自研的 Embedding 计算方法,自然语言检索的相关度更高。我们采用了更高维度的 Embedding 向量来编码更复杂、细粒度的语义。我们内部的评测表明,与 OpenAI 的 text-embedding-ada-002 相比,我们的 Embedding 方法召回率有较大幅度的提高。这使得大语言模型可以更准确地在资料中查找到“相关考点”,并完成开卷考试。
面向海外个人用户,我们推出了“ChatDOC 文档阅读助手”。用户可以与文档直接对话,在一问一答间直达知识,并获得详细的引用来源,减轻大模型的幻觉问题。目前,ChatDOC 已帮助数 20 余万用户更好地学习、阅读、获取知识。

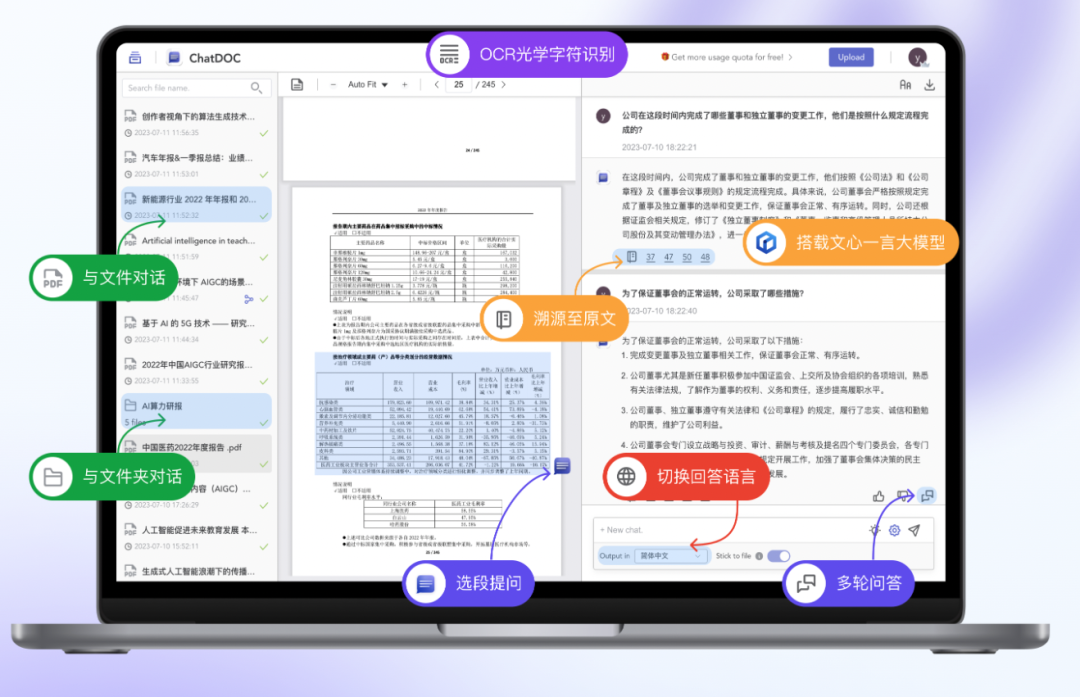
面向国内企业用户,我们推出了“庖丁解文专业知识问答助手”,能够帮企业解决以下问题:
非结构化数据的预处理:将文档、PDF、扫描件转化为结构化数据。许多高价值信息都被锁在文档和扫描件中,机器可读性、可搜索性都很差。通过让大模型能够从更长尾的多模态数据中读取信息,生成相应的知识回答,以技术实现效率的提升。
专业领域知识问答:“庖丁解文”可以基于企业级内部知识、行业公开资料,让大模型在金融、法律、审计等严肃领域,或者合同管理、简历管理、专利信息服务等严肃场景进行专业知识问答,从而帮助企业用户更快捷地获取知识。辅助决策的同时,也能减少信息流通的摩擦。
AI 回答可溯源:相关的知识片段作为 Prompt 给到大模型,不仅保证了 AI 回答的稳定性,还能让我们在产品设计上增加溯源功能,每一句话都给到原文档的出处,方便进行二次核实,保证可靠、可用。
多模态数据解析、向量计算的部分,我们可以根据客户的预算情况,提供云服务,或者私有化部署。
大模型服务的部分,客户可以选取自己需要的大模型,采用通过 API 调用的模式,按量收费;或者由客户直接采购,交由我们来完成系统的集成和对接。
参考文献:
[1] Emergent Abilities of Large Language Models
[2] Finding Neurons in a Haystack: Case Studies with Sparse Probing
[3]The False Promise of Imitating Proprietary LLMs


 星标 牛透社 ,SaaS 洞察不错过~
星标 牛透社 ,SaaS 洞察不错过~