- 长臂猿-企业应用及系统软件平台
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
4月17日,Meta发布了最新开源视觉模型DINOv2,可以摄视频并生成比原始DINO质量更高的分割方法,可实现深度估计、语义分割和实例检索等功能。
据悉,DINOv2采用了一种新的高性能计算机视觉模型的方法,无需微调具备自我监督学习(SSL),可以从任何图像集合中学习。还可以学习当前标准方法无法学习的特征,例如,深度估计。
这使得DINOv2的应用范围非常广泛,例如,通过简单的指令和提示构建虚拟现实世界,这将加速元宇宙的构建效率;世界资源研究所通过DINOv2绘制森林地图。
开源地址:https://github.com/facebookresearch/dinov2
论文:https://arxiv.org/abs/2304.07193
演示地址:https://dinov2.metademolab.com/
演示视频
DINOv2简单介绍
从DINOv2发布的论文来看,无需微调自我监督学习是其一大技术亮点。自我监督学习与用于为文本应用程序创建顶级大型语言模型的方法相同,是一种强大、灵活的人工智能模型训练方法,无需大量标记数据即可完成。
DINOv2系列模型在自我监督学习方面比之前的最新技术有了显著改进 ,并达到了与弱监督特征 (WSL)相当的性能。
DINOv2的模型可以在任何图像集合上进行训练,而无需任何关联的元数据。可以视为能够从给定的所有图像中学习,而不仅仅是那些包含特定主题标签、替代文本或标题的图像。
DINOv2模型是在没有监督的情况下对1.42亿张图像的大型、精选和多样化数据集进行预训练的,并且生成的特征无需任何微调即可使用。
功能方面,DINOv2可用于深度估计、语义分割、实例检索等功能。
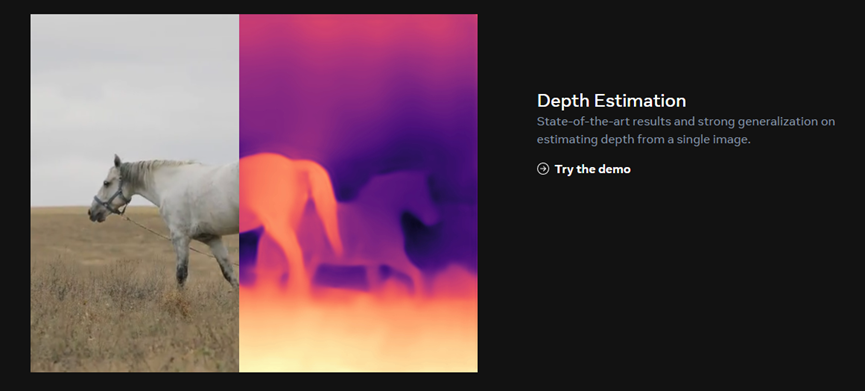
深度估计:从单个图像估计深度的最新结果和强大的泛化能力,例如,从单个图像预测每像素深度的模型。
语义分割:轻松预测单个图像中,每个像素对象类别的模型。

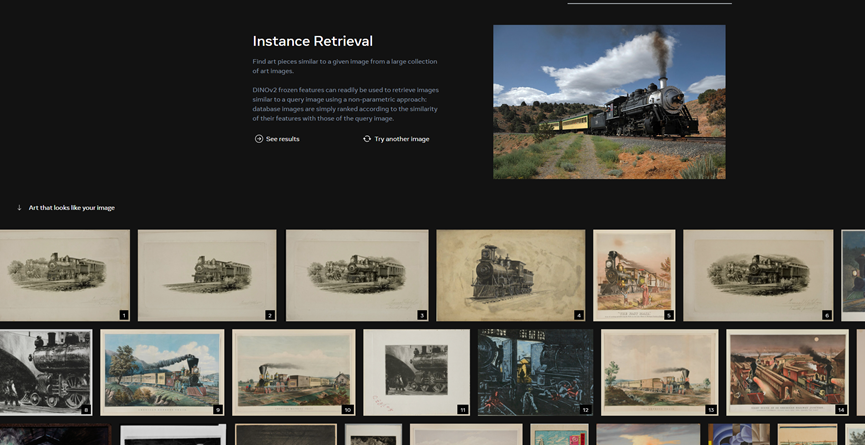
实例检索:从大量艺术图像中查找与给定图像相似的艺术作品。例如,选择一张火车的照片,系统会快速给出相类似的艺术照片,包括素描、老照片、漫画等风格。
克服图像文本预训练的局限性
近年来,一种称为“图像文本预训练”的技术已成为标准方法用于多种计算机视觉任务。但该方法依赖于手写说明来学习图像的语义内容,因此会忽略了那些未在文本描述中明确提及的重要信息。
例如,一张巨大的紫色房间里的椅子图片的标题可能是“单橡木椅”。然而,标题遗漏了有关背景的重要信息,例如,椅子在紫色房间中的空间位置。
因此,基于文本的特征描述缺乏对真实信息的正确理解,并可能导致需要详细本地化信息的下游任务表现不佳。而DINOv2具备自我监督学习功能,不依赖文本描述信息识别图像,同时DINOv2还能深度估计出最准确的结果。
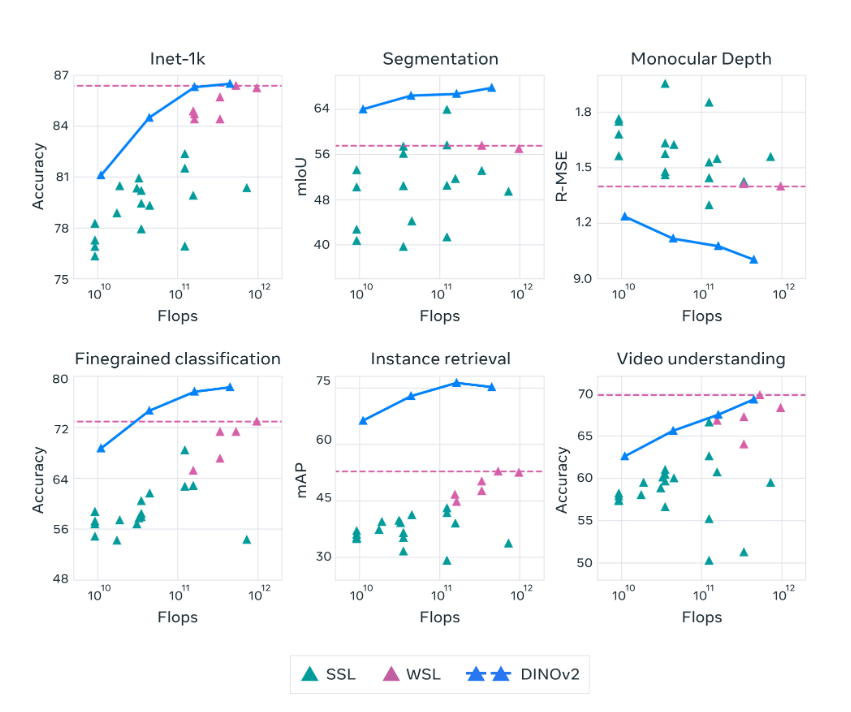
通常强大的模型需要大量算力提供支持,为了帮助开发者解决资源消耗的问题,DINOv2的训练算法基于自蒸馏,可以直接将大型模型压缩成较小的模型。
这个过程允许以最小的准确性成本将最高性能的架构压缩成更小的架构,从而显著降低算力成本。
本文素材来源Meta,如有侵权请联系删除
END

加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”
管理员审核后加入讨论群
本文来自AIGC开放社区