- 长臂猿-企业应用及系统软件平台
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
4月17日,RedPajama宣布开源1.2万亿token数据集,帮助开发者训练类ChatGPT大语言模型。这也是目前类ChatGPT领域,全球最大的开源训练数据集。(地址:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T)
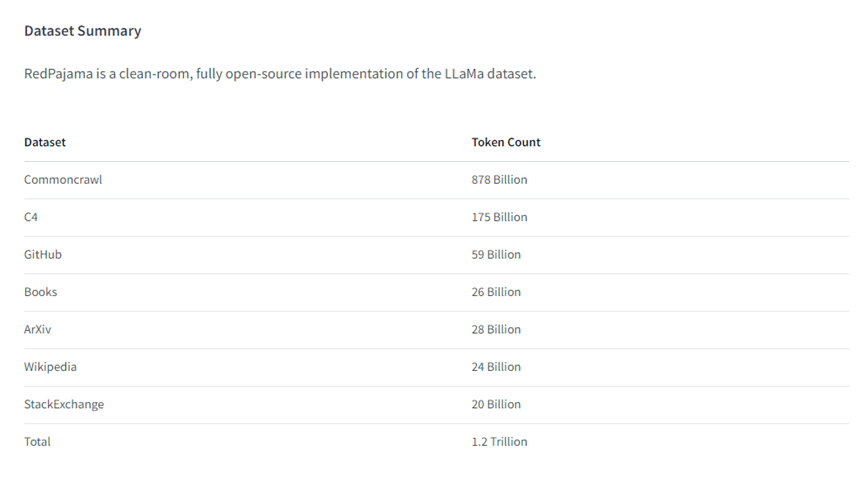
据悉,RedPajama完美复制了LLaMA模型上的1.2万亿训练数据集,由维基百科、GitHub、普通抓取、C4、图书、ArXiv(知名论文网站)、Stack Exchange七部分组成。完整数据集容量约5T,根据数据使用条例已经允许商业化。
最近的类ChatGPT开源项目实在是太卷了,不仅开源了基础模型,就连核心训练数据集也陆续开源,生怕开发者缺衣少粮服务真是周到位啊。但一次性开源如此庞大的数据集还真是少见。

ChatGPT的出现加快了生成式AI的商业化落地,并引领了全球新一轮AI技术变革。由于Open AI没有开源ChatGPT,LLaMA、Alpaca、Guanaco、LuoTuo、Vicuna、Koala等一大批优秀的开源项目如雨后春笋般快速增长。
其中,由Meta AI发布的LLaMA是公认最佳的ChatGPT平替产品,其中,70亿参数模型经过1.2万亿数据训练单个CPU就能跑,比较适合中小型企业和普通开发者。但LLaMA只能用于学术研究不允许商业化。所以,RedPajama复制了LLaMA1.2万亿训练数据,帮助开发者加速大语言模型训练进程。
其实RedPajama本身就是一个类ChatGPT大语言模型由Together、 Ontocord.ai、ETH DS3Lab、Stanford CRFM和Hazy Research一起合作开发。预计5月份,RedPajama会将大语言模型进行开源。

本次开源的数据集,RedPajama受LLaMA 70亿参数模型启发,按照其论文的数据模式从维基百科、GitHub、普通抓取、C4、图书、ArXiv、Stack Exchange抓取了1.2万亿训练数据,并进行了数据优化、过滤。
其中,普通抓取渠道获取了8780亿数据,并通过多个质量过滤器进行过滤,包括选择类似维基百科页面的线性分类器。C4获取1750亿,基于标准 C4 数据集。GitHub获取590亿,按许可证和质量过滤;图书获取260亿,包括开放书籍的语料库,并根据内容相似性进行去重。
ArXiv获取280亿,去除了样板文件的科学文章。维基百科获取240亿,基于子集数据删除了样板内容。StackExchange获取200亿,基于子集数据删除了样板内容。总体来说,RedPajama完美复制了LLaMA的训练数据集。
RedPajama还开源了所有数据预处理和质量过滤器,使得任何人都可以按照数据准备方法复制 RedPajama-Data-1T。(地址:https://github.com/togethercomputer/RedPajama-Data)
RedPajama表示,正在积极训练类ChatGPT大语言模型,并进行深度优化。根据Alpaca模型的展示,仅需5万条高质量、多样化的指令,就能显着改善对话功能。
目前,RedPajama已经收集了10万条高质量指令,将用于发布RedPyjama模型的指令优化版本。
本文素材来源RedPajama,如有侵权请联系删除
END

加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”
管理员审核后加入讨论群
本文来自AIGC开放社区