- 长臂猿-企业应用及系统软件平台

01
FATE v1.11版本发布,集成首个开源联邦大模型FATE-LLM

基于此技术方案,多个企业可以通过FATE内置的预训练模型如GPT-2进行横向联邦,利用各自隐私数据进行联邦大模型微调。过程中使用了安全聚合(Secure Aggregation)机制对各家模型数据进行保护。相对单一企业有限训练样本,通过联邦大模型技术综合多家的训练样本,可以显著提升模型效果和稳健性。经过实践测试,FATE-LLM可以支持至少30家参与方同时进行横向联邦。
02
为什么要做联邦大模型
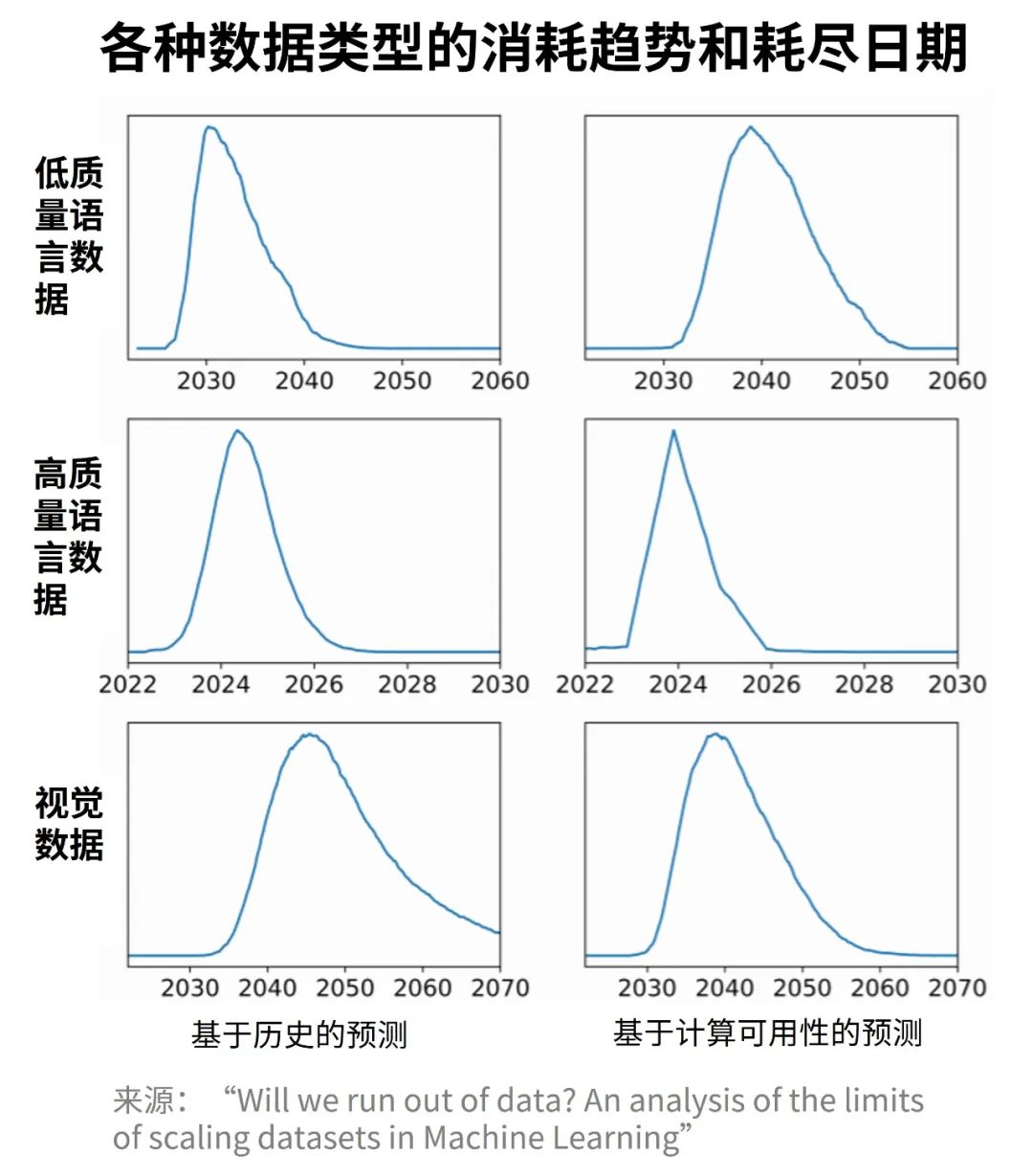
FATE开源社区技术指导委员会主席杨强教授表示:“FATE-LLM的开源,是为了解决当前大模型应用的两个瓶颈问题。首先,是构建和使用大模型时的数据隐私保护问题。多个数据源联合训练一个大模型时极有可能会暴露每个数据源的用户隐私和影响信息安全,再一次凸显了隐私保护的必要性和紧迫性。
03
FATEv1.11功能介绍
1) LLM支持:
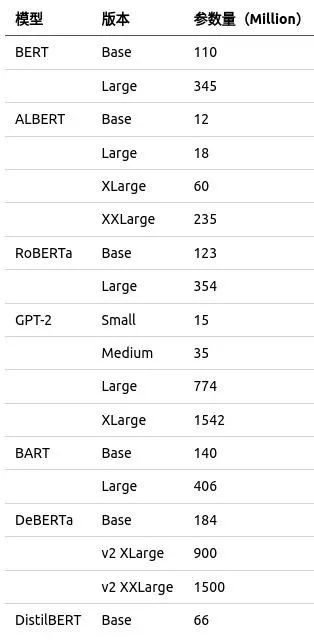
大模型:LLM支持多种大型自然语言处理模型,包括BERT,ALBERT,RoBERTa,GPT-2,BART,DeBERTa,DistillBERT等。这些模型被广泛应用于自然语言理解和生成任务,可以满足不同应用场景下的需求。
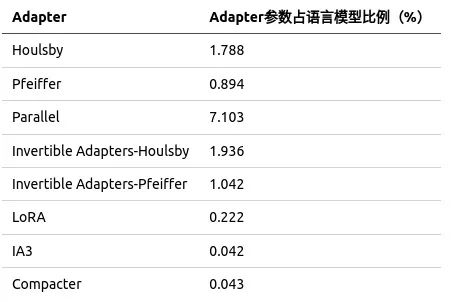
Adapter:LLM还支持多种适配器方案,包括Bottleneck Adapters(包括Houlsby、Pfeiffer和Parallel方案)、Invertible Adapters、LoRA、IA3和Compacter等。这些方案可以帮助用户在保持模型精度的同时,大幅度减少模型参数量,提高联邦训练效率。
2)Homo Trainer类改进:LLM的Homo Trainer类得到了进一步的改进,用户现在可以指定添加CUDA设备进行训练,并且可以通过多GPU设备使用Data Parallel来加速训练。
3)Tokenizer Dataset功能升级:LLM的Tokenizer Dataset功能也得到了升级,现在更好地适配了HuggingFace Tokenizer的使用,可以更加高效地处理自然语言文本数据。
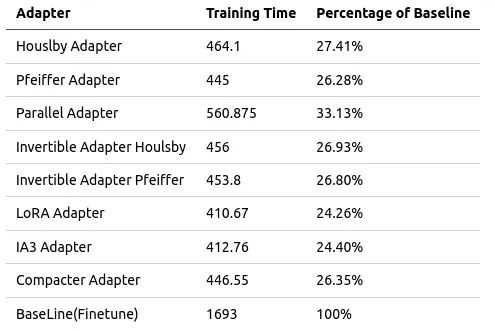
3) 训练时间对比
场景:横向联邦场景
任务类型:文本情感分类任务
参与方:两个参与建模方,一个聚合服务方
数据:IMDB数据集,数据量大小=25000,batch_size=64, padding_length=200
环境:各个建模方使用V100 32GB x 2,局域网环境
以下是使用各个adapter的训练时间,与使用完整模型finetune的训练时间的对比(每个epoch训练时间,单位为秒)。可见,adapter + 语言模型的联邦形式,可以极大地节省训练时间。
04
开源开放,大模型发展的必经之路
FATE v.1.11为联邦大模型初步版本,未来FATE开源社区还将针对联邦大模型的算法、效率、安全等方面进行持续优化,并持续推出后续版本,路线图如下:
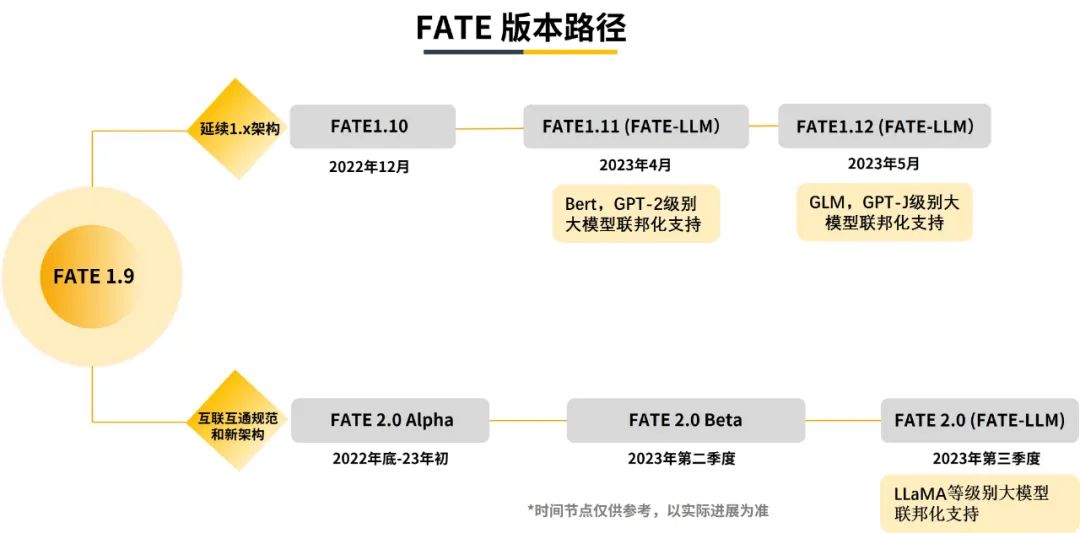
参考资料:
您可以通过以下方式联系FATE开源社区: | |
官网: | https://fedai.org/ |
Github: | https://github.com/FederatedAI/FATE |
公众号: | FATE开源社区 |
开源社区用户组: | Fate-FedAI@groups.io |
开源社区维护者: | FedAI-maintainers@groups.io |
开发专委会: | fate-dev-core@groups.io |
运营专委会: | FATE-operation@groups.io |
安全专委会: | FATE-security@groups.io |
欢迎加入FATE联邦学习官方交流群,添加FATE小助手微信号(FATEZS001)即可。
END
【github直达】:阅读原文或复制链接https://github.com/FederatedAI/FATE即可,点击star,方便下次使用。

本文来自AI前线