点击下方👇👇公众号卡片:程序员老鬼,回复关键字:chatgpt 获取插件安装文件和ChatGPT资料合集
GPT Crawler是一个开源项目,它通过简单配置,能够自动抓取网页文本信息,生成文本文件。这些文件可以上传至OpenAI,用于自定义Assistant,实现多种集成应用。本文将详细介绍如何使用GPT Crawler,包括安装、配置、启动爬虫,并结合OpenAI进行应用。
安装教程
克隆仓库
首先,需要安装Node.js(版本≥16),然后执行以下命令以克隆GPT Crawler仓库:
安装依赖
npm inpx playwright install
配置爬虫
GPT Crawler的核心在于配置,主要包括目标网站的起始网址、继续抓取的页面链接的URL规则、以及页面中提取文本信息的CSS选择器。配置CSS选择器
以下是一个示例配置,用于抓取阮一峰老师的TypeScript教程:export const config: Config = { url: "https://wangdoc.com/typescript/", match: "https://wangdoc.com/typescript/**", selector: `body > section > div > div:nth-child(1) > div.column.is-8.is-6-widescreen.is-offset-1-widescreen > article`, maxPagesToCrawl: 50, outputFileName: "output1.json",};
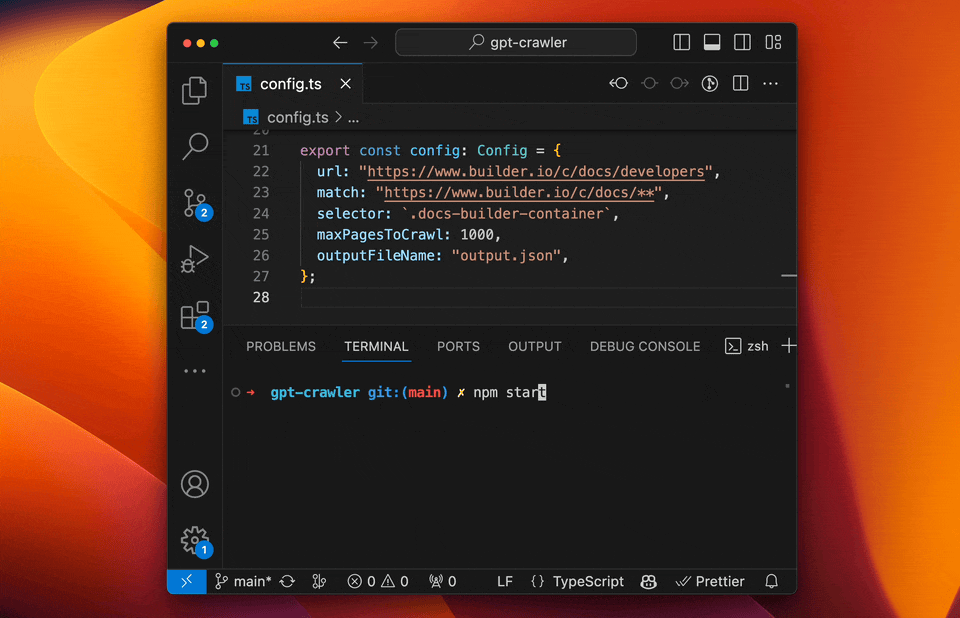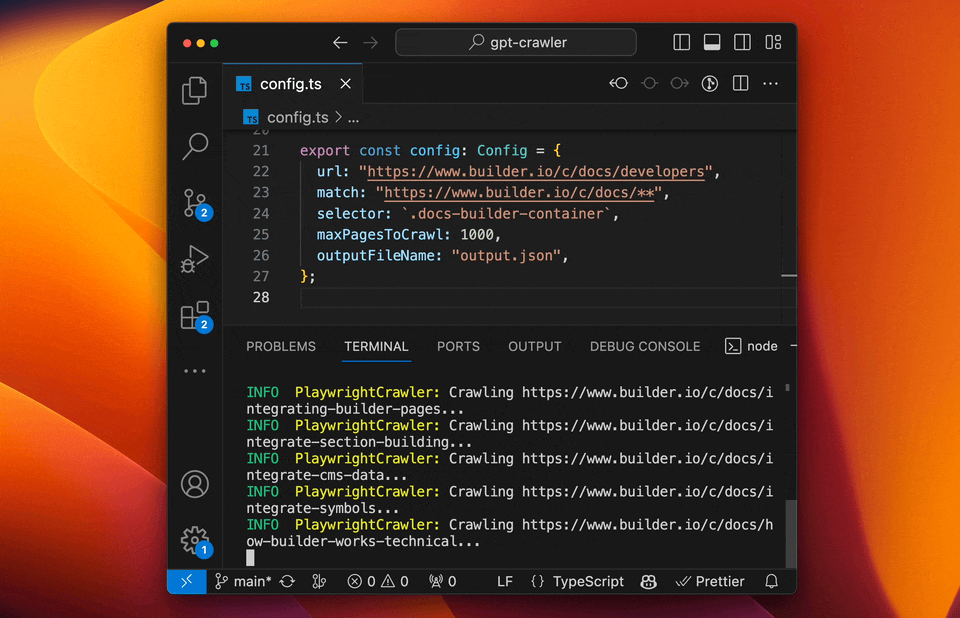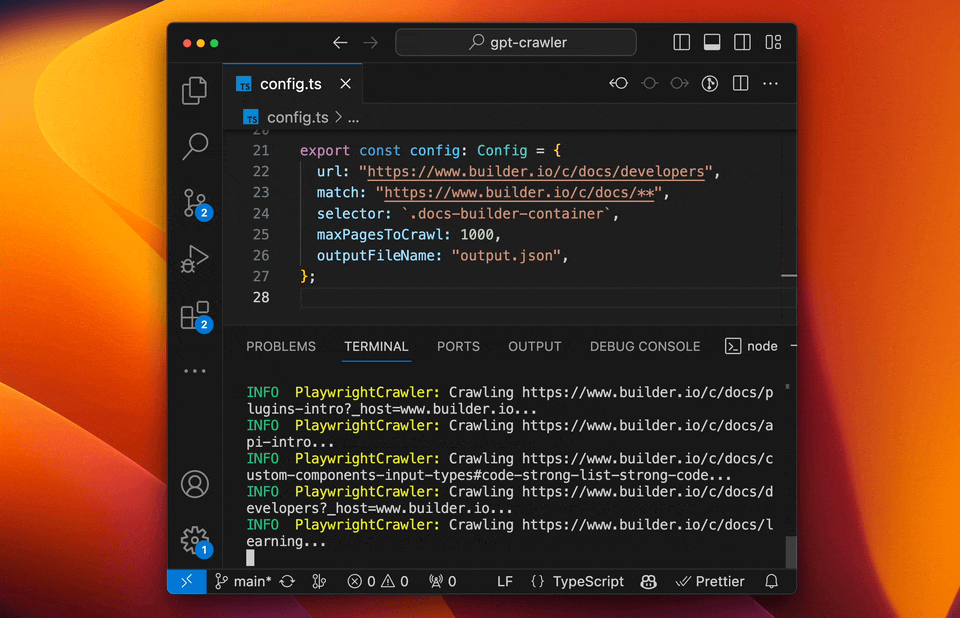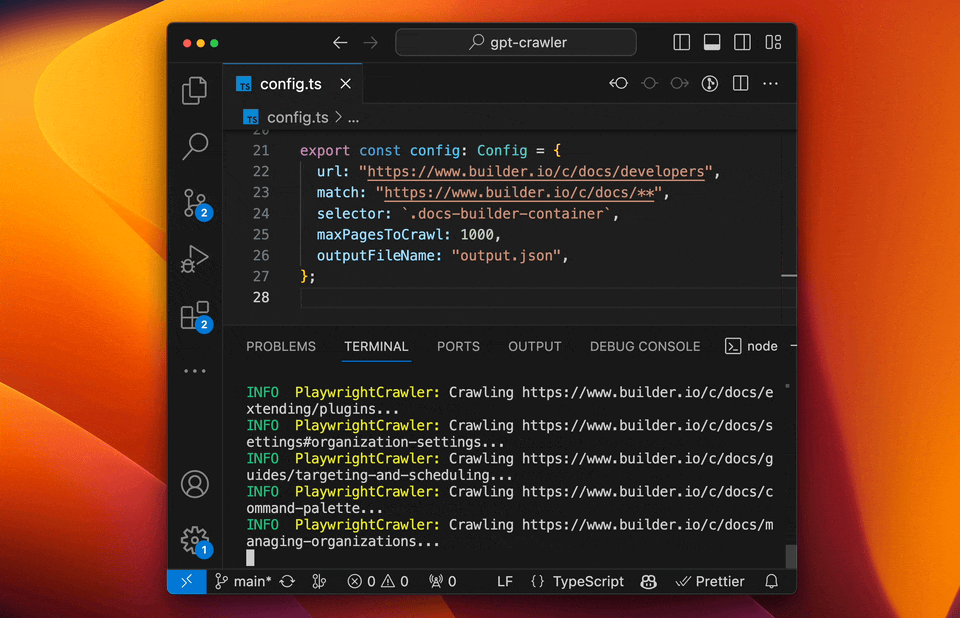
启动爬虫
程序将在项目根目录生成output.json文件。
结合OpenAI
要将生成的文本文件用于自定义Assistant,首先需要一个OpenAI账户。上传output.json文件至OpenAI后,可以创建一个Assistant,并通过OpenAI的API集成至自己的系统。实际案例
以创建一个自定义Assistant为例,操作步骤如下:- 访问OpenAI的自定义Assistants页面。
完成以上步骤后,就可以开始测试Assistant了。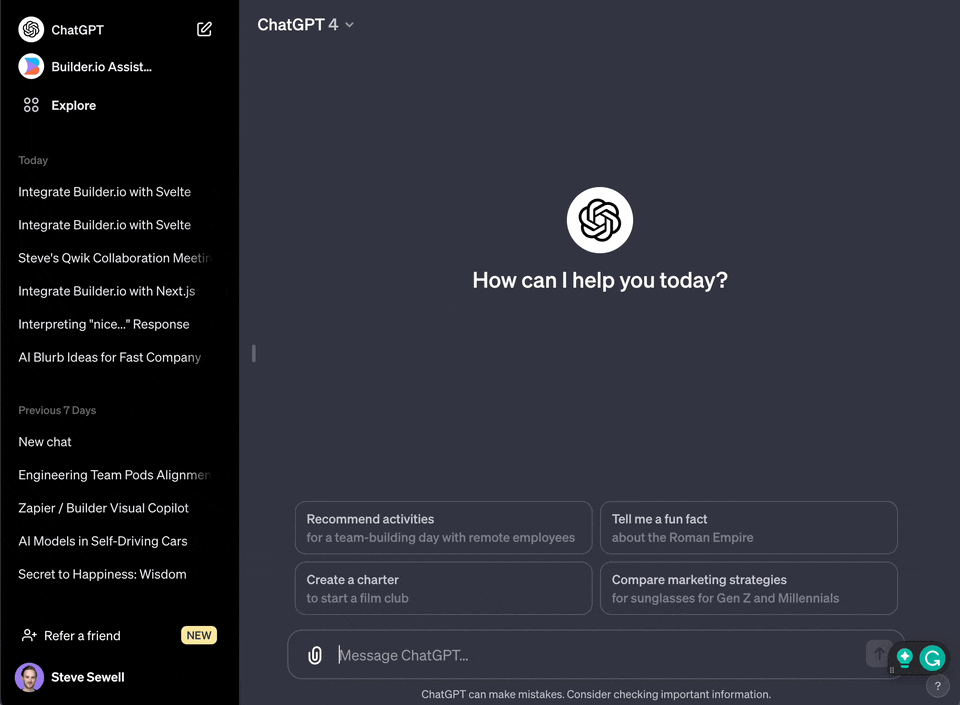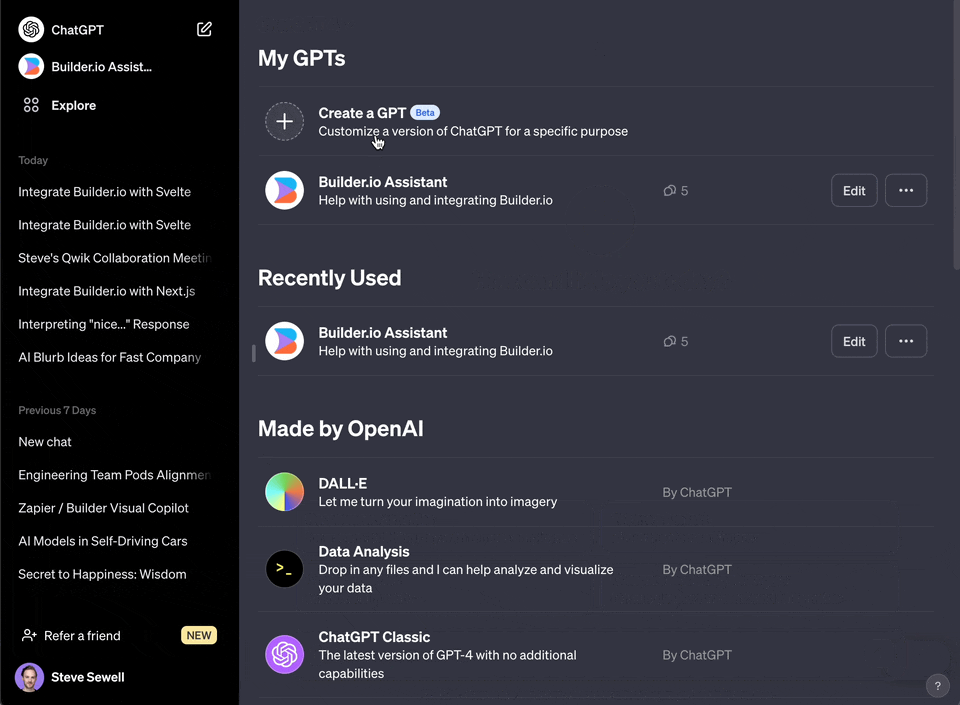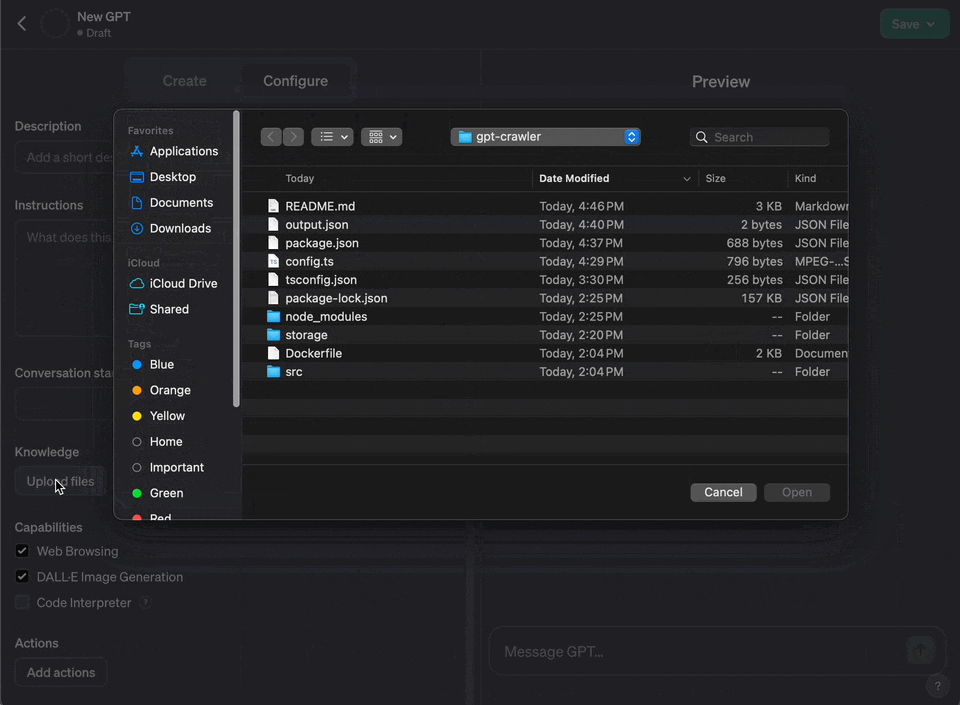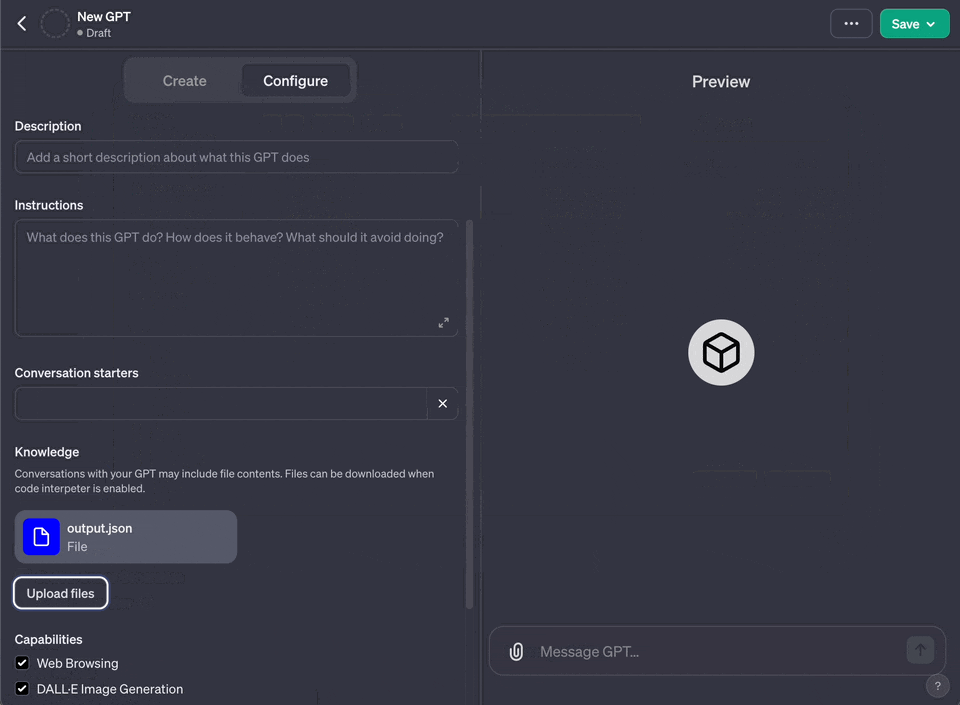
结论
GPT Crawler是一个功能强大且易于使用的工具,可以快速从网页抓取文本信息,为自定义AI Assistant提供知识库。通过结合OpenAI的API,可以实现多种创新应用,如自动化客服、个性化信息提供等。这个项目为开发者提供了一个简便的方式来扩展和定制他们的AI应用,是值得探索和利用的资源。
扫描下方二维码,购买《ChatGPT实战课程》,送ChatGPT独享账号!
课程包含超多ChatGPT前沿玩法,帮助大家熟练掌握ChatGPT!

推荐阅读:
1.微信聊天内容可以被监听吗
2.GPTs商店应用测评 - CK-12 Flexi
3.程序员帮捉Bug却被判罚2.3万元。。。