- 长臂猿-企业应用及系统软件平台
微软亚洲研究团队推出了 Visual ChatGPT,它解决了 ChatGPT 在处理视觉信息方面的限制。这是继一系列关于大型语言模型(LLMs)的新闻之后推出的。此前,ChatGPT 只受过单一语言形式的训练。 微软亚洲研究院团队开发了 Visual ChatGPT,以克服 ChatGPT 中处理视觉信息的限制。这一进展是在大型语言模型(LLMs)方面的一系列新闻之后出现的,在此之前,ChatGPT 仅针对一种语言形式进行训练。 ChatGPT 在过去几周和几个月中已经成为大多数人谈论的话题。然而,由于其语言训练能力,它不允许处理和生成图像。 相比之下,如果有视觉基础模型,如 Visual Transformers 和 Steady Diffusion,则具有惊人的视觉能力。这就是通过将语言和图像模型结合。而创造出 Visual ChatGPT。 视觉基础模型用于分组计算机视觉中使用的基本算法。它们将标准计算机视觉技能转移到人工智能应用程序上,以处理更复杂的任务。 Visual ChatGPT 中的提示管理器包括 22 个 VFMs,其中包括文本到图像、控制网络、边缘到图像等。这有助于 ChatGPT 将图像的所有视觉信号转换为语言,以便 ChatGPT 更好地理解。那么 Visual ChatGPT 是如何工作的呢? Visual ChatGPT 由不同的组件组成,以帮助大型语言模型 ChatGPT 理解视觉信息。 用户查询:这是用户提交其查询的位置 提示管理器:将用户的视觉查询转换为语言格式,以便 ChatGPT 模型能够理解。 视觉基础模型:这结合了各种 VFMs,例如 BLIP(引导式语言 - 图像预训练)、稳定扩散、ControlNet、Pix2Pix 等。 系统原则:为 Visual ChatGPT 提供基本规则和要求。 对话历史记录:这是系统与用户进行交互和对话的第一个点。 推理历史记录:使用不同 VFMs 过去的推理来解决复杂问题。 中间答案:通过使用 VFMs,该模型将尝试输出几个具有逻辑理解力的中间答案。 这是 ChatGPT 处理视觉信息的强制性解决方案,因为它仍将图像的所有视觉信号转换成语言。在上传图像时,提示管理器会合成一个包括文件名等信息的内部聊天记录,生成 ChatGPT 更好地理解查询所指的内容。 例如,用户输入的图像名称将作为操作历史记录,并且提示管理器将协助模型通过 “推理格式” 来确定需要对该图像执行哪些操作。你可以把这看作是模型在选择正确 VFM 操作之前进行内部思考。 在下面的图片中,你可以看到 Prompt Manager 如何启动 Visual 规则。 Image by Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models 您还可以在微软的Visual ChatGPT GitHub上了解更多信息。请确保查看每个视觉基础模型的 GPU 内存使用情况。 Visual ChatGPT 能做什么? 您可以要求 Visual ChatGPT 根据描述从零开始创建一张图片。您的图片将在几秒钟内生成,具体时间取决于可用的计算能力。它使用文本数据进行合成图像生成,基于稳定扩散技术。 再次使用稳定扩散,Visual ChatGPT 可以更改输入图像的背景。用户可以向助手提供任何关于他们想要更改背景的描述,稳定扩散模型将修复图像的背景。 你还可以根据提供应用程序描述来更改图像颜色并应用效果。Visual ChatGPT 将使用各种预训练模型和 OpenCV 来更改图像颜色、突出显示图像边缘等。 Visual ChatGPT 允许末通过编辑和修改带有指向性文本描述的图片中的对象来删除或替换图片。但是此功能需要更多计算能力。 Visual ChatGPT 在很大程度上依赖于 ChatGPT 和 VFMs,因此这些单独方面的准确性和可靠性影响了 Visual ChatGPT 的表现。使用大型语言模型和计算机视觉的组合需要高度及时的工程处理,并且可能难以实现熟练的表现。 Visual ChatGPT 具有轻松插拔 VFMs 的能力,这可能会引起一些用户对安全和隐私问题的关注。微软将需要更深入地研究如何保护敏感数据不被泄露。 Visual ChatGPT 研究人员遇到的限制之一是由于 VFMs 失败和提示多样性导致生成结果不一致。因此,他们得出结论:他们需要开发一个自我纠正模块,以确保生成输出符合用户要求,并能进行必要修正。 为了从 Visual ChatGPT 中受益并利用 22 个 VFMs,请确保您具有足够高数量级(例如 A100)GPU RAM。根据手头任务确定所需 GPU 数量以有效完成任务。 Visual ChatGPT 仍然有其局限性,但这是同时使用大型语言模型和计算机视觉的重大突破。 Visual ChatGPT 是否类似于 ChatGPT4?如果您尝试过这两个模型,您有何看法?请在下面留言!什么是 Visual ChatGPT?
ChatGPT 的限制
什么是视觉基础模型?
Visual ChatGPT 如何工作?
Visual ChatGPT 的基础组件
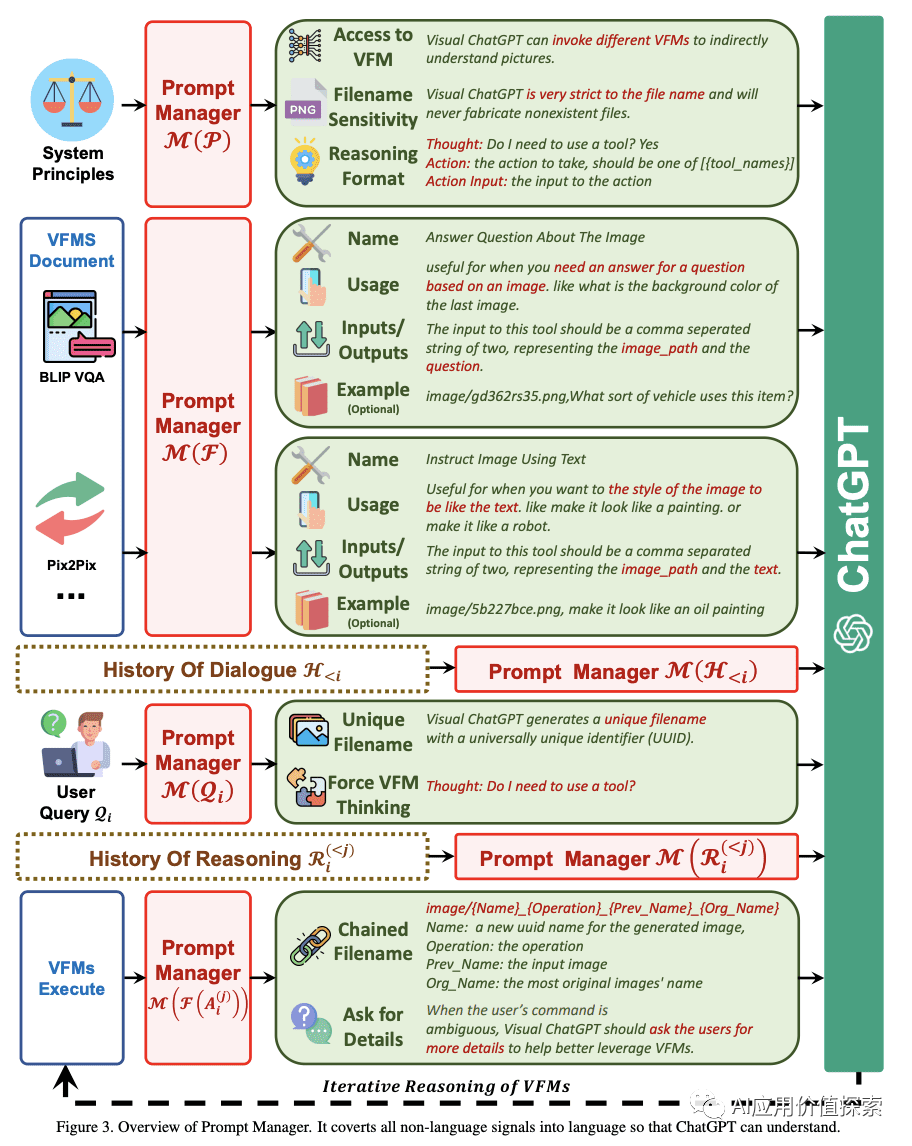
更多关于提示管理器
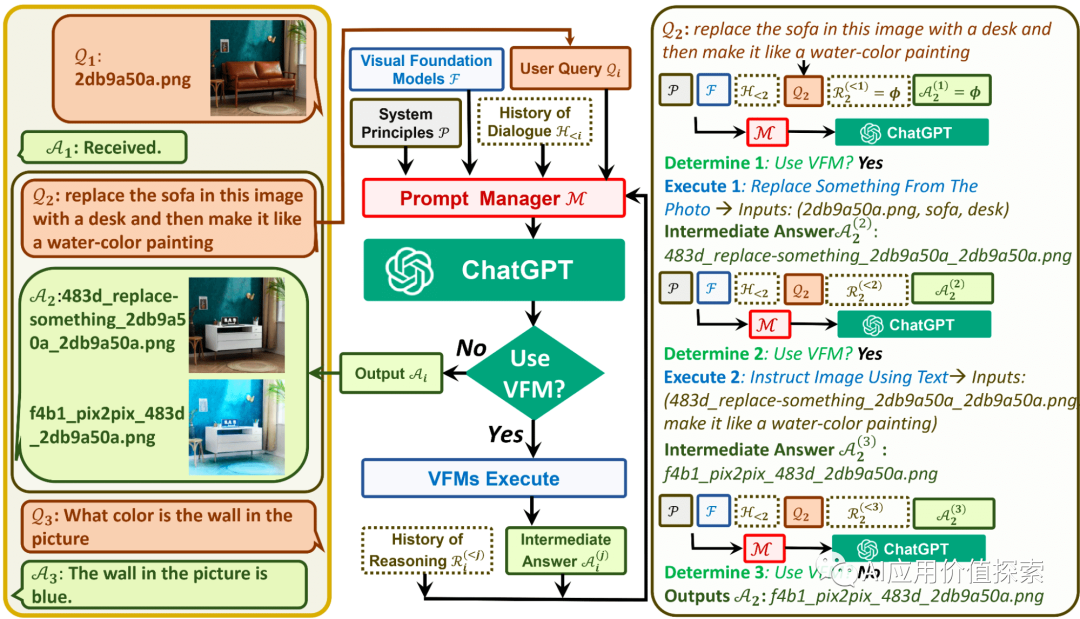
如何使用 Visual ChatGPT
# create a new environmentconda create -n visgpt python=3.8# activate the new environmentconda activate visgpt# prepare the basic environmentspip install -r requirement.txt# download the visual foundation modelsbash download.sh# prepare your private openAI private keyexport OPENAI_API_KEY={Your_Private_Openai_Key}# create a folder to save imagesmkdir ./image# Start Visual ChatGPT !python visual_chatgpt.pyVisual ChatGPT 的使用案例
图像生成
更改图像背景
更改彩色图像和其他效果
对图片进行修改
计算机视觉和大型语言模型的结合
隐私与安全
自我纠正模块
高量 GPU 要求
总结
Visual ChatGPT 的限制
本文来自AI应用价值探索