一定要「分词」吗?Andrej Karpathy:是时候抛弃这个历史包袱了
ChatGPT 等对话 AI 的出现让人们习惯了这样一件事情:输入一段文本、代码或一张图片,对话机器人就能给出你想要的答案。但在这种简单的交互方式背后,AI 模型要进行非常复杂的数据处理和运算,tokenization 就是比较常见的一种。在自然语言处理领域,tokenization 指的是将文本输入分割成更小的单元,称为「token」。这些 token 可以是词、子词或字符,取决于具体的分词策略和任务需求。例如,如果对句子「我喜欢吃苹果」执行 tokenization 操作,我们将得到一串 token 序列:["我", "喜欢", "吃", "苹果"]。有人将 tokenization 翻译成「分词」,但也有人认为这种翻译会引起误导,毕竟分割后的 token 未必是我们日常所理解的「词」。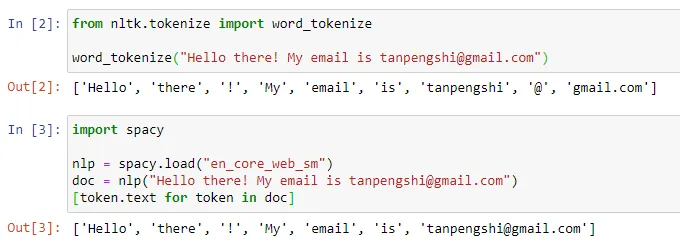
图源:https://towardsdatascience.com/dynamic-word-tokenization-with-regex-tokenizer-801ae839d1cdTokenization 的目的是将输入数据转换成计算机可以处理的形式,并为后续的模型训练和分析提供一种结构化的表示方式。这种方式为深度学习研究带来了便利,但同时也带来了很多麻烦。前段时间刚加入 OpenAI 的 Andrej Karpathy 指出了其中几种。首先,Karpathy 认为,Tokenization 引入了复杂性:通过使用 tokenization,语言模型并不是完全的端到端模型。它需要一个独立的阶段进行 tokenization,该阶段有自己的训练和推理过程,并需要额外的库。这增加了引入其他模态数据的复杂性。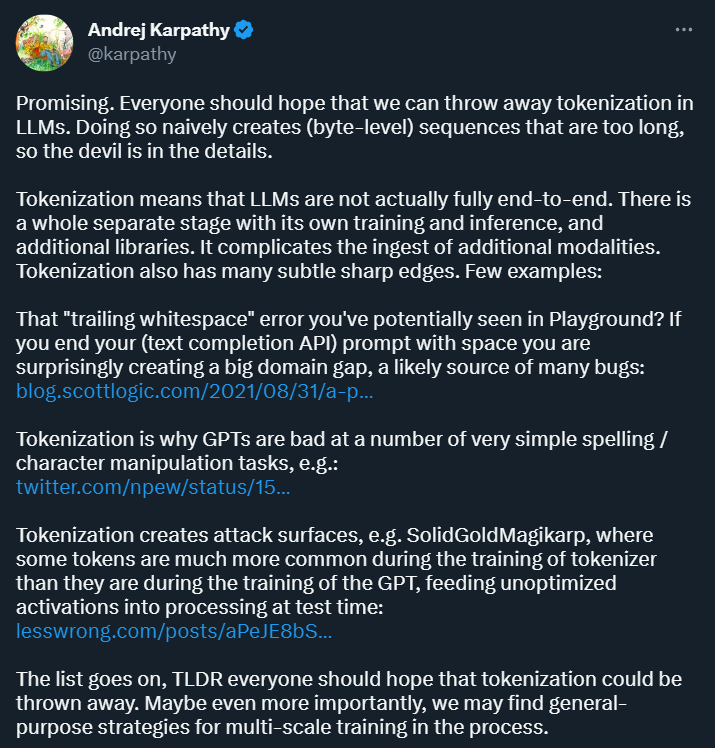
此外,tokenization 还会在某些场景下让模型变得很容易出错,比如在使用文本补全 API 时,如果你的 prompt 以空格结尾,你得到的结果可能大相径庭。
图源:https://blog.scottlogic.com/2021/08/31/a-primer-on-the-openai-api-1.html再比如,因为 tokenization 的存在,强大的 ChatGPT 竟然不会将单词反过来写(以下测试结果来自 GPT 3.5)。
这样的例子可能还有很多。Karpathy 认为,要解决这些问题,我们首先要抛弃 tokenization。Meta AI 发表的一篇新论文探讨了这个问题。具体来说,他们提出了一种名为「 MEGABYTE」的多尺度解码器架构,可以对超过一百万字节的序列进行端到端可微建模。
论文链接:https://arxiv.org/pdf/2305.07185.pdf重要的是,该论文展现出了抛弃 tokenization 的可行性,被 Karpathy 评价为「很有前途(Promising)」。在 机器学习的文章 中讲过,机器学习之所以看上去可以解决很多复杂的问题,是因为它把这些问题都转化为了数学问题。
而 NLP 也是相同的思路,文本都是一些「非结构化数据」,我们需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题了,而分词就是转化的第一步。由于自注意力机制和大型前馈网络的成本都比较高,大型 transformer 解码器 (LLM) 通常只使用数千个上下文 token。这严重限制了可以应用 LLM 的任务集。基于此,来自 Meta AI 的研究者提出了一种对长字节序列进行建模的新方法 ——MEGABYTE。该方法将字节序列分割成固定大小的 patch,和 token 类似。- patch 嵌入器,它通过无损地连接每个字节的嵌入来简单地编码 patch;
- 全局模块 —— 带有输入和输出 patch 表征的大型自回归 transformer;
- 局部模块 —— 一个小型自回归模型,可预测 patch 中的字节。
至关重要的是,该研究发现对许多任务来说,大多数字节都相对容易预测(例如,完成给定前几个字符的单词),这意味着没有必要对每个字节都使用大型神经网络,而是可以使用小得多的模型进行 intra-patch 建模。
MEGABYTE 架构对长序列建模的 Transformer 进行了三项主要改进: 1. sub-quadratic 自注意力。大多数关于长序列模型的工作都集中在减少自注意力的二次成本上。通过将长序列分解为两个较短的序列和最佳 patch 大小,MEGABYTE 将自注意力机制的成本降低到 ,即使是长序列也能易于处理。
,即使是长序列也能易于处理。
2. per-patch 前馈层。在 GPT-3 等超大模型中,超过 98% 的 FLOPS 用于计算 position-wise 前馈层。MEGABYTE 通过给 per-patch(而不是 per-position)使用大型前馈层,在相同的成本下实现了更大、更具表现力的模型。在 patch 大小为 P 的情况下,基线 transformer 将使用具有 m 个参数的相同前馈层 P 次,而 MEGABYTE 仅需以相同的成本使用具有 mP 个参数的层一次。3. 并行解码。transformer 必须在生成期间串行执行所有计算,因为每个时间步的输入是前一个时间步的输出。通过并行生成 patch 的表征,MEGABYTE 在生成过程中实现了更大的并行性。例如,具有 1.5B 参数的 MEGABYTE 模型生成序列的速度比标准的 350M 参数 transformer 快 40%,同时在使用相同的计算进行训练时还改善了困惑度(perplexity)。总的来说,MEGABYTE 让我们能够以相同的计算预算训练更大、性能更好的模型,将能够处理非常长的序列,并提高部署期间的生成速度。MEGABYTE 还与现有的自回归模型形成鲜明对比,后者通常使用某种形式的 tokenization,其中字节序列被映射成更大的离散 token(Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021) 。tokenization 使预处理、多模态建模和迁移到新领域变得复杂,同时隐藏了模型中有用的结构。这意味着大多数 SOTA 模型并不是真正的端到端模型。最广泛使用的 tokenization 方法需要使用特定于语言的启发式方法(Radford et al., 2019)或丢失信息(Ramesh et al., 2021)。因此,用高效和高性能的字节模型代替 tokenization 将具有许多优势。该研究对 MEGABYTE 和一些强大的基线模型进行了实验。实验结果表明,MEGABYTE 在长上下文语言建模上的性能可与子词模型媲美,并在 ImageNet 上实现了 SOTA 的密度估计困惑度,并允许从原始音频文件进行音频建模。这些实验结果证明了大规模无 tokenization 自回归序列建模的可行性。
大小为 P 的 patch 嵌入器能够将字节序列 映射成一个长度为
映射成一个长度为 、维度为
、维度为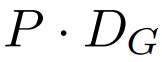 的 patch 嵌入序列。
的 patch 嵌入序列。
首先,每个字节都嵌入了一个查找表 ,形成一个大小为 D_G 的嵌入,并添加了位置嵌入。
,形成一个大小为 D_G 的嵌入,并添加了位置嵌入。
然后,字节嵌入被重塑成维度为的 K 个 patch 嵌入的序列。为了允许自回归建模,该 patch 序列被填充以从可训练的 patch 大小的填充嵌入(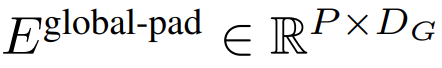 ),然后从输入中移除最后一个 patch。该序列是全局模型的输入,表示为
),然后从输入中移除最后一个 patch。该序列是全局模型的输入,表示为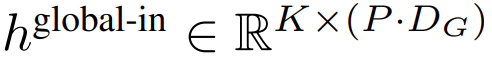 。
。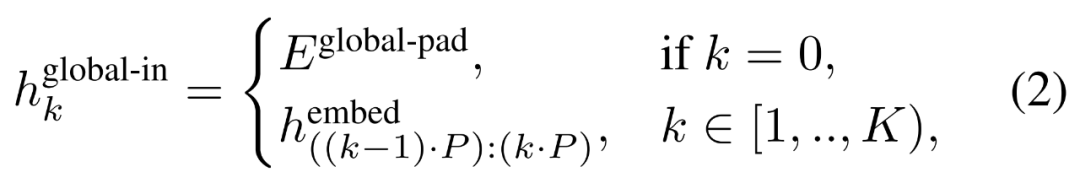
全局模块是一个 decoder-only 架构的 P・D_G 维 transformer 模型,它在 k 个 patch 序列上进行操作。全局模块结合自注意力机制和因果掩码来捕获 patch 之间的依赖性。全局模块输入 k 个 patch 序列的表示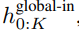 ,并通过对先前 patch 执行自注意力来输出更新的表示
,并通过对先前 patch 执行自注意力来输出更新的表示 。
。
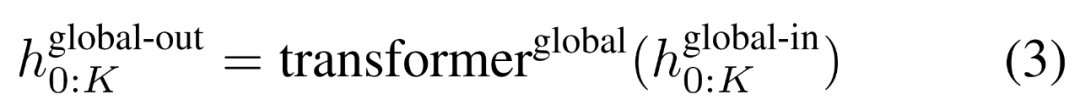
最终全局模块的输出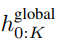 包含 P・D_G 维的 K 个 patch 表示。对于其中的每一个,研究者将它们重塑维长度为 P、维度为 D_G 的序列,其中位置 p 使用维度 p・D_G to (p + 1)・D_G。然后将每个位置映射到具有矩阵
包含 P・D_G 维的 K 个 patch 表示。对于其中的每一个,研究者将它们重塑维长度为 P、维度为 D_G 的序列,其中位置 p 使用维度 p・D_G to (p + 1)・D_G。然后将每个位置映射到具有矩阵 的局部模块维度,其中 D_L 为局部模块维度。接着将这些与大小为 D_L 的字节嵌入相结合,用于下一个
的局部模块维度,其中 D_L 为局部模块维度。接着将这些与大小为 D_L 的字节嵌入相结合,用于下一个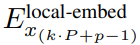 的 token。
的 token。
局部字节嵌入通过可训练的局部填充嵌入(E^local-pad ∈ R^DL)偏移 1,从而允许在 path 中进行自回归建模。最终得到张量

局部模块是一个较小的、decoder-only 架构的 D_L 维 transformer 模型,它在包含 P 个元素的单个 patch k 上运行,每个元素又是一个全局模块输出和序列中前一个字节的嵌入的总和。K 个局部模块副本在每个 patch 上独立运行,并在训练时并行运行,从而计算表示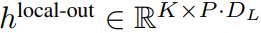 。
。

最后,研究者可以计算每个位置的词汇概率分布。第 k 个 patch 的第 p 个元素对应于完整序列的元素 t,其中 t = k・P + p。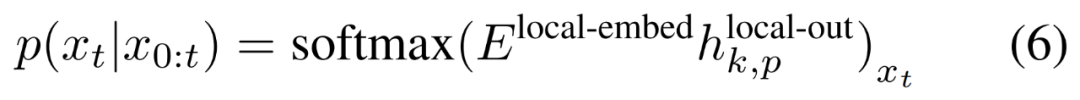
在缩放序列长度和模型大小时,研究者分析了不同架构的成本。如下图 3 所示,MEGABYTE 架构在各种模型大小和序列长度上使用的 FLOPS 少于同等大小的 transformer 和线性 transformer,允许相同的计算成本下使用更大的模型。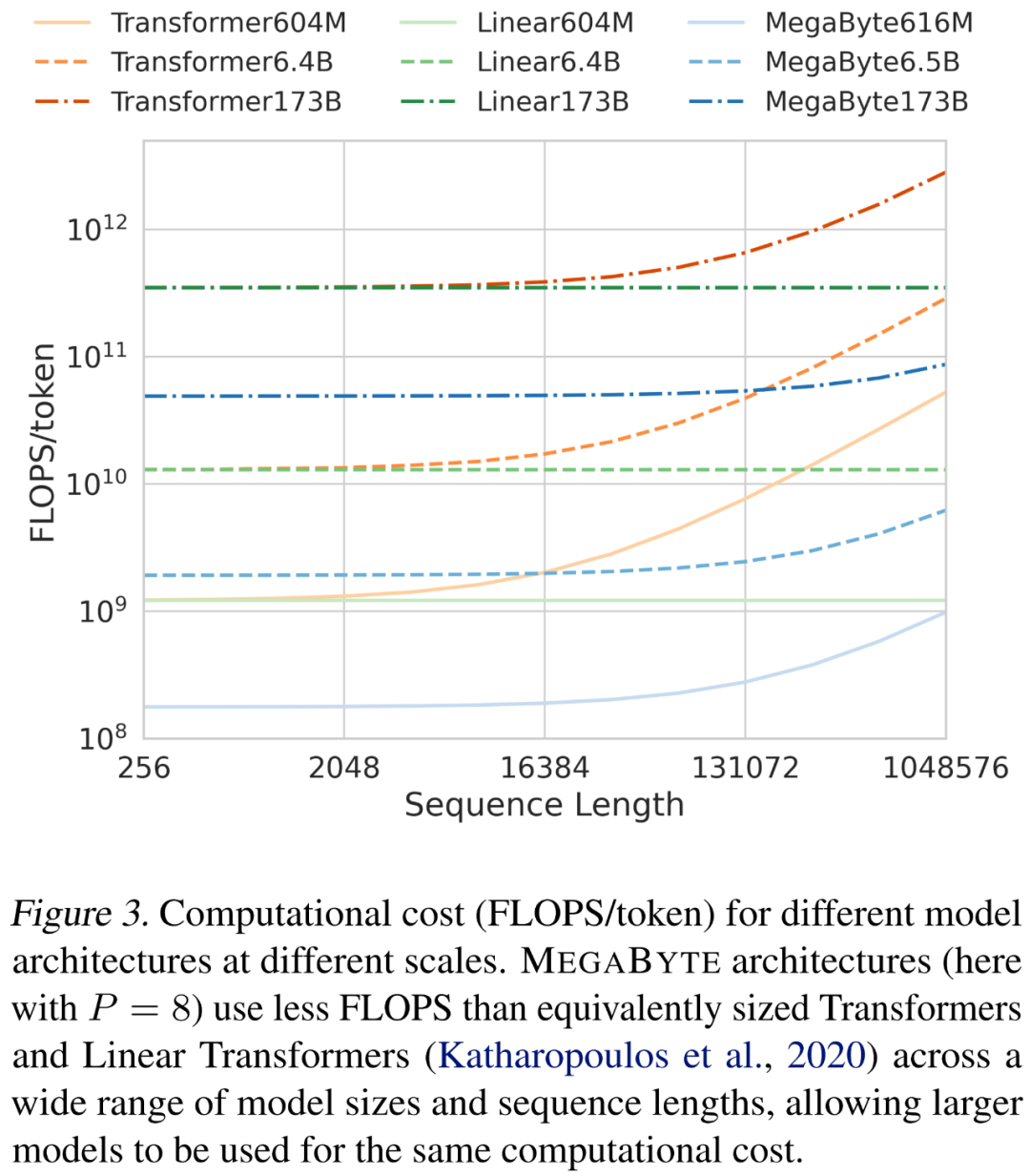
考虑这样一个 MEGABYTE 模型,它在全局模型中有 L_global 层,在局部模块中有 L_local 层,patch 大小为 P,并与具有 L_local + L_global 层的 transformer 架构进行比较。用 MEGABYTE 生成每个 patch 需要一个 O (L_global + P・L_local) 串行操作序列。当 L_global ≥ L_local(全局模块的层多于局部模块)时,MEGABYTE 可以将推理成本降低近 P 倍。研究者在强调长程依赖的 5 个不同数据集上分别评估了 MEGABYTE 的语言建模功能,它们是 Project Gutenberg (PG-19)、Books、Stories、arXiv 和 Code。结果如下表 7 所示,MEGABYTE 在所有数据集上的表现始终优于基线 transformer 和 PerceiverAR 。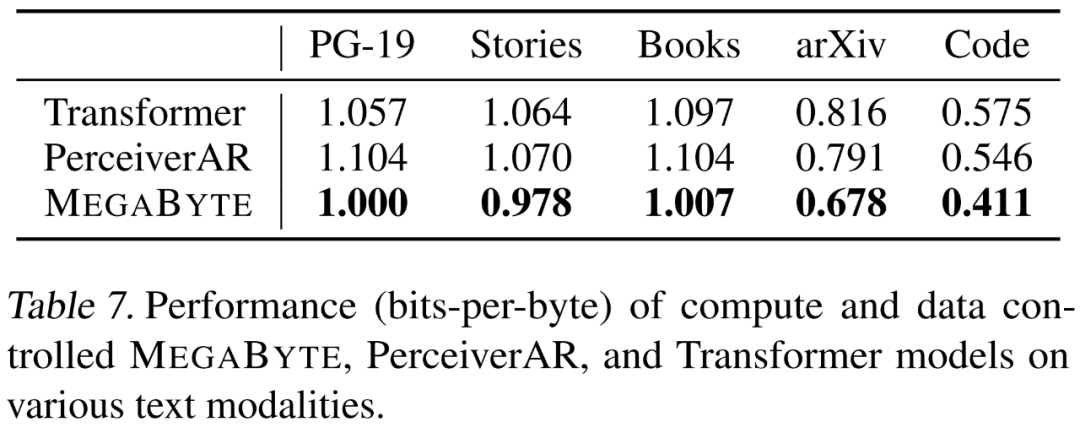
研究者还扩展了在 PG-19 上的训练数据,结果如下表 8 所示,MEGABYTE 显著优于其他字节模型,并可与子词(subword)上训练的 SOTA 模型相媲美。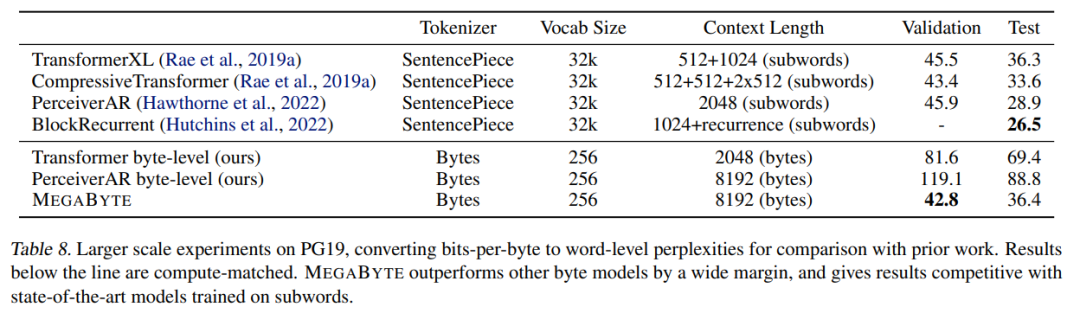
研究者在 ImageNet 64x64 数据集上训练了一个大型 MEGABYTE 模型,其中全局和局部模块的参数分别为 2.7B 和 350M,并有 1.4T token。他们估计,训练该模型所用时间少于「Hawthorne et al., 2022」论文中复现最佳 PerceiverAR 模型所需 GPU 小时数的一半。如上表 8 所示,MEGABYTE 与 PerceiverAR 的 SOTA 性能相当的同时,仅用了后者一半的计算量。研究者比较了三种 transformer 变体,即 vanilla、PerceiverAR 和 MEGABYTE,以测试在越来越大图像分辨率上长序列的可扩展性。结果如下表 5 所示,在这一计算控制设置下,MEGABYTE 在所有分辨率上均优于基线模型。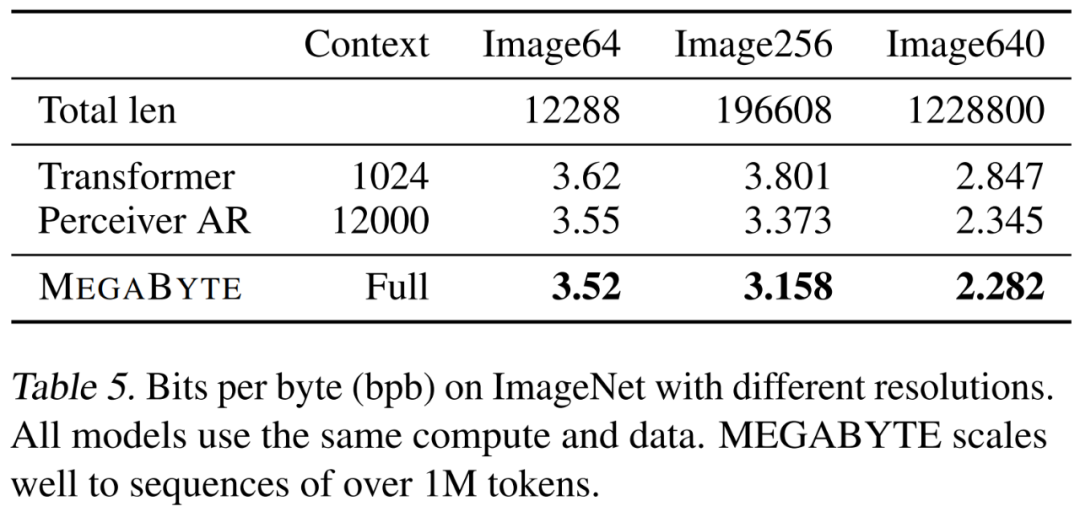
下表 14 总结了每个基线模型使用的精确设置,包括上下文长度和 latent 数量。
音频兼具文本的序列结构和图像的连续属性,这对 MEGABYTE 而言是一个有趣的应用。本文模型获得 3.477 的 bpb,明显低于 perceiverAR(3.543)和 vanilla transformer 模型(3.567)。更多消融结果详见下表 10。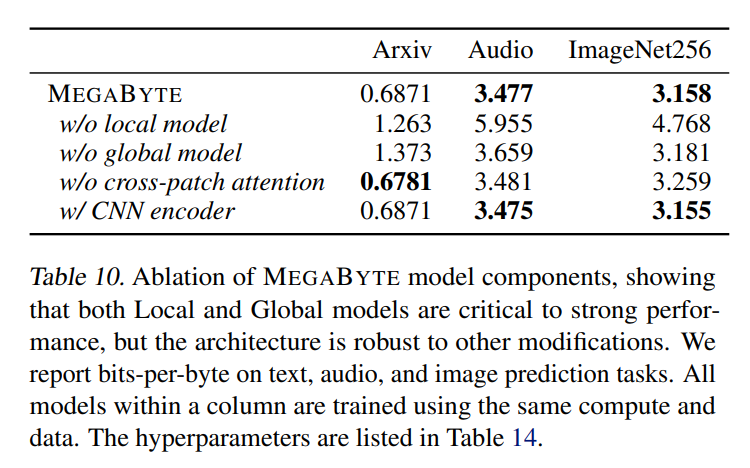

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com